Как разделить шестиканальный wav-файл на шесть отдельных аудиодорожек?
Какой программой? Если в "Adobe Audition", то как?
Это делается в любой профессиональной программе для редактирования аудиофайлов. Просто открываете ваш исходный файл, удаляете все дорожки кроме одной и сохраняете в новый аудиофайл. Так поступаете с каждой дорожкой. В результате у вас есть несколько аудиофайлов в каждом из которых содержится только одна аудиодорожка.
Я бы Вам советовал обратить внимание на профессиональный аудио-софт от признанного лидера в этой сфере — немецкой компании Steinberg Media Technologies GmbH. Самые последние версии её продуктов Вам не нужны, вполне подойдёт Steinberg WaveLab в версиях 6 и 7 ("семёрка" — это 2012 г.). Там есть работа с многоканальным звуком — извлечение отдельных дорожек, сборка многоканальных треков и импорт, наверное, из всех ныне известных аудио-форматов. На торрент-ресурсах Вы легко найдёте эту программу.
Разделение многоканального аудио
Функция Разделить каналы позволяет вам извлечь отдельные каналы многоканального аудио и добавить их в проект.
Это используется, например, для извлечения микрофонного канала из полифонического файла WAV или для сохранения только левого или правого канала стереозаписи.
При разделении каналов действует следующее правило:
Вы можете разделить несколько многоканальных событий или клипов за раз.
Исходные многоканальные события в проекте заменяются монофоническими событиями на субдорожках соответствующих треков.
Вы можете использовать метаданные Track Info многоканальных файлов как суффикс для файлов отдельных каналов, выбрав audio-(Track Info).wav в качестве Формата названия .
Разделение звука в видеозаписях
Кадр из видео Super Mario Theme (Trumpet & Euphonium) https://youtu.be/o3a6F070Xt0
Введение
Традиционно популярными и активно исследуемыми областями в Deep Learning являются задачи обработки изображений или текстов. Тем не менее, задачи, связанные с обработкой звуков и аудиодорожек, полезны и могут найти практические приложения во многих областях. Вот неполный перечень задач обработки звука, при решении которых используются подходы на основе глубокого обучения:
Классификация звуковых сигналов;
Speech2Text. Перевод речи в текстовое отображение;
Text2Speech. Обратная предыдущей задача. Генерация речи по заданному тексту;
Поиск похожих звуков;
Sound Separation. Разделение звуковой дорожки на составляющие звуки;
Beamforming. Разделение многоканальной звуковой дорожки на возможные составляющие с учетом пространственного расположения звукозаписывающих устройств.
В данной статье я расскажу о решении задачи Sound Separation, но с одним отличием — в качестве входных данных используются видеозаписи.
Для начала разберемся: что такое звук? Звук — это механические колебания, передающиеся в среде. Звуковые колебания характеризуются амплитудой и частотой. В среднем обычный человек может услышать звуки частотой 20Гц – 20000Гц. Для представления аудиоданных в цифровом формате микрофон с определенной частотой регистрирует амплитуду механических колебаний среды, затем полученные замеры преобразуются в цифровой формат. Таким образом, звук в вычислительных устройствах представляется как временной ряд. При этом, чем более высокая частота дискретизации, тем более высокие частоты получается сохранить.
Возможно представление аудио сигнала в виде трехмерной диаграммы, где на оси абсцисс изображено время, на оси ординат – частота звука. Третье измерение с указанием амплитуды на определенной частоте в конкретный момент времени представлено интенсивностью или цветом каждой точки изображения. Такое представление называется спектрограммой. Для получения спектрограммы из исходного аудио сигнала необходимо выполнить оконное преобразование Фурье.
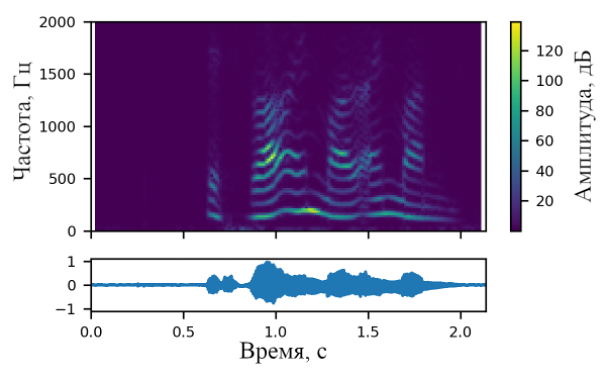
Пример спектрограммы
Такое представление позволяет применять двумерные сверточные нейронные сети в задачах обработки звука. Следует помнить, что в таком подходе не учитывается положение на изображении, хотя в случае спектрограмм это может быть важно. Например, в задаче классификации изображений совершенно неважно, находится объект внизу или вверху, при этом положение «внизу» и «вверху» на спектрограмме отвечает разным частотам, а значит разным звукам.
Задача разделения звуков заключается в получении аудиодорожек отдельных источников звука по одной аудиозаписи с несколькими источниками.
— исходная аудиодорожка, «смесь» отдельных звуков
– i-тая компонента звука
— число компонент звука
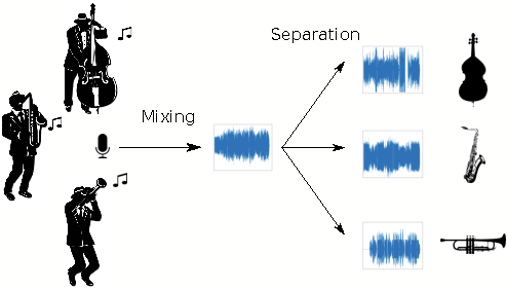
Разделение звука
Задача локализации — поиск источников звука в кадре и отделение от общей аудиодорожки.
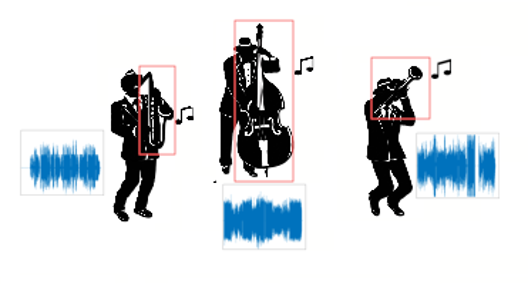
Локализация звуков
Подобрать метрику, которая идеально оценивала качество модели, не так просто. Это связано со сложностью самих звуковых данных, а так же с тем, что восприятие результата может быть субъективно. Несколько человек могут по-разному оценить качество разделения в зависимости от их музыкального слуха и других факторов. Зачастую, в задачах разделения звука используют метрику SDR, дополнительно можно вычислять SIR и SAR.
SDR — source to distortion ratio, общая оценка того, насколько хорошо источник звучит
SIR – source to interference ratio, оценка того, насколько хорошо звук отделен от остальных источников
SAR – source to artifact ratio, оценка того, насколько хорошо звук изолирован от нежелательных артефактов
Теперь, определившись с задачей и метриками, можно посмотреть как решать такую задачу.
Модель
Расскажу про подход, предложенный в статье Sound-of-Pixels. Модель состоит из нескольких частей: визуальная, аудио и синтезатор. Для начала определимся, что передается на вход в модели. Исходными данными для модели являются видеозаписи с источниками звука. Видеозапись можно представить как последовательность кадров и аудиодорожка. Аудиодорожку из одномерного представления можно перевести в спектрограмму. Таким образом, на вход модели будем подавать несколько кадров из видео и спектрограмму аудиодорожки.
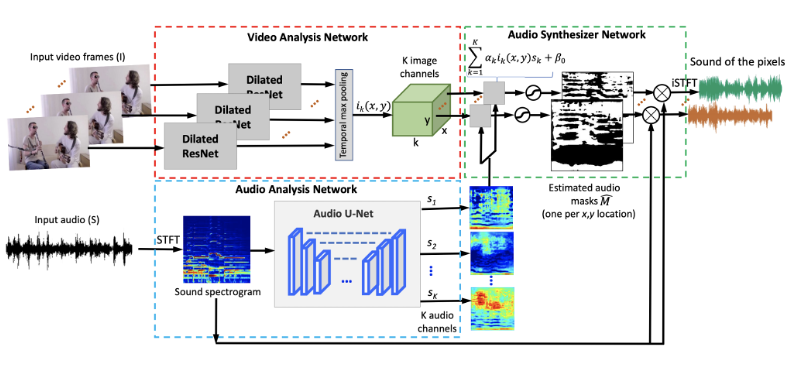
Архитектура модели
Для вычисления признаков из кадров видео используется ResNet, для генерации аудио признаков из спектрограммы применяется U-Net подобная архитектура. После вычисления видео и аудио признаков они комбинируются с некоторыми обучаемыми весами и на выходе модели получаются сетка из масок. Маска — это одноканальное изображение с таким же размером, как и у входной спектрограммы, каждый пиксель маски принимает значения от 0 до 1. Впрочем, маска может быть бинарной, тогда значения — это 0 или 1. При поэлементном умножении маски на исходную спектрограмму смеси получается спектрограмма изолированного источника звука, а по спектрограмме можно восстановить аудиодорожку изолированного звука.
При вычисления визуальных признаков пространственные размерности уменьшаются в 16 раз. При использовании кадров размером 224х224 выходная пространственная размерность получается 14х14. И в каждой пространственной точке получается визуальный размер признаков размерности K (гиперпараметр, подбирается в зависимости от датасета). Сеть синтезатор для каждой пространственной точки совмещает визуальные признаки и аудио признаки и предсказывает маску для спектрограммы. Получается маска для звуков, источники которых находятся в соответствующем участке исходных кадров.
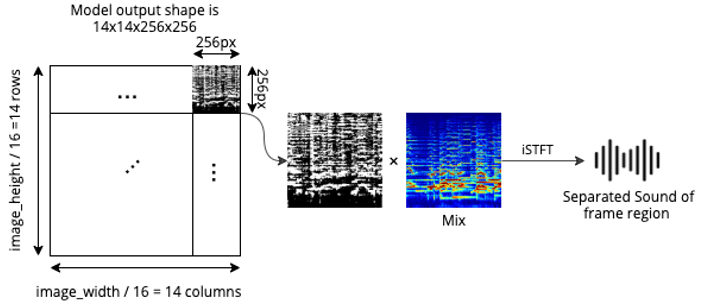
Выход модели
Обучить такую модель напрямую проблематично, поэтому авторы предлагают несколько трюков. Обучение проводится по видео с отдельными источниками звука. Если рассматривать музыкальный домен, то подойдут видео с соло исполнениями на музыкальных инструментах. Дополнительной разметки при этом не требуется, но при обучении делается несколько допущений. Во-первых, во время обучения не предсказывается сетка масок, после визуальной сети берется макспулинг по пространственным размерностям и маска вычисляется одна на весь кадр. Во-вторых, звук аддитивен, а это значит, что при сложении двух аудиозаписей в соло исполнении получается запись исполнения в дуете.
Для обучения из выборки семплируется пара видеозаписей, т.е. объект для обучения — это две видеозаписи. Аудиодорожки складываются и получается дорожка с несколькими источниками звука. В аудио часть модели подается смесь, а по кадрам первого и второго видео вычисляются соответствующие вектора визуальных признаков. Теперь можно применить синтезатор к аудио признакам и видео признакам от первого и второго видео и получить на выходе маску для извлечения исходных аудиодорожек из смеси. Исходные аудиодорожки нам известны, можно посчитать функцию потерь между предсказанными дорожками и исходными и обновить веса модели.

Обучение модели
Остается вопрос — где взять данные для обучения? Для обучения на музыкальных инструментах использовался датасет MUSIC, для обобщения модели на общий звуковой домен использовался датасет VGGSound. Данные собраны из видео на youtube, но сами датасеты — это .csv файлы с id видео. Сбор, загрузку и предобработку записей нужно выполнять своими руками. MUSIC содержит
600 видеозаписей с соло исполнением на 11 (есть часть с 21) музыкальных инструментах, а также видео с исполнениями в дуете. Все исполнения любительские, произведены в повседневной обстановке без использования профессионального оборудования. VGGSound намного больше, датасет содержит более 200 тысяч видеозаписей, а также разметку на 310 классов звуков (указывается временной отрезок в видео и метка звука, который звучит в этом отрезке)
Результаты
Давайте теперь посмотрим на результаты обученной модели. Сначала я покажу, как работает модель на музыкальных инструментах, затем на общих звуках из VGGSound.
Разберем разделение на этапе валидации на примере двух видео. Возьмем два видео с соло исполнениями, сложим их аудиодорожки и разделим обратно.
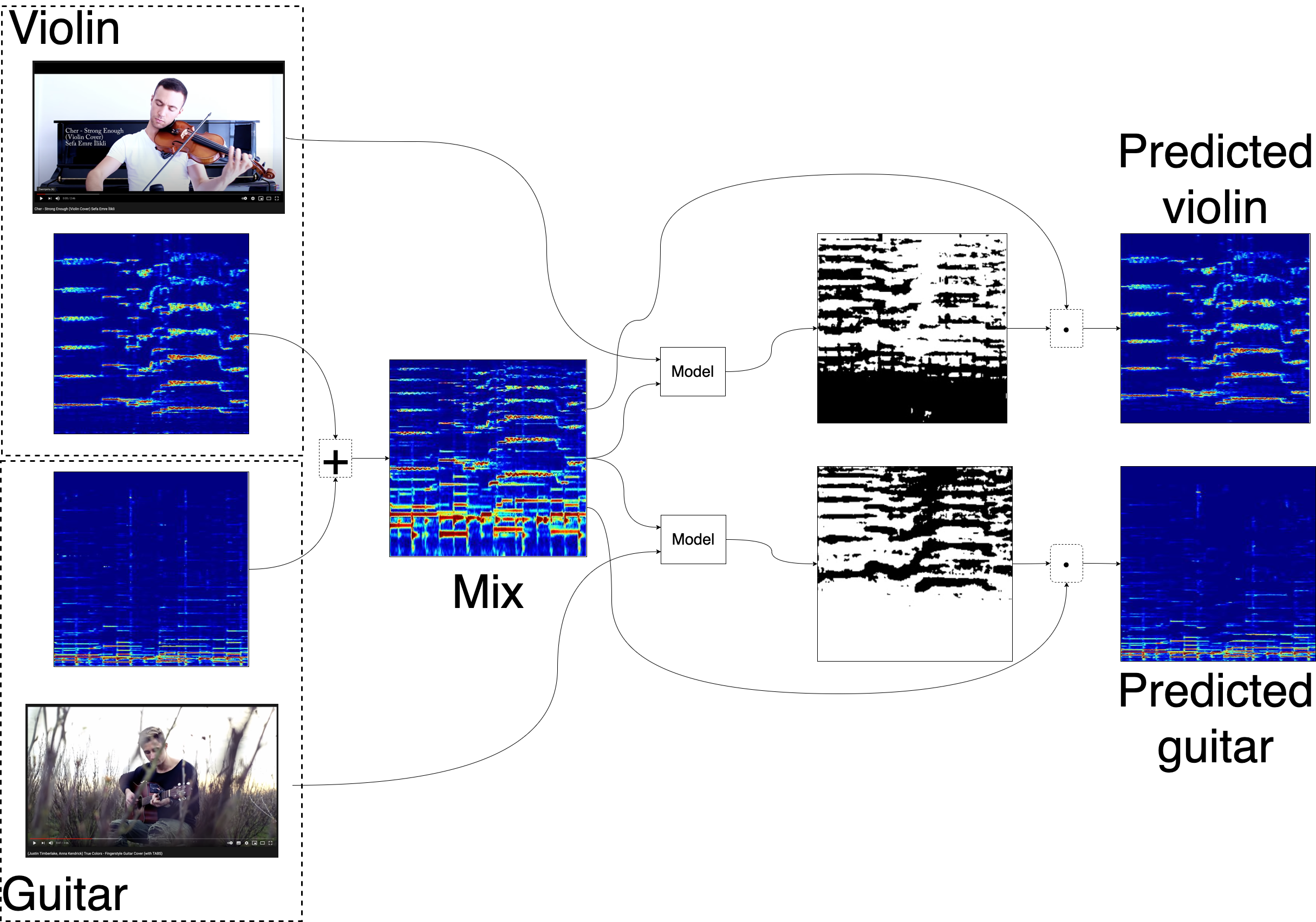
Разделение гитары и скрипки
По полученным спектрограммам можно восстановить звук и получить финальный результат
Модель работала в режиме валидации, который приближен к обучению. Визуальные признаки в этом случае считались по всему кадру, разбиения на регионы не было. Теперь можно посмотреть на результаты модели, которая не только разделяет источники, но и ищет их в кадре.
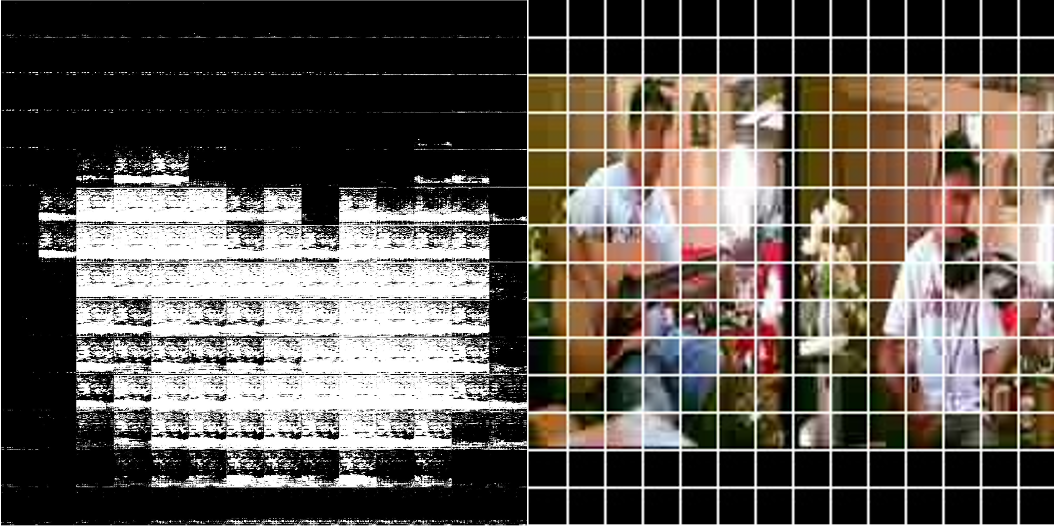
Локализация источников звука
Теперь, если взять полученную модель и обученный детектор объектов в кадре, то можно усреднять маски в предсказанных boundary box детектора и получать звуки, издаваемые объектами в кадре.
Приведу метрики, которые я получал в результате наиболее удачных экспериментов. За baseline я взял метрики, которые авторы указали в своей статье. В приведенных экспериментах я использовал размерность признаков K=16. В других экспериментах пробовал различные значения, но они дают худший результат. В статье же авторы указывают, что по их экспериментам размерность K=32 работает лучше.
Как разделить многоканальный звук на составляющие
Необработанные файлы в очереди: 20. В данный момент обрабатываются на GPU: 3/4
Информация: сайт выполняет разделение музыкального трека на отдельные составляющие: голос, отдельная музыка, барабаны, гитара, пианино и т.д. Примеры разделения трека на две части — голос и музыку можно посмотреть в видео ниже. Также посмотреть результаты разделений можно на демо-странице.
Новости [2023.07.05]
Мы сделали релиз новых моделей MDX23C. Они основаны на программном коде от kuielab, который был подготовлен для Sound Demixing Challenge 2023. Результаты полученных моделей содержат весь частотный спектр и имеют максимальные метрики качества для вокала и музыки на MultiSong Dataset. Всего доступно 4 модели, по умолчанию используется модель с максимальными метриками качества. В данный момент мы работаем над дальнейшим улучшением этих моделей. Подробнее.
Новости [2023.05.22]
- Алгоритм MDX-B теперь генерирует только вокальную и инструментальную дорожки. Это связано с тем, что остальные 3 дорожки (бас, барабаны и другое) работают не так хорошо по сравнению с Demucs4 HT. Вы по-прежнему можете получить доступ к старому MDX-B (4 дорожки) в разделе «Старые модели».
- Мы добавили модель Kim_vocal_2 (предоставленную Kimberley Jensen) и несколько других моделей UVR MDX. Kim_vocal_2 используется по умолчанию, поскольку даёт наиболее качественный результат.
- Мы обновили принцип работы алгоритма MDX используя overlap=0.8. Теперь он даёт более качественный результат (в терминах SDR метрики). Например модель Kim_vocal_2 в одиночку даёт: SDR 9.60 для вокала и SDR 15.91 для инструментальной части на Multisong dataset.
Новости [2022.04.30]
- На сайт добавлена новая модель по удалению эффекта реверберации из музыкальных треков. Она доступна под названием «FoxJoy Reverb Removal (other)». Примеры работы можно посмотреть здесь.
- Теперь доступны все модели Demucs4 HT: htdemucs_ft [метрики качества], htdemucs [метрики качества] и htdemucs_6s [метрики качества]. htdemucs_6s разделяет трек на 6 частей, помимо стандартных частей, дополнительно включет пианино и гитару. Эти модели являются лучшими для получения bass, drums и other частей треков.
- Добавлена лучшая по качеству модель MDX B для отделения вокала: «MDX Kimberley Jensen 2023.02.12 SDR: 9.30 (New)» [метрики качества].
Новости [2022.11.13]
- На сайт была добавлена собственная оригинальная модель MVSep Vocal Model, натренированная на собственном большом датасете. Она показывает отличные результаты на тестовых данных:
Synth dataset vocal SDR: 10.4523
Synth dataset instrumental SDR: 10.1561
MUSDB18HQ dataset vocal SDR: 8.8292
MUSDB18HQ dataset instrumental SDR: 15.2719 - На сайт была добавлена новая модель от команды Facebook — Demucs4 Hybrid Transformer.
Новости [2022.07.29]
- На сайт был добавлен экспериментальный алгоритм MVSep DNR, который разделяет треки на 3 части: музыку, спец-эффекты и голос. Алгоритм был натренирован на датасете «Divide and Remaster». Метрики качества:
SDR DNR for music: 6.17
SDR DNR for sfx: 7.26
SDR DNR for speech: 14.13
Алгоритм плохо подходит для обычной музыки, но неплохо справляется, когда нужно, скажем, почистить голос диктора от посторонних шумов на фоне.
Примеры работы алгоритма MVSep DNR
Новости [2022.07.25]
- Мы создали независимый синтетический набор данных для сравнения различных алгоритмов разделения музыкальных треков. Мы опубликовали датасет здесь вместе с автоматической проверяющей системой. Также доступна таблица наиболее эффективных алгоритмов.
- Добавлена новая вокальная модель MDX-B UVR. Это последняя версия от команды UVR. Опция доступна при выборе алгоритма MDX-B в форме.
Новости [2022.07.07]. Последние изменения на MVSep:
- Были добавлены новые модели из пакета Ultimate Vocal Remover построенные на базе архитектуры demucs3. На сайте они доступны под названием UVR Demucs в списке алгоритмов.
Метрики качества для разных алгоритмов, включая UVR Demucs, можно посмотреть здесь.
Новости [2022.04.18]. Последние изменения на MVSep:
- Добавлен алгоритм Danna Sep. Этот алгоритм занял 3 место на Leaderboard A в соревновании Sony Music Demixing Challenge.
- Добавлен алгоритм Byte Dance. Этот алгоритм занял второе место в категории vocals на Leaderboard A в соревновании Sony Music Demixing Challenge. Он тренировался только на данных MUSDB18HQ и имеет потенуиал в дальнейшем в случае добавления большего числа данных на обучение.
Метрики качества для этих и других алгоритмов можно посмотреть здесь.
Новости [2022.02.24]. Последние изменения на MVSep:
- Добавлены новые модели UVR: Piano, Bass, Drums и несколько различных Vocal моделей. Добавлен выбор aggressivness для UVR моделей.
- Добавлены удалённые GPU, которые обрабатывают задания в очереди. Размер очереди должен значительно сократиться.
- Для spleeter (вокал, барабаны, бас, остальное) и spleeter (вокал, барабаны, бас, пианино, остальное) добавлен вывод instrumental дорожек.
Новости [2021.12.23]. Последние изменения на MVSep:
- Добавлена возможность выбрать lossless-кодирование полученных файлов. Ранее была возможность использовать только MP3. Теперь добавлен вывод в WAV и FLAC.
- Для всех основных алгоритмов: MDX, Demucs3 и Unmix добавлен вывод общего инструментального трека (instrumental).
- Добавлен перевод сайта на Польский и Индонезийский языки.
- Добавлен скрипт сброса GPU в случае зависания. Больше не должно быть длительных простоев сервера.
К сожалению, все самые качественные алгоритмы работают очень медленно из-за чего периодически образуются очереди ожидания. Думаем, что с этим делать.
Новости [2021.11.12]: У нас три больших новости:
- Пришлось переехать на новый сервер из-за нехватки места на старом. Позитивный эффект — поменялась видеокарта на более мощную и с большим объемом памяти. Как следствие очереди ожидания уменьшились и ошибок связанных с недостатком GPU памяти стало меньше. Минус, что в два раза выросли затраты на сервер.
- Был добавлен новый алгоритм Ultimate Vocal Remover (UVR). Он разбивает трек на две части музыку и вокал. При этом обычно делает это лучше spleeter. В оригинальном UVR очень много моделей и разных настроек. Мы выбрали одну из лучших моделей и оптимальные настройки. Возможно позже будет добавлен гибкий выбор настроек для алгоритма.
- Победитель конкурса Music Demuxing Challenge наконец сделал релиз своего кода. Мы добавили его модели на сайт под названиями Demux3 Model A и Demux3 Model B. Demux3 Model B даёт более качественный результат, а для басов и барабанов работает лучше всех моделей, но слегка уступает по вокалу алгоритму MDX-B.
| Алгоритм | Качество (Bass) | Качество (Drums) | Качество (Other) | Качество (Vocals) | Пример |
|---|---|---|---|---|---|
| Spleeter (4 stems) | 5.774 | 5.845 | 4.321 | 6.939 | Пример |
| UmxXL | 6.619 | 6.838 | 4.891 | 7.732 | Пример |
| MDX A | 7.232 | 7.173 | 5.636 | 8.901 | Пример |
| MDX B (Orig) | 7.495 | 7.554 | 5.533 | 8.896 | — |
| MDX B (UVR) | 7.495 | 7.554 | 5.533 | 9.482 | Пример |
| Ultimate Vocal Remover HQ | — | — | — | — | Пример |
| Demucs 3 Model A | 8.115 | 8.037 | 5.193 | 7.968 | Пример |
| Demucs 3 Model B | 8.856 | 8.850 | 5.978 | 8.756 | Пример |
Новости [2021.10.19]: На сайт mvsep.com добавлены два новых алгоритма для разделения треков: MDX A и MDX B. Это модели, созданные участниками конкурса Music Demuxing Challenge, которые заняли второе место. Код их решения и модели нейронных сетей были выложены в открытый доступ. Мы всё ещё ждем решение первого места. Но и эти модели по конкурсным метрикам значительно обгоняют Spleeter и UmxXL (см. табличку выше), но пока проигрывают по скорости. MDX A отличается от MDX B тем что первый алгоритм не использовал внешние данные для обучения, поэтому результаты чуть хуже, чем у MDX B. Позже энтузиасты проекта UVR доработали модель по отделению вокала, получив лучше значение для метрики качества (8.896 -> 9.482).
Новости [2021.08.30]: на сайте mvsep.com несколько полезных обновлений
- Обновлены ПО и код сайта. Разделение треков стало работать быстрее и стабильнее. Всё реже случаются падения нашего бекэнда.
- Добавлен новый алгоритм разделения, который называется UnMix. У алгоритма доступно 4 модели «umxXL», «umxHQ», «umxSD», «umxSE». Самая качественная — первая «umxXL». По первым тестам, голос отделяет чуть хуже, чем spleeter, а вот инструменты лучше. В любом случае теперь открыто большое поле для экспериментов с треками.
- Переделана страница с результатми разделения: добавлен оригинальный трек, удобно сравнивать с одной страницы. Добавлена информация по настройкам разделения, выводится информация по загруженному файлу, ID3-теги и изображение (если они есть).
И напоследок немного статистики. В день на сайте разделяется около 600-750 треков. А за всё время было разделено более 300,000 треков. Двигаемся в сторону миллиона.