Как работает рандом в программировании
В статье вы узнаете, как использовать std.random и чем он хорош
Содержание
В 2011 году новый стандарт C++11 добавил в язык заголовок <random> , в котором описаны средства для работы со случайными числами на профессиональном уровне. Эти средства заменяют функцию rand и дают гораздо больше гибкости.
Но чтобы этим воспользоваться, надо немного разбираться в теории.
Почему в IT все числа неслучайные
Казалось бы, что мешает использовать в программах случайные числа? К сожалению, процессор на это не способен: его поведение строго детерминировано и не допускает никаких случайностей.
- Для генерации по-настоящему случайных, ничем не связанных чисел операционной системе приходится использовать средства, недоступные обычным приложениям; такие случайные числа называются криптографически стойкими случайными числами
- Генерация системой таких случайных чисел работает медленно, и при нехватке скорости система просто отдаёт приложениями псевдослучайные числа либо заставляет их ожидать, пока появится возможность вернуть случайное число
Вы можете узнать об этом подробнее, прочитав о разнице между устройствами /dev/random и /dev/urandom в ОС Linux
Pseudo-random Numbers Generator (PRNG)
Генератор псевдослучайных чисел (PRNG) — это алгоритм генерации последовательности чисел, похожих на случайные числа. Псевдослучайные числа не являются по-настоящему случайные, т.е. между ними остаются связывающие их закономерности.
Общий принцип генерации легко показать в примере:
Несложная итеративная формула, содержащая умножение, сложение и деление по остатку на разные константы, создаёт целую серию чисел, похожих на случайные:
Очевидно, что между числами есть взаимосвязь: они вычислены по одной и той же формуле. Но для пользователя видимой взаимосвязи нет.
Время как источник случайности
Если вы запустите предыдущую программу несколько раз, вы обнаружите проблему: числа будут те же самые. Причина проста — в начале последовательности мы используем всегда одно и то же число, 18. Для последовательности это число является зерном (англ. seed), и чтобы последовательность менялась с каждым запуском, зерно должно быть случайным.
Простейший, но не самый лучший способ получения зерна: взять текущее календарное время в секундах. Для этой цели мы воспользуемся функцией std::time_t time(std::time_t* arg).
Функция std::time возвращает число, представляющее время, прошедшее с полуночи 1 января 1970 года. Обычно это время в секундах, также известное как UNIX Timestamp. Параметр arg можно игнорировать и передавать нулевой указатель (вы можете в этом убедиться, прочитав документацию).
Теперь программа при каждом запуске будет выводить разные цепочки псевдослучайных чисел. При условии, что вы запускаете её не чаще одного раза в секунду.
Такие случайные числа далеко не идеальны: например, их нельзя использовать в криптографии, потому что злоумышленник может примерно оценить, в каком промежутке времени были созданы случайные числа, и сильно сократить затраты на дешифровку сообщения. В разработке простых учебных приложений такие числа вполне подходят
Ограничение числа по диапазону
Ограничить числа по диапазону можно путём деления по остатку (что сократит длину входного диапазона) и добавления нижней границы диапазона:
Всё то же, только лучше: заголовок <random>
Заголовок random разделяет генерацию псевдослучайных чисел на 3 части и предоставляет три инструмента:
- класс std::random_device, который запрашивает у операционной системы почти случайное целое число; этот класс более удачные зёрна, чем если брать текущее время
- класс std::mt19937 и другие классы псевдо-случайных генераторов, задача которых — размножить одно зерно в целую последовательность чисел
- класс std::uniform_int_distribution и другие классы распределений
Класс mt19937 реализует алгоритм размножения псевдослучайных чисел, известный как Вихрь Мерсенна. Этот алгоритм работает быстро и даёт хорошие результаты — гораздо более “случайные”, чем наш самописный метод, показанный ранее.
О распределениях скажем подробнее:
- линейное распределение вероятностей (uniform distribution) возникает, когда вероятность появления каждого из допустимых чисел одинакова, т.е. каждое число может появиться с равным шансом
- в некоторых прикладных задачах нужны другие распределения, в которых одни числа появляются чаще других — например, часто используется нормальное распределение (normal distribution)
В большинстве случаев вам подойдёт линейное распределение. Изредка пригодится нормальное, в котором вероятность появления числе тем ниже, чем дальше оно от среднего значения:
Теперь мы можем переписать
Особенность платформы: random_device в MinGW
Согласно стандарту C++, принцип работы std::random_device отдаётся на откуп разработчикам компилятора и стандартной библиотеки. В компиляторе G++ и его стандартной библиотеке libstdc++ класс random_device правильно работает на UNIX-платформах, но на Windows в некоторых дистрибутивах MinGW вместо случайных зёрен он возвращает одну и ту же константу!
В качестве обходного манёвра мы можем использовать текущее время в качестве зерна случайности. Для этого изменим функцию initGenerator:
Приём №1: выбор случайного значения из предопределённого списка
Допусти, вы хотите случайно выбрать имя для кота. У вас есть список из 10 имён, которые подошли бы коту, но вы хотите реализовать случайный выбор. Достаточно случайно выбрать индекс в массиве имён! Такой же метод подошёл не только для генерации имени, но также для генерации цвета из заранее определённой палитры и для других задач.
Идея проиллюстрирована в коде
Приём №2: отбрасываем неподходящее значение
Если предыдущую программу запустить несколько раз, то рано или поздно у вас возникнет ситуация, когда одно и то же имя было выведено дважды. Что, если вам нужно уникальное значение, не выпадавшее прежде за время запуска программы?
Тогда используйте цикл, чтобы запрашивать случайные значения до тех пор, пока очередное значение не попадёт под ваши требования. Будьте аккуратны: если требования нереалистичные, вы получите бесконечный цикл!
Доработаем программу, добавив цикл while в функцию main. Для сохранения уже использованных имён воспользуемся структурой данных std::set из заголовка <set> , представляющей динамическое множество.
Алгоритмы рандома
В этой статье вы увидите самые разнообразные велосипеды алгоритмы для генерации случайных чисел.
Про что статья
C++ rand
Первое что узнаёт начинающий программист С++ по теме получения рандома — функция rand, которая генерирует случайное число в пределах от 0 и RAND_MAX. Константа RAND_MAX описана в файле stdlib.h и равна 32’767, но этом может быть не так, например в Linux (см. коммент). Если же rand() в вашем компиляторе генерирует числа в пределах 32’767 (0x7FFF) и вы хотите получить случайное число большого размера, то код ниже можно рассматривать как вариант решения этой проблемы:
Реализация функции rand в старом C была проста и имела следующий вид:
Данная реализация имела не очень хорошее распределение чисел и ныне в C++ улучшена. Так же стандартная библиотека C++ предлагает дополнительные способы получения случайного числа, о которых ниже.
С++11 STL random
Данный сорт рандома появился в C++11 и представляет из себя следующий набор классов: minstd_rand, mt19937, ranlux, knuth_b и разные их вариации.
Чтобы последовательность случайных чисел не повторялась при каждом запуске программы, задают «зерно» псевдослучайного генератора в виде текущего времени или, в случае с некоторыми ретро (и не только) играми — интервалы между нажатиями клавиш с клавиатуры/джойстика. Библиотека random же предлагает использовать std::random_device для получения зерна лучше чем от time(NULL), однако в случае с компилятором MinGW в Windows функция практически не работает так как надо. До сих пор…
Некоторые из алгоритмов в STL random могут работать быстрее чем rand(), но давать менее качественную последовательность случайных чисел.
PRNG — Pseudo-random Numbers Generator
Можете считать это название — синонимом линейного конгруэнтного метода. PRNG алгоритмы похожи на реализацию rand в C и отличаются лишь константами.
PRNG алгоритмы быстро работают и легки в реализации на многих языках, но не обладают большим периодом.
XorShift
Алгоритм имеющий множество вариаций отличающихся друг от друга периодом и используемыми регистрами. Подробности и разновидности XorShift’а можете посмотреть на Википедии или Хабре. Приведу один из вариантов с последовательностью 2 в 128-й степени.
Данный генератор очень хорош тем, что в нём вообще нет операций деления и умножения — это может быть полезно на процессорах и микроконтроллерах в которых нету ассемблерных инструкций деления/умножения (PIC16, Z80, 6502).
8-bit рандом в эмуляторе z26
Z26 это эмулятор старенькой приставки Atari2600, в коде которого можно обнаружить рандом ориентированный на работу с 1-байтовыми регистрами.
Однажды мне пришлось сделать реализацию этого алгоритма для z80:
Компактный рандом для Z80 от Joe Wingbermuehle
Если вам интересно написание программ под машины с зилогом, то представляю вашему вниманию алгоритм от Joe Wingbermuehle (работает только на зилоге):
Генератор рандома в DOOM
В исходниках игры Дум есть такой интересный файл под названием m_random.c (см. код), в котором описана функция «табличного» рандома, то есть там вообще нет никаких формул и магии с битовыми сдвигами.
Приведу более компактный код наглядно показывающий работу этой функции.
Конечно же это ни какой не рандом и последовательность случайных чисел легко предугадать даже на уровне интуиции в процессе игры, но работает всё это крайне быстро. Если вам не особо важна криптографическая стойкость и вы хотите что-то быстро генерирующее «типа-рандом», то эта функция для вас. Кстати в Quake3 рандом выглядит просто — rand()&0x7FFF.
RDRAND
Некоторые современные процессоры способны генерировать случайные числа с помощью одной ассемблерной команды — RDRAND. Для использования этой функции в C++ вы можете вручную прописать нужные инструкции ассемблерными вставками или же в GCC подключить файл immintrin.h и выбрать любую из вариаций функции _rdrandXX_step, где XX означает число бит в регистре и может быть равно 16, 32 или 64.
Если вы увидите ошибку компиляции, то это значит, что вы не включили флаг -mrdrnd или ваш компилятор/процессор не поддерживает эту инструцию. Возможно это самый быстрый генератор случайных чисел, но есть вопросы в его криптографической стойкости, так что думайте.
Концовка
Класс std::minstd_rand из библиотеки STL random работает быстрее обыкновенного rand() и может стать его альтернативной заменой, если вас не особо волнует длинна периода в minstd. Возможны различия в работе этих функций в Windows и Unix’ах.
Модуль random. Генерация случайных чисел

В процессе программирования на Python может понадобиться случайное число. О том, как создать собственный простейший генератор псевдослучайных чисел и пойдет разговор в этой статье. Будут рассмотрены некоторые популярные методы и функции, которые включены в модуль random для Python 3 и позволяют получать значения случайным образом (randomly).
В качестве лирического отступления следует сказать, что, согласно специфике внутреннего состояния генератора, модуль для Python под названием random позволяет сгенерировать не случайный, а псевдослучайный элемент, то есть значения и их последовательности формируются на основе формулы. Раз последовательность зависит от нескольких параметров, она не является случайной в полном смысле этого слова. Если нужна истинная случайность, генерация может основываться, к примеру, на принципах квантовой механики, однако на практике это слишком дорого и сложно, да и не всегда экономически целесообразно, ведь для многих задач программирования вполне подойдут и псевдослучайные генераторы (если речь идет не про онлайн-казино). Вдобавок к этому, случайность (randomness) — вещь капризная, поэтому, как тут не вспомнить прекрасное высказывание американского математика Роберта Кавью:
Также на ум приходит еще одно интересное высказывание, но уже от выдуманного персонажа и с некоторым уклоном в философию:

Применение random в Python
В языке программирования «Пайтон» модуль random позволяет реализовывать генератор псевдослучайных чисел для разных распределений, куда входят как целые (integers), так и вещественные числа, то есть числа с плавающей запятой.
Общий список методов, поддерживаемых модулем random, можно посмотреть в таблице ниже. Тут стоит обратить внимание, что возврат значений может осуществляться на основе разных распределений (распределение Парето, распределение Вейбулла и т. д.), выбор которых зависит от области применения генератора случайных чисел (статистика, теория вероятности).
![]()
Но мы не будем углубляться в распределения, а рассмотрим самые простые методы. А так как разглядывать их в таблице совершенно неинтересно, давайте попрактикуемся и выясним, как может быть использован тот или иной метод в деле.
Но прежде чем это сделать и иметь возможность полноценно использовать модуль, его надо импортировать. Делается это предельно просто: нужно прописать в начале кода import random .
random.random
У модуля random есть одноименный метод-тезка — функция random. Она возвращает случайное число в диапазоне 0 — 1.0:
print(«Выводим случайное число с помощью random.random():»)
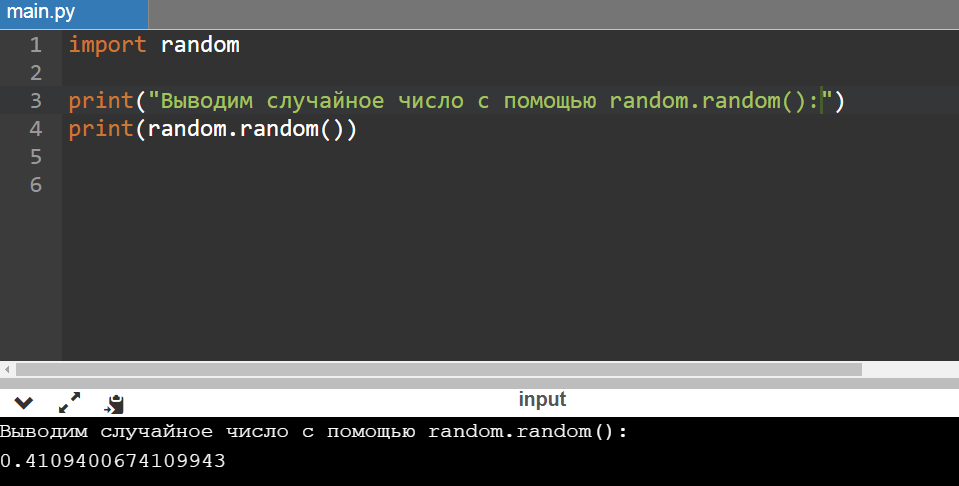
Если вы скопируете этот простейший код себе (можно использовать любой онлайн-компилятор), вы получите другое число.
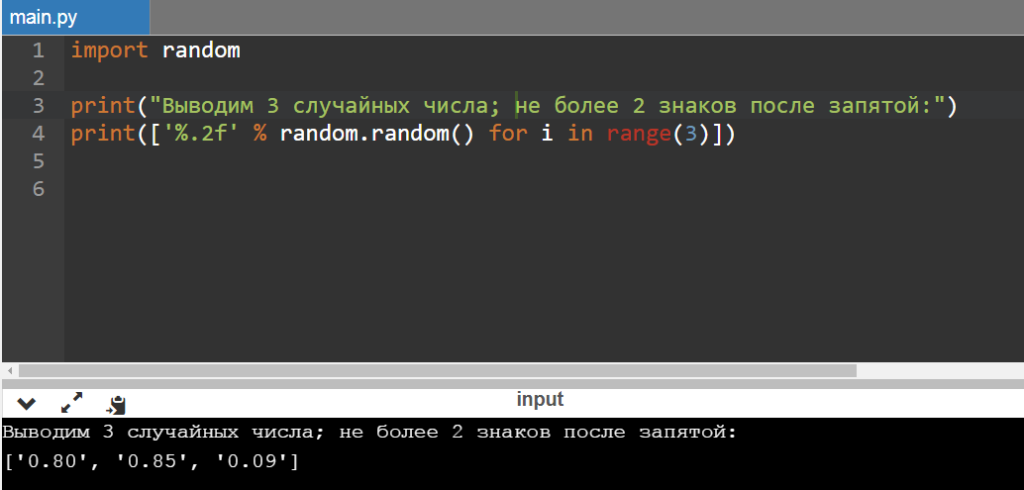
Также вывести можно не одно, а, к примеру, три (three) числа (используется for i in range), причем прекрасным решением будет ограничить вывод до двух знаков после запятой (за это отвечает ‘%.2f’):
print(«Выводим 3 случайных числа; не более 2 знаков после запятой:»)
print([‘%.2f’ % random.random() for i in range(3)])
random.seed
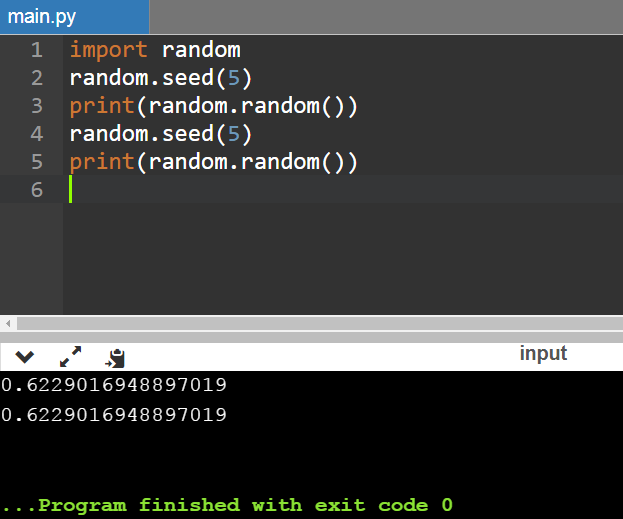
Метод seed может показаться более сложным для понимания. Фишка в том, что, как уже было сказано выше, используется генератор псевдослучайных чисел, то есть выдача этих чисел происходит в соответствии с алгоритмом. Алгоритм вычисляет значение на основе другого числа, но это число берется не с потолка — оно вычисляется на основании текущего системного времени. В результате, если вы будете пробовать на своем компьютере один из кодов, рассмотренных выше, вы будете получать каждый раз новые числа.
Если же задействовать seed с одним и тем же параметром, то вычисление будет производиться на основании этого параметра. Итог — на выходе будут получаться одинаковые «случайные» значения. Возьмем для примера параметр 5 и сделаем так, чтобы метод отработал дважды:
random.uniform
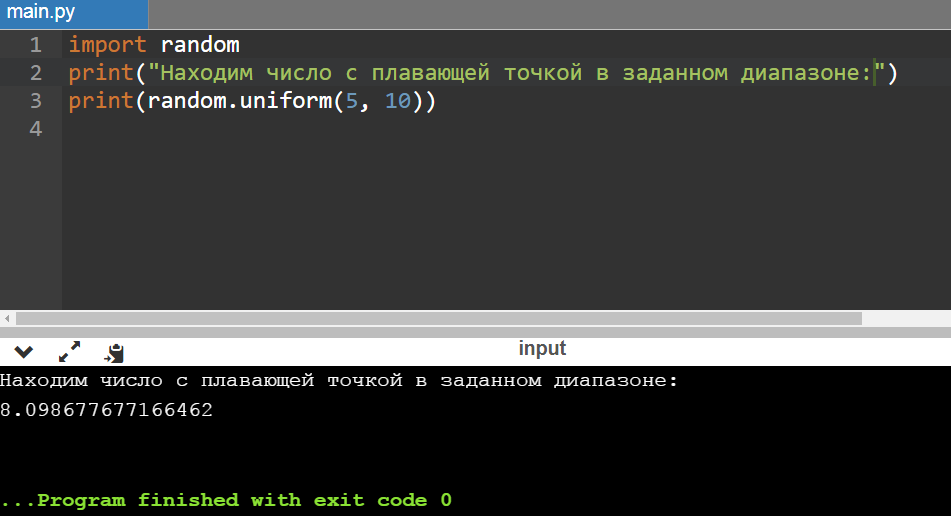
С uniform все проще: возвращается псевдослучайное вещественное число, находящееся в определенном диапазоне, который указывается разработчиком:
print(«Находим число с плавающей точкой в заданном диапазоне:»)
random.randint
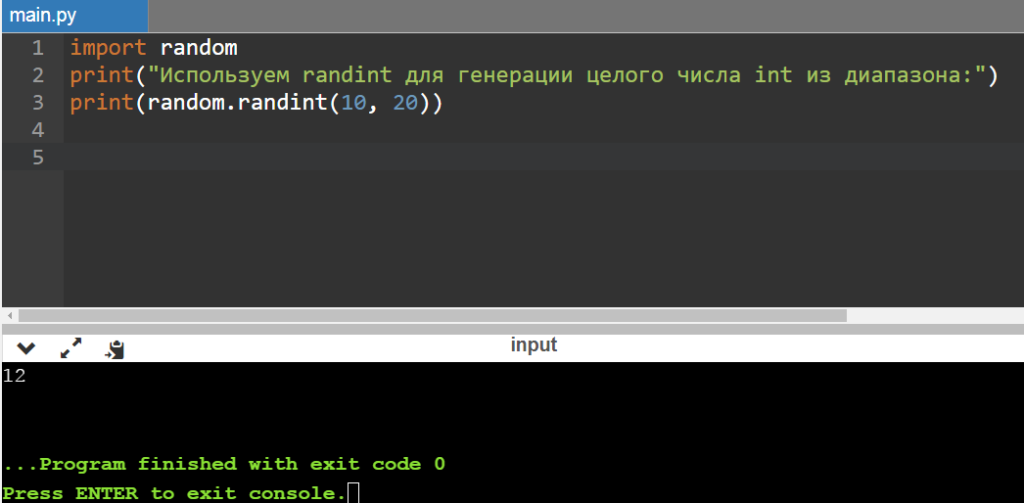
Randint в Python тоже позволяет вернуть псевдослучайное число в определенном диапазоне, но тут уже речь идет о целом значении (int, integer):
print(«Используем randint для генерации целого числа int из диапазона:»)
random.randrange
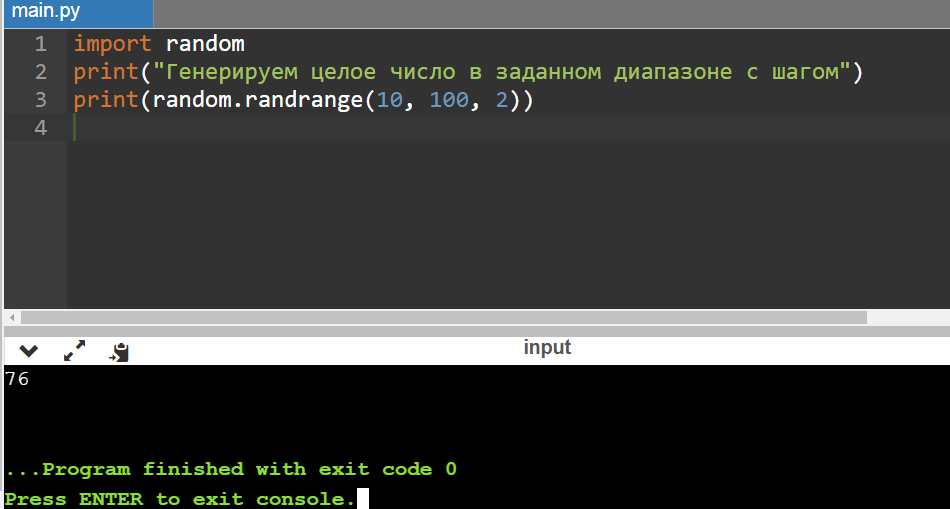
Следующий метод, называемый randrange, похож на предыдущий randint, но тут, кроме диапазона целых значений int, можно добавить еще и шаг выборки (в качестве третьего параметра):
print(«Генерируем случайное целое число в заданном диапазоне с шагом»)
print(random.randrange(10, 100, 2))
Судя по результату ниже и в соответствии с выбранным диапазоном от 10 до 100, установив шаг 2, мы будем получать лишь четные значения:
random.choice
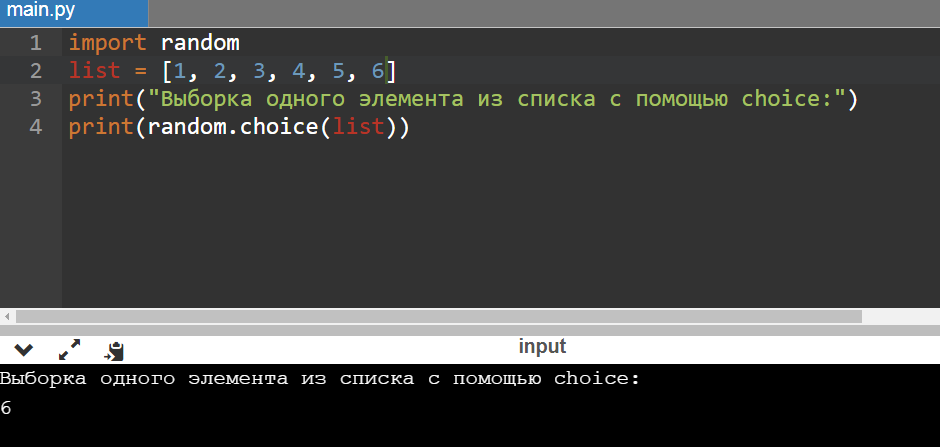
Применение choice позволяет вернуть элемент из какой-нибудь последовательности — это может быть список, строка, кортеж.
И это уже интереснее, т. к. напрашивается аналогия с броском игрального кубика:
list = [1, 2, 3, 4, 5, 6]
print(«Выборка одного элемента из списка с помощью choice:»)
Ура, выпало шесть!
Проверьте, повезет ли так и вам. Но вообще, перечень может состоять из других цифр и даже слов.
Сыграйте в игру и попробуйте погадать, какой язык программирования вам лучше учить в Otus:
print(«Какой язык программирования будешь учить?»)
Sample и choices
Начиная с Python 3.6, появился метод choices. Его отличие в том, что он позволяет сделать выборку нескольких элементов из последовательности, а вот сколько именно будет значений, можно указать. В отличие от схожего метода sample, в choices возможно получение одинаковых цифр.
Вернемся к нашему виртуальному кубику. Вот работа sample:
list = [1, 2, 3, 4, 5, 6]
print («Выборка двух случайных значений:»)

Все бы ничего, но этот метод будет постоянно выводить 2 разных значения. Если же мы захотим сымитировать бросок двух игральных кубиков, код придется менять, ведь в реальной жизни выкинуть дубль все-таки можно. Но зачем менять код, если есть choices? Он обеспечит вывод двух случайных значения из заданного диапазона, причем они могут повторяться. Это уже максимально приближено к реальному броску двух кубиков, причем профит достигается и за счет того, что объем кода не увеличивается. Ради интереса мы его даже уменьшили — оптимизировали (List превратился в l, да и лишний текст выкинули):
Кстати, вот и дубль — результат равен [6, 6], причем всего лишь с 5-й попытки (можете поверить на слово):
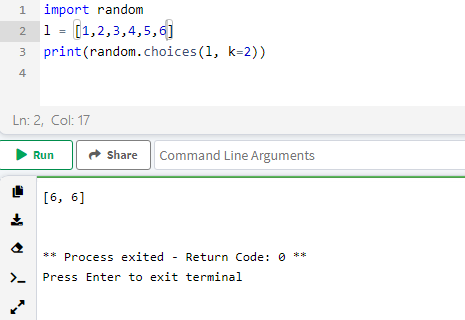
Правда, тут нюанс: пришлось сменить онлайн-компилятор, так как на предыдущем компиляторе Python версии 3.6 не поддерживался.
random.shuffle
Функция с интересным названием shuffle может перемешивать последовательность, меняя местами значения (она не подходит для неизменяемых объектов). Здесь важна именно последовательность выпадения определенных значений, как в лото.
print («Крутим барабан и достаем шары наугад: «, list)
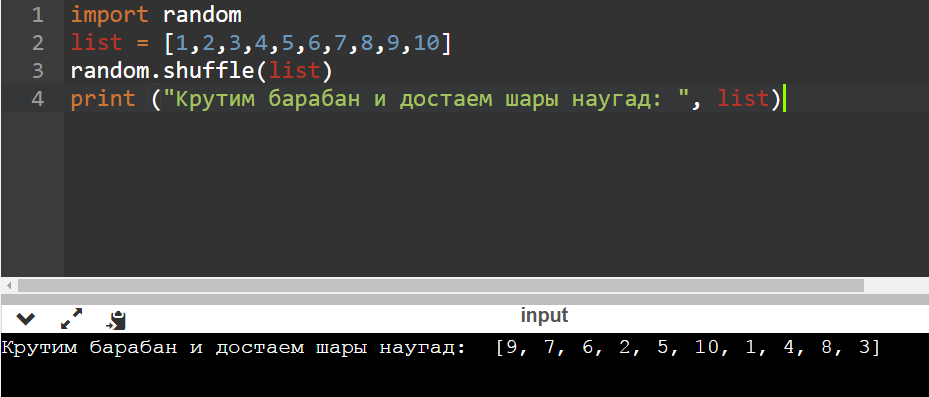
Остается добавить, что английское слово shuffle означает «тасовать, перемешивать». Как тут не вспомнить картежного шулера или лопату-шуфлю для перемешивания бетонного раствора. Но это так, для общего развития.
Урок №71. Генерация случайных чисел
Возможность генерировать случайные числа очень полезна в некоторых видах программ, в частности, в играх, программах научного или статистического моделирования. Возьмем, к примеру, игры без рандомных (или «случайных») событий — монстры всегда будут атаковать вас одинаково, вы всегда будете находить одни и те же предметы/артефакты, макеты темниц и подземелий никогда не будут меняться и т.д. В общем, сюжет такой игры не очень интересен и вряд ли вы будете в нее долго играть.
Генератор псевдослучайных чисел
Так как же генерировать случайные числа? В реальной жизни мы часто бросаем монетку (орел/решка), кости или перетасовываем карты. Эти события включают в себя так много физических переменных (например, сила тяжести, трение, сопротивление воздуха и т.д.), что они становятся почти невозможными для прогнозирования/контроля и выдают результаты, которые во всех смыслах являются случайными.
Однако компьютеры не предназначены для использования физических переменных — они не могут подбросить монетку, бросить кости или перетасовать реальные карты. Компьютеры живут в контролируемом электрическом мире, где есть только два значения (true и false), чего-то среднего между ними нет. По своей природе компьютеры предназначены для получения прогнозируемых результатов. Когда мы говорим компьютеру посчитать, сколько будет 2 + 2 , мы всегда хотим, чтобы ответом было 4 (не 3 и не 5 ).
Следовательно, компьютеры неспособны генерировать случайные числа. Вместо этого они могут имитировать случайность, что достигается с помощью генераторов псевдослучайных чисел.
Генератор псевдослучайных чисел (сокр. «ГПСЧ») — это программа, которая принимает стартовое/начальное значение и выполняет с ним определенные математические операции, чтобы конвертировать его в другое число, которое совсем не связано со стартовым. Затем программа использует новое сгенерированное значение и выполняет с ним те же математические операции, что и с начальным числом, чтобы конвертировать его в еще одно новое число — третье, которое не связано ни с первым, ни со вторым. Применяя этот алгоритм к последнему сгенерированному значению, программа может генерировать целый ряд новых чисел, которые будут казаться случайными (при условии, что алгоритм будет достаточно сложным).
На самом деле, написать простой ГПСЧ не так уж и сложно. Вот небольшая программа, которая генерирует 100 рандомных чисел:
Результат выполнения программы:
18256 4675 32406 6217 27484
975 28066 13525 25960 2907
12974 26465 13684 10471 19898
12269 23424 23667 16070 3705
22412 9727 1490 773 10648
1419 8926 3473 20900 31511
5610 11805 20400 1699 24310
25769 9148 10287 32258 12597
19912 24507 29454 5057 19924
11591 15898 3149 9184 4307
24358 6873 20460 2655 22066
16229 20984 6635 9022 31217
10756 16247 17994 19069 22544
31491 16214 12553 23580 19599
3682 11669 13864 13339 13166
16417 26164 12711 11898 26797
27712 17715 32646 10041 18508
28351 9874 31685 31320 11851
9118 26193 612 983 30378
26333 24688 28515 8118 32105
Каждое число кажется случайным по отношению к предыдущему. Главный недостаток этого алгоритма — его примитивность.
Функции srand() и rand()
Языки Cи и C++ имеют свои собственные встроенные генераторы случайных чисел. Они реализованы в двух отдельных функциях, которые находятся в заголовочном файле cstdlib:
Функция srand() устанавливает передаваемое пользователем значение в качестве стартового. srand() следует вызывать только один раз — в начале программы (обычно в верхней части функции main()).
Функция rand() генерирует следующее случайное число в последовательности. Оно будет находиться в диапазоне от 0 до RAND_MAX (константа в cstdlib, значением которой является 32767 ).
Вот пример программы, в которой используются обе эти функции:
Результат выполнения программы:
14867 24680 8872 25432 21865
17285 18997 10570 16397 30572
22339 31508 1553 124 779
6687 23563 5754 25989 16527
19808 10702 13777 28696 8131
18671 27093 8979 4088 31260
31016 5073 19422 23885 18222
3631 19884 10857 30853 32618
31867 24505 14240 14389 13829
13469 11442 5385 9644 9341
11470 189 3262 9731 25676
1366 24567 25223 110 24352
24135 459 7236 17918 1238
24041 29900 24830 1094 13193
10334 6192 6968 8791 1351
14521 31249 4533 11189 7971
5118 19884 1747 23543 309
28713 24884 1678 22142 27238
6261 12836 5618 17062 13342
14638 7427 23077 25546 21229
Стартовое число и последовательности в ГПСЧ
Если вы запустите вышеприведенную программу (генерация случайных чисел) несколько раз, то заметите, что в результатах всегда находятся одни и те же числа! Это означает, что, хотя каждое число в последовательности кажется случайным относительно предыдущего, вся последовательность не является случайной вообще! А это, в свою очередь, означает, что наша программа полностью предсказуема (одни и те же значения ввода приводят к одним и тем же значениям вывода). Бывают случаи, когда это может быть полезно или даже желательно (например, если вы хотите, чтобы научная симуляция повторялась, или вы пытаетесь исправить причины сбоя вашего генератора случайных подземелий в игре).
Но в большинстве случаев это не совсем то, что нам нужно. Если вы пишете игру типа Hi-Lo (где у пользователя есть 10 попыток угадать число, а компьютер говорит ему, насколько его предположения близки или далеки от реального числа), вы бы не хотели, чтобы программа выбирала одни и те же числа каждый раз. Поэтому давайте более подробно рассмотрим, почему это происходит и как это можно исправить.
Помните, что каждое новое число в последовательности ГПСЧ генерируется исходя из предыдущего определенным способом. Таким образом, при постоянном начальном числе ГПСЧ всегда будет генерировать одну и ту же последовательность! В программе, приведенной выше, последовательность чисел всегда одинакова, так как стартовое число всегда равно 4541 .
Чтобы это исправить нам нужен способ выбрать стартовое число, которое не будет фиксированным значением. Первое, что приходит на ум — использовать рандомное число! Это хорошая мысль, но если нам нужно случайное число для генерации случайных чисел, то это какой-то замкнутый круг, вам не кажется? Оказывается, нам не обязательно использовать случайное стартовое число — нам просто нужно выбрать что-то, что будет меняться каждый раз при новом запуске программы. Затем мы сможем использовать наш ГПСЧ для генерации уникальной последовательности рандомных чисел исходя из уникального стартового числа.
Общепринятым решением является использование системных часов. Каждый раз, при запуске программы, время будет другое. Если мы будем использовать значение времени в качестве стартового числа, то наша программа всегда будет генерировать разную последовательность чисел при каждом новом запуске!
В языке Cи есть функция time(), которая возвращает в качестве времени общее количество секунд, прошедшее от полуночи 1 января 1970 года. Чтобы использовать эту функцию, нам просто нужно подключить заголовочный файл ctime, а затем инициализировать функцию srand() вызовом функции time(0) .
Вот вышеприведенная программа, но уже с использованием функции time() в качестве стартового числа:
Теперь наша программа будет генерировать разные последовательности случайных чисел! Попробуйте сами.
Генерация случайных чисел в заданном диапазоне
В большинстве случаев нам не нужны рандомные числа между 0 и RAND_MAX — нам нужны числа между двумя другими значениями: min и max . Например, если нам нужно сымитировать бросок кубика, то диапазон значений будет невелик: от 1 до 6 .
Вот небольшая функция, которая конвертирует результат функции rand() в нужный нам диапазон значений:
Чтобы сымитировать бросок кубика, вызываем функцию getRandomNumber(1, 6) .
Какой ГПСЧ является хорошим?
Как мы уже говорили, генератор случайных чисел, который мы написали выше, не является очень хорошим. Сейчас рассмотрим почему.
Хороший ГПСЧ должен иметь ряд свойств:
Свойство №1: ГПСЧ должен генерировать каждое новое число с примерно одинаковой вероятностью. Это называется равномерностью распределения. Если некоторые числа генерируются чаще, чем другие, то результат программы, использующей ГПСЧ, будет предсказуем! Например, предположим, вы пытаетесь написать генератор случайных предметов для игры. Вы выбираете случайное число от 1 до 10, и, если результатом будет 10, игрок получит крутой предмет вместо среднего. Шансы должны быть 1 к 10. Но, если ваш ГПСЧ неравномерно генерирует числа, например, десятки генерируются чаще, чем должны, то ваши игроки будут получать более редкие предметы чаще, чем предполагалось, и сложность, и интерес к такой игре автоматически уменьшаются.
Создать ГПСЧ, который бы генерировал равномерные результаты — сложно, и это одна из главных причин, по которым ГПСЧ, который мы написали в начале этого урока, не является очень хорошим.
Свойство №2: Метод, с помощью которого генерируется следующее число в последовательности, не должен быть очевиден или предсказуем. Например, рассмотрим следующий алгоритм ГПСЧ: num = num + 1 . У него есть равномерность распределения рандомных чисел, но это не спасает его от примитивности и предсказуемости!
Свойство №3: ГПСЧ должен иметь хорошее диапазонное распределение чисел. Это означает, что маленькие, средние и большие числа должны возвращаться случайным образом. ГПСЧ, который возвращает все маленькие числа, а затем все большие — предсказуем и приведет к предсказуемым результатам.
Свойство №4: Период циклического повторения значений ГПСЧ должен быть максимально большим. Все ГПСЧ являются циклическими, т.е. в какой-то момент последовательность генерируемых чисел начнет повторяться. Как упоминалось ранее, ГПСЧ являются детерминированными, и с одним значением ввода мы получим одно и то же значение вывода. Подумайте, что произойдет, когда ГПСЧ сгенерирует число, которое уже ранее было сгенерировано. С этого момента начнется дублирование последовательности чисел между первым и последующим появлением этого числа. Длина этой последовательности называется периодом.
Например, вот представлены первые 100 чисел, сгенерированные ГПСЧ с плохой периодичностью:
112 9 130 97 64
31 152 119 86 53
20 141 108 75 42
9 130 97 64 31
152 119 86 53 20
141 108 75 42 9
130 97 64 31 152
119 86 53 20 141
108 75 42 9 130
97 64 31 152 119
86 53 20 141 108
75 42 9 130 97
64 31 152 119 86
53 20 141 108 75
42 9 130 97 64
31 152 119 86 53
20 141 108 75 42
9 130 97 64 31
152 119 86 53 20
141 108 75 42 9
Заметили, что он сгенерировал 9 , как второе число, а затем как шестнадцатое? ГПСЧ застревает, генерируя последовательность между этими двумя 9-ми: 9-130-97-64-31-152-119-86-53-20-141-108-75-42- (повтор).
Хороший ГПСЧ должен иметь длинный период для всех стартовых чисел. Разработка алгоритма, соответствующего этому требованию, может быть чрезвычайно сложной — большинство ГПСЧ имеют длинные периоды для одних начальных чисел и короткие для других. Если пользователь выбрал начальное число, которое имеет короткий период, то и результаты будут соответствующие.
Несмотря на сложность разработки алгоритмов, отвечающих всем этим критериям, в этой области было проведено большое количество исследований, так как разные ГПСЧ активно используются в важных отраслях науки.
Почему rand() является посредственным ГПСЧ?
Алгоритм, используемый для реализации rand(), может варьироваться в разных компиляторах, и, соответственно, результаты также могут быть разными. В большинстве реализаций rand() используется Линейный Конгруэнтный Метод (сокр. «ЛКМ»). Если вы посмотрите на первый пример в этом уроке, то заметите, что там, на самом деле, используется ЛКМ, хоть и с намеренно подобранными плохими константами.
Одним из основных недостатков функции rand() является то, что RAND_MAX обычно устанавливается как 32767 (15-битное значение). Это означает, что если вы захотите сгенерировать числа в более широком диапазоне (например, 32-битные целые числа), то функция rand() не подойдет. Кроме того, она не подойдет, если вы захотите сгенерировать случайные числа типа с плавающей запятой (например, между 0.0 и 1.0 ), что часто используется в статистическом моделировании. Наконец, функция rand() имеет относительно короткий период по сравнению с другими алгоритмами.
Тем не менее, этот алгоритм отлично подходит для изучения программирования и для программ, в которых высококлассный ГПСЧ не является необходимостью.
Для приложений, где требуется высококлассный ГПСЧ, рекомендуется использовать алгоритм Вихрь Мерсенна (англ. «Mersenne Twister»), который генерирует отличные результаты и относительно прост в использовании.
Отладка программ, использующих случайные числа
Программы, которые используют случайные числа, трудно отлаживать, так как при каждом запуске такой программы мы будем получать разные результаты. А чтобы успешно проводить отладку программ, нужно удостовериться, что наша программа выполняется одинаково при каждом её запуске. Таким образом, мы сможем быстро узнать расположение ошибки и изолировать этот участок кода.
Поэтому, проводя отладку программы, полезно использовать в качестве стартового числа (с использованием функции srand()) определенное значение (например, 0 ), которое вызовет ошибочное поведение программы. Это будет гарантией того, что наша программа каждый раз генерирует одни и те же результаты (что значительно облегчит процесс отладки). После того, как мы найдем и исправим ошибку, мы сможем снова использовать системные часы для генерации рандомных результатов.
Рандомные числа в C++11
В C++11 добавили тонну нового функционала для генерации случайных чисел, включая алгоритм Вихрь Мерсенна, а также разные виды генераторов случайных чисел (например, равномерные, генератор Poisson и пр.). Доступ к ним осуществляется через подключение заголовочного файла random. Вот пример генерации случайных чисел в C++11 с использованием Вихря Мерсенна: