Битовые операции
Во многих языках программирования допустимы логические операции над битами целых чисел. В отличие от обычных логических операций, результатом выполнения которых является логический тип данных, битовые логические операции просто изменяют целое число согласно определенным правилам. Точнее битовые операции изменяют отдельные биты двоичного представления числа, в результате чего изменяется его десятичное значение.
Например, в языке программирования Паскаль обычные логические операции и логические операции над битами обозначают с помощью одних и тех же ключевых слов: not, and, or, xor . Компилятор определяет, что имелось в виду в зависимости от контекста использования этих слов. Обычные логические операции объединяют два и более простых логических выражения. Например, (a > 0) and (c != b) , (c < a) or(not b) и т.п. В свою очередь побитовые логические операции выполняются исключительно над целыми числами (или переменными, которые их содержат). Например, a and b, a or 8, not 247 .
Как понять побитовые операции
1. Переведем пару произвольных целых чисел до 256 (один байт) в двоичное представление.
2. Теперь расположим биты второго числа под соответствующими битами первого и выполним обычные логические операции к цифрам, стоящим в одинаковых разрядах первого и второго числа. Например, если в последнем (младшем) разряде одного числа стоит 1, а другого числа — 0, то логическая операция and вернет 0, а or вернет 1. Операцию not применим только к первому числу.
3. Переведем результат в десятичную систему счисления.
4. Итак, в результате побитовых логических операций получилось следующее:
Вот еще один пример выполнения логических операций над битами. Проверьте его правильность самостоятельно.
Зачем нужны побитовые логические операции
Глядя на результат побитовых операций, не сразу можно уловить закономерности в их результате. Поэтому непонятно, зачем нужны такие операции. Однако, они находят свое применение. В байтах не всегда хранятся числа. Байт или ячейка памяти может хранить набор флагов (установлен — сброшен), представляющих собой информацию о состоянии чего-либо. С помощью битовых логических операций можно проверить, какие биты в байте установлены в единицу, можно обнулить биты или, наоборот, установить в единицу. Также существует возможность сменить значения битов на противоположные.
Проверка битов
Проверка битов осуществляется с помощью битовой логической операции and .
Представим, что имеется байт памяти с неизвестным нам содержимым. Известно, что логическая операция and возвращает 1, если только оба операнда содержат 1. Если к неизвестному числу применить побитовое логическое умножение (операцию and ) на число 255 (что в двоичном представлении 1111 1111), то в результате мы получим неизвестное число. Обнулятся те единицы двоичного представления числа 255, которые будут умножены на разряды неизвестного числа, содержащие 0. Например, пусть неизвестное число 38 (0010 0110), тогда проверка битов будет выглядеть так:
Другими словами, x and 255 = x .
Обнуление битов
Чтобы обнулить какой-либо бит числа, нужно его логически умножить на 0.
Обратим внимание на следующее:
Т.е. чтобы обнулить четвертый с конца бит числа x , надо его логически умножить на 247 или на (255 — 23).
Установка битов в единицу
Для установки битов в единицу используется побитовая логическая операция or . Если мы логически сложим двоичное представление числа x с 0000 0000, то получим само число х . Но вот если мы в каком-нибудь бите второго слагаемого напишем единицу, то в результате в этом бите будет стоять единица.
Отметим также, что:
Поэтому, например, чтобы установить второй по старшинству бит числа x в единицу, надо его логически сложить с 64 ( x or 64 ).
Смена значений битов
Для смены значений битов на противоположные используется битовая операция xor . Чтобы инвертировать определенный бит числа x , в такой же по разряду бит второго числа записывают единицу. Если же требуется инвертировать все биты числа x , то используют побитовую операцию исключающего ИЛИ ( xor ) с числом 255 (1111 1111).
Операции побитового циклического сдвига
Помимо побитовых логических операций во многих языках программирования предусмотрены битовые операции циклического сдвига влево или вправо. Например, в языке программирования Паскаль эти операции обозначаются shl (сдвиг влево) и shr (сдвиг вправо).
Первым операндом операций сдвига служит целое число, над которым выполняется операция. Во втором операнде указывается, на сколько позиций сдвигаются биты первого числа влево или вправо. Например, 105 shl 3 или 105 shr 4 . Число 105 в двоичном представлении имеет вид 0110 1001.
При сдвиге влево теряются старшие биты исходного числа, на их место становятся младшие. Освободившиеся младшие разряды заполняются нулями.
При сдвиге вправо теряются младшие биты исходного числа, на их место становятся старшие. Освободившиеся старшие разряды заполняются нулями, если исходное число было положительным.
Битовое представление чисел
Так как на уровне схем почти вся логика бинарная, ровно такое представление и используется для хранения чисел в компьютерах: каждая целочисленная переменная указывает на какую-то ячейку из 8 ( char ), 16 ( short ), 32 ( int ) или 64 ( long long ) бит.
#Эндианность
Единственная неоднозначность в таком формате возникает с порядком хранения битов — также называемый эндианностью. Зависимости от архитектуры он может быть разным:
- При схеме little-endian сначала идут младшие биты. Например, число $42_<10>$ будет храниться так: $010101$.
- При записи в формате big-endian сначала идут старшие биты. Все примеры из начала статьи даны в big-endian формате.
Хотя big-endian более естественный для понимания — на бумаге мы ровно так обычно и записываем бинарные числа — по разным причинам на большинстве современных процессоров по умолчанию используется little endian.
Иными словами, «$i$-тый бит» означает «$i$-тый младший» или «$i$-тый справа», но на бумаге мы ничего не инвертируем и записываем двоичные числа стандартным образом.
#Битовые операции
Помимо арифметических операций, с числами можно делать и битовые, которые интерпретируют их просто как последовательность битов.
#Сдвиги
Битовую запись числа можно «сдвигать» влево ( x << y ) или вправо ( x >> y ), что эквивалентно умножению или делению на степень двойки с округлением вниз.
Обычное умножение и деление — не самые быстрые операции, однако все битовые сдвиги всегда работают ровно за один такт. Как следствие, умножение и деление на какую-то фиксированную степень двойки всегда работает быстро — даже если вы не используете сдвиги явно, компилятор скорее всего будет проводить подобную оптимизацию.
#Побитовые операции
Помимо && , || и ! , существуют их побитовые версии, которые применяют соответствующую логическую операцию к целым последовательностям битов: & , | ,
Также помимо них есть ещё операция исключающего «или» (XOR), которая записывается как ^ .
- $13$ & $7$ = $1101_2$ & $0111_2$ = $0101_2$ = $5$
- $17$ | $10$ = $10001_2$ | $01010_2$ = $11011_2$ = $27$
- $17$ ^ $9$ = $10001_2$ ^ $01001_2$ = $11000_2$ = $24$
Все побитовые операции тоже работают за один такт, вне зависимости от типа данных. Для больших не вмещающихся в один регистр битовых последовательностей существует битсет.
#Маски
Бинарные последовательности можно поставить в соответствие подмножествам какого-то фиксированного множества: если на $i$-той позиции стоит единица, то значит $i$-тый элемент входит множество, а иначе не входит.
Битовые операции таким образом часто используются операций над множествами, представляемыми битовыми мазками — например, в задачах на полный перебор или динамическое программирование.
#Выделить i-й бит числа
(x >> i) & 1 или x & (1 << i) . Во втором случае результат будет либо 0, либо $2^i$.
Это часто используется для проверки, принадлежит ли $i$-тый элемент множеству:
Напомним, что нумерация идет с младших бит и начинается с нуля.
#Получить число, состоящее из k единиц
(1 << k) — 1 , также известное как $(2^k-1)$ и соответствующее маске полного множества.
#Инвертировать все биты числа
#Добавить i-й элемент в множество
#Удалить $i$-й элемент из множества
#Удалить i-й элемент из множества, если он есть
Также добавляет этот элемент, если его нет.
#Знаковые числа
Целочисленные переменные делятся на два типа — знаковые (signed) и беззнаковые (unsigned).
Если сложить две unsigned int переменные, сумма которых превосходит $2^<32>$, произойдет переполнение: сумму нельзя будет представить точно, и поэтому вместо неё результатом будут только нижние 32 бит. Все операции с беззнаковыми числами как бы проходят по модулю какой-то степени двойки.
Знаковые же типы нужны для хранения значений, которые могут быть и отрицательными. Для этого нужно выделить один бит для хранение знака — отрицательное ли число или нет — немного пожертвовав верхней границей представимых чисел: теперь самое большое представимое число это $2^<31>-1$, а не $2^<32>-1$.
Инженеры, которые работают над процессорами, ещё более ленивые, чем программисты — это мотивировано не только стремлением к упрощению, но и экономией транзисторов. Поэтому когда в signed типах происходит переполнение, результат в битовом представлении считается так же, как и в случае с unsigned числами. Если мы хотим ничего не менять в плане того, как работают unsigned числа, представление отрицательных чисел должно быть таким, что число $-x$ как бы вычитается из большой степени двойки:
- Все неотрицательные числа записываются в точности как раньше.
- У всех отрицательных чисел самый большой бит будет единичным.
- Если прибавить к $2^<31>-1$ единицу, то результатом будет $-2^<31>$, представляемое как 10000000 (в целях изложения мы будем записывать 8 бит, хотя в int их 32).
- Зная двоичную запись положительного числа x , запись -x можно получить как
Упражнение. Каких чисел больше: положительных или отрицательных?
Осторожно. В стандарте C/C++ прописано, что переполнение знаковых переменных приводит к undefined behavior, поэтому полагаться на описанную логику переполнения нельзя, хотя равно это скорее всего и произойдет.
#128-битные числа
Общих регистров размера больше 64 в процессорах нет, однако умножение и несколько смежных инструкций могут использовать два последовательных регистра как один большой. Это позволяет быстро перемножать два 64-битных числа и получать 128-битный результат, разделенный на нижние биты и верхние.
Это весьма специфичная операция, и поэтому в языках программирования нет полноценной поддержки 128-битных переменных. В C++ однако есть «костыль» — тип __int128_t — который фактически просто оборачивает пару из двух 64-битных регистров и поддерживает арифметические операции с ними.
Базовые арифметические операции с ним чуть медленнее, его нельзя напрямую печатать, и деление и прочие сложные операции будут вызывать отдельную библиотеку и поэтому работать очень долго, однако в некоторых ситуациях он оказывается очень полезен.
О битовых операциях
В этой статье я расскажу вам о том, как работают битовые операции. С первого взгляда они могут показаться вам чем-то сложным и бесполезным, но на самом деле это совсем не так. В этом я и попытаюсь вас убедить.
Введение
Побитовые операторы проводят операции непосредственно на битах числа, поэтому числа в примерах будут в двоичной системе счисления.
Я расскажу о следующих побитовых операторах:
- | (Побитовое ИЛИ (OR)),
- & (Побитовое И (AND)),
- ^ (Исключающее ИЛИ (XOR)),
Битовые операции изучаются в дискретной математике, а также лежат в основе цифровой техники, так как на них основана логика работы логических вентилей — базовых элементов цифровых схем. В дискретной математике, как и в цифровой технике, для описания их работы используются таблицы истинности. Таблицы истинности, как мне кажется, значительно облегчают понимание битовых операций, поэтому я приведу их в этой статье. Их, тем не менее, почти не используют в объяснениях побитовых операторов высокоуровневых языков программирования.
О битовых операторах вам также необходимо знать:
- Некоторые побитовые операторы похожи на операторы, с которыми вы наверняка знакомы (&&, ||). Это потому, что они на самом деле в чем-то похожи. Тем не менее, путать их ни в коем случае нельзя.
- Большинство битовых операций являются операциями составного присваивания.
Побитовое ИЛИ (OR)
Побитовое ИЛИ действует эквивалентно логическому ИЛИ, но примененному к каждой паре битов двоичного числа. Двоичный разряд результата равен 0 только тогда, когда оба соответствующих бита в равны 0. Во всех других случаях двоичный результат равен 1. То есть, если у нас есть следующая таблица истинности:
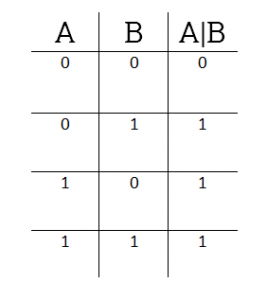
38 | 53 будет таким:
| A | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 |
|---|---|---|---|---|---|---|---|---|
| B | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 |
| A | B | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 1 |
В итоге мы получаем 1101112 , или 5510 .
Побитовое И (AND)
Побитовое И — это что-то вроде операции, противоположной побитовому ИЛИ. Двоичный разряд результата равен 1 только тогда, когда оба соответствующих бита операндов равны 1. Другими словами, можно сказать, двоичные разряды получившегося числа — это результат умножения соответствующих битов операнда: 1х1 = 1, 1х0 = 0. Побитовому И соответствует следующая таблица истинности:
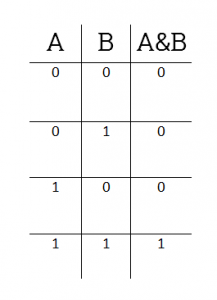
Пример работы побитового И на выражении 38 & 53:
| A | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 |
|---|---|---|---|---|---|---|---|---|
| B | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 1 |
| A & B | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
Как результат, получаем 1001002 , или 3610 .
С помощью побитового оператора И можно проверить, является ли число четным или нечетным. Для целых чисел, если младший бит равен 1, то число нечетное (основываясь на преобразовании двоичных чисел в десятичные). Зачем это нужно, если можно просто использовать %2 ? На моем компьютере, например, &1 выполняется на 66% быстрее. Довольно неплохое повышение производительности, скажу я вам.
Исключающее ИЛИ (XOR)
Разница между исключающим ИЛИ и побитовым ИЛИ в том, что для получения 1 только один бит в паре может быть 1:
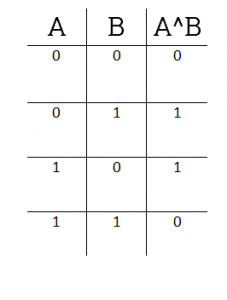
Например, выражение 138^43 будет равно…
| A | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 |
|---|---|---|---|---|---|---|---|---|
| B | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 |
| A ^ B | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 |
С помощью ^ можно поменять значения двух переменных (имеющих одинаковый тип данных) без использования временной переменной.
Также с помощью исключающего ИЛИ можно зашифровать текст. Для этого нужно лишь итерировать через все символы, и ^ их с символом-ключом. Для более сложного шифра можно использовать строку символов:
Исключающее ИЛИ не самый надежный способ шифровки, но его можно сделать частью шифровального алгоритма.
Побитовое отрицание (NOT)
Побитовое отрицание инвертирует все биты операнда. То есть, то что было 1 станет 0, и наоборот.

Вот, например, операция
Результатом будет 20310
При использовании побитового отрицания знак результата всегда будет противоположен знаку исходного числа (при работе со знаковыми числами). Почему так происходит, узнаете прямо сейчас.
Дополнительный код
Здесь мне стоит рассказать вам немного о способе представления отрицательных целых чисел в ЭВМ, а именно о дополнительном коде (two’s complement). Не вдаваясь в подробности, он нужен для облегчения арифметики двоичных чисел.
Главное, что вам нужно знать о числах, записанных в дополнительном коде — это то, что старший разряд является знаковым. Если он равен 0, то число положительное и совпадает с представлением этого числа в прямом коде, а если 1 — то оно отрицательное. То есть, 10111101 — отрицательное число, а 01000011 — положительное.
Чтобы преобразовать отрицательное число в дополнительный код, нужно инвертировать все биты числа (то есть, по сути, использовать побитовое отрицание) и добавить к результату 1.
Например, если мы имеем 109:
Представленным выше методом мы получаем -109 в дополнительном коде.
Только что было представлено очень упрощенное объяснение дополнительного кода, и я настоятельно советую вам детальнее изучить эту тему.
Побитовый сдвиг влево
Побитовые сдвиги немного отличаются от рассмотренных ранее битовых операций. Побитовый сдвиг влево сдвигает биты своего операнда на N количество битов влево, начиная с младшего бита. Пустые места после сдвига заполняются нулями. Происходит это так:
| A | 1 | 0 | 1 | 1 | 0 | 1 | 0 | 0 |
|---|---|---|---|---|---|---|---|---|
| A<<2 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 |
Интересной особенностью сдвига влево на N позиций является то, что это эквивалентно умножению числа на 2 N . Таким образом, 43<<4 == 43*Math.pow(2,4) . Использование сдвига влево вместо Math.pow обеспечит неплохой прирост производительности.
Побитовый сдвиг вправо
Как вы могли догадаться, >> сдвигает биты операнда на обозначенное количество битов вправо.
Если операнд положительный, то пустые места заполняются нулями. Если же изначально мы работаем с отрицательным числом, то все пустые места слева заполняются единицами. Это делается для сохранения знака в соответствии с дополнительным кодом, объясненным ранее.
Так как побитовый сдвиг вправо — это операция, противоположная побитовому сдвигу влево, несложно догадаться, что сдвиг числа вправо на N количество позиций также делит это число на 2 N . Опять же, это выполняется намного быстрее обычного деления.
Вывод
Итак, теперь вы знаете больше о битовых операциях и не боитесь их. Могу предположить, что вы не будете использовать >>1 при каждом делении на 2. Тем не менее, битовые операции неплохо иметь в своем арсенале, и теперь вы сможете воспользоваться ими в случае надобности или же ответить на каверзный вопрос на собеседовании.
Эффективная работа с битами при помощи Go

Это статья познакомит вас с использованием возможностей Go для выполнения манипуляций с битами. Здесь мы разберём установку, очистку, инвертирование, сдвиг битов, использование техники SWAR, эффективную обработку Юникода и прочие приёмы, позволяющие повысить продуктивность программирования.
На самом фундаментальном уровне программисту нужно манипулировать битами. Современные процессоры работают с данными через регистры, а не в виде отдельных битов, поэтому необходимо уметь управлять битами внутри регистра. Как правило, мы можем это делать в процессе программирования с использованием 8-, 16-, 32- и 64-битных целых чисел. Предположим, я хочу установить отдельный бит на 1. Выберем для этого бит по индексу 12 в 64-битном слове. Слово, где установлен только бит по индексу 12, выглядит как 1<<12 : число 1, смещённое влево 12 раз, то есть 4096.
В Go форматирование числа производится с помощью функции fmt.Printf : мы используем строку с форматирующими инструкциями, сопровождая их значениями, которые хотим вывести. Форматирующая последовательность начинается с символа % , имеющего особое значение (для вывода % используется строка %% ). Этот символ можно сопроводить буквой b , означающей «двоичный» (binary), буквой d (десятичный, decimal) или x (шестнадцатеричный, hexadecimal) формат. Иногда нам нужно указать минимальную длину вывода в символах, для чего мы предваряем такую букву числом. Например, fmt.Printf(«%100d», 4096) выведет 100-символьную строку, оканчивающуюся на 4096 и начинающуюся пробелами. Вместо пробелов в качестве заполнения можно использовать нули, добавив соответствующий символ перед значением минимальной длины вывода (например, «%0100d» ). В Go при помощи подобного приёма можно выводить отдельные биты так:
Выполнив эту программу, мы получим двоичную строку, представляющую 1<<12 :
Согласно общему правилу, при выводе чисел составляющие их цифры выводятся в порядке убывания своей значимости: например, мы пишем 1234, когда подразумеваем 1000 + 200 + 30 + 4. Аналогичным образом Go сначала выводит наиболее значимые биты, то есть число 1<<12 содержит 64-13=51 ведущий ноль, сопровождаемый 1 и 12 хвостовыми нулями.
Здесь будет интересно разобрать принцип представления отрицательных чисел. Возьмём в качестве примера 64-битное значение -2. При использовании нотации дополнения до двух это число должно быть представлено как беззнаковое (1<<64)-2 , то есть являться числом, все биты которого, кроме последнего, представлены единицами. Мы можем воспользоваться тем фактом, что операция приведения в Go (например, uint64(x) ) сохраняет это двоичное представление:
Выводом этой программы, как и ожидалось, будет:
В Go есть подходящие двоичные операторы, которые мы зачастую используем для управления битами:
- & – побитовое И (AND)
- | – побитовое ИЛИ (OR)
- ^ – побитовое исключающее ИЛИ (XOR)
- &^ – побитовое И-НЕТ (AND NOT)
Нам доступны и другие полезные тождественные равенства. Например, если даны два числа a и b , то a+b = (a^b) + 2*(a&b) . В этом равенстве 2*(a&b) представляет перенос, а a^b сложение без переноса.
Рассмотрим пример: 0b1001 + 0b01001 . Здесь 0b1 + 0b1 == 0b10 , и это компонента 2*(a&b) при том, что 0b1000 + 0b01000 == 0b11000 выражается через a^b . Мы имеем 2*(a|b) = 2*(a&b) + 2*(a^b) , а значит a+b = (a^b) + 2*(a&b) становится a+b = 2*(a|b) — (a^b) . Эти связи являются действительными как в случае знаковых, так и в случае беззнаковых целых чисел, поскольку описываемые ими операции (побитовая логика, сложение и вычитание) на уровне битов идентичны.
▍ Установка, очистка и инвертирование битов
К этому моменту мы уже знаем, как создать 64-битное слово, где всего один бит установлен на 1 (например, 1<<12 ). При этом мы также можем, наоборот, создать слово, где все биты, кроме расположенного в позиции 12, будут равны нулю. Для этого мы выполним инвертирование всех битов имеющегося слова: ^uint64(1<<12) . Перед инвертированием битов выражения иногда оказывается полезным указать его тип (взяв uint64 или uint32 ), чтобы результат получился однозначным. Затем эти слова можно использовать для воздействия на имеющееся слово:
- Чтобы установить 12-й бит слова w на единицу: w |= 1<<12 .
- Чтобы очистить (установить на ноль) 12-й бит слова w : w &^= 1<<12 (что равнозначно w = w & ^uint64(1<<12) ).
- Чтобы инвертировать только 12-й бит: w ^= 1<<12 .
- Чтобы установить 11 наименее значимых битов слова w на единицы: w |= (1<<12)-1 .
- Чтобы очистить 11 наименее значимых битов слова w : w &^= (1<<12)-1 .
- Чтобы инвертировать 11 наименее значимых битов: w ^= (1<<12)-1 .
Также можно сгенерировать слово, в котором будет установлен произвольный диапазон битов: в слове ((1<<13)-1) ^ ((1<<2)-1) биты от индекса 2 до индекса 12 включительно установлены на 1, а остальные – на 0. Эта конструкция позволяет эффективно устанавливать, очищать или инвертировать произвольный диапазон битов в слове.
Хорошо, в слове мы можем установить любой желаемый бит, а как насчёт запроса по диапазону битов? Можно проверить, установлен ли 12-й бит в слове w , проверив, равно ли выражение w & (1<<12) нулю. Если 12-й бит в w установлен, оно будет иметь значение 1<<12 . В противном случае его значение будет нулевым. Эту проверку можно расширить, а именно узнать, установлен ли какой-то из битов от индекса 2 до индекса 12 включительно на 1. Для этого нужно вычислить w & ((1<<13)-1) ^ ((1<<2)-1) . Если ни один бит в указанном диапазоне не установлен на единицу, результатом будет ноль.
▍ Эффективные и безопасные операции с целыми числами
Представляя значения в битовом формате, мы можем писать более эффективный код или лучше понимать, как выглядит оптимизированный двоичный код. Рассмотрим в качестве примера проверку того, имеют ли два числа одинаковый знак: нам нужно будет узнать, больше они нуля, меньше или же равны ему. Первая наивная реализация может выглядеть так:
Но давайте подумаем о том, что отличает отрицательные числа от других чисел: в них установлен последний бит. То есть их наиболее значимый бит в случае беззнакового значения равен единице. Если выполнить для двух целых чисел XOR, то в случае одинакового знака у этих чисел последний бит результата будет установлен на единицу. То есть результат оказывается положительным (или нулевым), только если знаки чисел совпадают. В таком случае будет предпочтительнее использовать для определения одинаковости знаков следующую функцию:
Предположим, что хотим проверить, отличаются ли x и y максимум на 1. Возможно, значение x меньше y , но оно может быть и больше.
Рассмотрим задачу вычисления среднего для двух чисел. У нас есть следующая корректная функция:
Имея более глубокое понимание целочисленного представления, можно реализовать это вычисление эффективнее.
У нас есть ещё одно подходящее равенство x == 2*(x>>1) + (x&1) . Оно означает, что x/2 находится в пределах [(x>>1), (x>>1)+1) . То есть x>>1 является максимальным числом не больше x/2 . И наоборот, (x+(x&1))>>1 является минимальным числом не меньше x/2 .
Известно, что x+y = (x^y) + 2*(x&y) . Тогда получается, что (x+y)>>1 == ((x^y)>>1) + (x&y) (игнорируя переполнения в x+y ). Таким образом, ((x^y)>>1) + (x&y) является максимальным числом не больше (x+y)/2 . Также известно, что x+y = 2*(x|y) — (x^y) или x+y + (x^y)&1= 2*(x|y) — (x^y) + (x^y)&1 , а значит (x+y+(x^y)&1)>>1 == (x|y) — ((x^y)>>1) (игнорируя переполнения в x+y+(x^y)&1 ). Получается, что (x|y) — ((x^y)>>1) является минимальным числом не меньше (x+y)/2 . Разница между (x|y) — ((x^y)>>1) и ((x^y)>>1) + (x&y ) равна (x^y)&1 . В итоге мы получаем две быстрых функции:
Несмотря на использование типа uint16 , такой вариант работает независимо от размера числа ( uint8 , uint16 , uint32 , uint64 ), а также оказывается применим к знаковым числам ( int8 , int16 , int32 , int64 ).
▍ Эффективная обработка Юникода
В UTF-16 могут присутствовать суррогатные пары: первое слово в такой паре находится в диапазоне от 0xd800 до 0xdbff при том, что второе слово относится к диапазону от 0xdc00 до 0xdfff . Как можно эффективно обнаруживать суррогатные пары?
Если значения сохраняются с использованием типа uint16 , тогда может показаться, что для выявления суррогатной пары потребуется два сравнения: (x>=0xd800) && (x<=0xdfff) . Тем не менее эффективнее будет использовать тот факт, что операции вычитания естественным образом оборачиваются: 0-0xd800==0x2800 . Таким образом, x-0xd800 будет находиться между 0 и 0xdfff-0xd800 включительно всякий раз, когда будет присутствовать значение, являющееся частью суррогатной пары. Однако любое другое значение будет больше 0xdfff-0xd800=0x7fff . Значит, требуется всего одно сравнение: (x-0xd800)<=0x7ff .
Определив наличие значения, которое может относиться к суррогатной паре, можно убедиться, что первое значение, x1 , валидно (находится в диапазоне от 0xd800 до 0xdbff ) с помощью условия (x-0xd800)<=0x3ff и проделать то же самое для второго значения, x2 : (x-0xdc00)<=0x3ff . После этого можно будет перестроить кодовую точку как (1<<20) + ((x-0xd800)<<10) + x-0xdc00 .
На практике вы можете не озадачиваться подобной оптимизацией, так как её возьмёт на себя компилятор. Тем не менее важно помнить, что операции, на первый взгляд, требующие нескольких сравнений, порой можно реализовать с помощью одного.
▍ Простая SWAR
В современных процессорах есть специализированные инструкции, способные работать над несколькими единицами данных. Этот метод называется SIMD (Single Instruction Multiple Data, ОКМД, одиночный поток команд, множественные потоки данных). Мы можем выполнять несколько операций, используя одну (или несколько) инструкций с помощью техники SWAR (SIMD within a register, ОКМД в регистре). Как правило, у нас есть 64-битное слово w ( uint64 ) и мы хотим рассматривать его в виде вектора из восьми 8-битных слов ( uint8 ).
Имея значение байта ( uint8 ), я могу повторить его по всем байтам слова с помощью одного умножения: x * uint64(0x0101010101010101 ). Предположим, у нас есть 0x12 * uint64(0x0101010101010101) == 0x1212121212121212 . Этот подход можно обобщить разными способами. Например, 0x7 * uint64(0x1101011101110101) == 0x7707077707770707 .
Для удобства определим b80 с типом uint64 как равное 0x8080808080808080 и b01 с типом uint64 как равное 0x0101010101010101 . Можно проверить, все ли байты меньше 128. Сначала мы повторим байтовое значение, в котором все биты, кроме самого значимого, установлены на ноль ( 0x80 * b01 ) или b80 , а затем выполним (AND) с нашим 64-битным словом и проверим, равен ли результат нулю: (w & b80)) == 0 .
Эта операция может скомпилироваться в две или три инструкции процессора.
Если предположить, что мы убедились в том, что все байты меньше 128, то можно выяснить, является ли любой из них нулевым, с помощью выражения ((w — b01) & b80) == 0 . Если мы не уверены, что они меньше нуля, можно просто добавить операцию (((w — b01)|w) & b80) == 0 . Проверка равенства байта нулю позволяет проверить, совпадают ли байтовые значения двух слов, w1 и w2 , поскольку в таком случае w1^w2 будет иметь нулевое байтовое значение.
Также можно выстраивать более сложные операции, если предположить, что все байтовые значения не больше 128. К примеру, с помощью процедуры ((w + (0x80 — t) * b01) & b80) == 0 можно убедиться в том, что все байтовые значения меньше 7-битного значения ( t ). Если t является константой, тогда умножение будет вычислено при компиляции и окажется ненамного более затратным, чем проверка того, все ли байты меньше 128.
В Go мы проверяем, не превышает ли какое-то значение байта 77, предполагая, что все эти значения меньше 128, через проверку равенства b80 & (w+(128-77) * b01) нулю. Аналогичным образом можно проверить, все ли байтовые значения не меньше 7-битного t , предположив, что все они также меньше 128: ((b80 — w) + t * b01) & b80) == 0 . Этот принцип можно обобщить и далее. Предположим, что хотим проверить, все ли байты не меньше 7-битного значения a и не больше 7-битного значения b . Для этого будет достаточно вычислить ((w + b80 — a * b01) ^ (w + b80 — b * b01)) & b80 == 0 .
▍ Циклический сдвиг и реверсирование битов
Работая со словом, мы говорим, что сдвигаем биты, если смещаем их влево или вправо, также смещая оставшиеся биты в начале. Для более наглядной иллюстрации принципа предположим, что у нас есть 8-битное число 0b1111000 , и мы хотим сдвинуть его влево на 3 бита. В Go для этого есть специальная функция bits.RotateLeft8 из пакета math/bits . Применив её, мы получим 0b10000111 .
В Go отсутствует операция сдвига вправо. Тем не менее при обработке 8-битного числа сдвиг влево на 3 бита – это то же самое, что сдвиг вправо на 5 бит. Go предоставляет функции сдвига для 8-, 16-, 32- и 64-битных целых чисел.
Предположим, что хотим узнать, есть ли в двух 64-битных словах, w 1 и w2 , совпадающие байтовые значения, независимо от порядка их вхождения. Мы уже умеем эффективно проверять наличие совпадающих упорядоченных байтовых значений (например, (((w1^w2 — b01)|(w1^w2)) & b80) == 0 ). Чтобы сравнить все байты одного слова со всеми байтами другого, можно повторить ту же операцию столько раз, сколько в слове содержится байтов (для 64-битных чисел восемь раз), каждый раз сдвигая одно из слов на 8 бит:
Напомню, что слова можно интерпретировать как имеющие прямой порядок байтов или обратный, в зависимости от того, являются ли первые байты наименее значимыми или наиболее значимыми. Go позволяет разворачивать порядок байтов в 64-битном слове с помощью функции bits.ReverseBytes64 из пакета math/bits . В нём также есть аналогичные функции для 16- и 32-битных слов. Нам известно, что bits.ReverseBytes16(0xcc00) == 0x00cc . Реверсирование байтов в 16-битном слове и сдвиг на 8 бит являются равнозначными операциями.
Биты также можно реверсировать. Нам известно, что bits.Reverse16(0b1111001101010101) == 0b1010101011001111 . В Go есть функции для реверсирования битов в 8-, 16, 32- и 64-битных словах. Во многих процессорах есть быстрые инструкции для реверсирования порядка битов, и эта операция может выполняться быстро.
▍ Быстрый подсчёт битов
Иногда оказывается полезным подсчитать, сколько битов в слове установлено на 1. В Go для этого есть быстрые функции из пакета math/bits , подходящие для слов из 8, 16, 32 и 64 бит. Таким образом, получается, что bits.OnesCount16(0b1111001101010101) == 10 .
Аналогичным образом иногда нужно подсчитать количество хвостовых или ведущих нулей. Число хвостовых нулей – это число последовательных нулевых битов, находящихся в наименее значимых разрядах. К примеру, в слове 0b1 хвостового нуля нет, а вот в слове 0b100 их два. Когда входное значение является степенью двойки, количество хвостовых нулей равно логарифму по основанию два. Для вычисления числа хвостовых нулей можно использовать функции bits.TrailingZeros8 , bits.TrailingZeros16 и так далее.
Количество ведущих нулей вычисляется аналогичным образом, но в этом случае мы начинаем с наиболее значимых разрядов. То есть 8-битное число 0b10000000 не имеет ведущих нулей, а в числе 0b00100000 их два. В этом случае нам помогают функции bits.LeadingZeros8 , bits.LeadingZeros16 и так далее.
И хотя количество хвостовых нулей даёт непосредственно логарифм степеней двойки, количество ведущих нулей можно использовать для вычисления логарифма любого числа, округлённого до ближайшего целого значения. Для 32-битных чисел корректный результат даст такая функция:
Также можно вычислять и другие логарифмы. Чисто логически это должно быть возможно, так как, если log_b является логарифмом по основанию b , тогда log_b (x) = \log_2(x)/\log_2(b) . Иными словами, все логарифмы находятся в пределах постоянного множителя (например, 1/log_2(b) ).
Предположим, что нас интересует количество цифр, необходимых для представления целого числа (например, для 100 требуется три цифры). Общая формула будет выглядеть как ceil(log(x+1)) , где логарифм должен вычисляться по основанию 10. Мы можем показать, что следующая функция (придуманная инженером по имени Кендалл Уиллетс) вычисляет нужное количество цифр для 32-битных чисел:
Несмотря на некоторую загадочность этой функции, её вычисление преимущественно задействует подсчёт количества хвостовых нулей и использование результата для поиска значения в таблице. Она переводится всего в несколько инструкций процессора и является эффективной.
▍ Индексирование битов
При наличии слова иногда оказывается полезным вычислить позиции установленных битов. Представим, что в слове 0b11000111 мы хотим получить индексы 0, 1, 2, 6, 7, соответствующие 5 битам со значением 1. Эффективно определить, сколько индексов нужно произвести, нам позволяют функции bits.OnesCount .
Функции bits.TrailingZeros можно использовать для определения позиции бита. Также можно воспользоваться тем фактом, что x & (x-1) устанавливает на ноль наименее значимый бит в x . Следующая функция Go генерирует массив индексов:
Получая на входе 0b11000111 , она производит массив 0, 1, 2, 6, 7 :
Если нам нужно вычислить биты в обратном порядке (7, 6, 2, 1, 0), это можно сделать с помощью функции реверсирования:
▍ Заключение
Как программист, вы можете эффективно обращаться к значениям отдельных битов, а также устанавливать, копировать или перемещать их. При должном старании в ходе этого можно избегать арифметического переполнения без особого ущерба для быстродействия. С помощью техники SWAR вы можете использовать одно слово так, будто оно состоит из нескольких подслов. И хотя большинство подобных операций пригождаются довольно редко, важно помнить об их существовании.