Русские Блоги
Мы обычно уделяем меньше внимания сигналу NACK при отладке I2C, только если Master отправляет данные, MSB First, LSB, непрерывно отправлять байт (8 бит), то раб ответит на сигнал ACK, но иногда I2C Plave может выдавать NACK Signal, давайте посмотрим на ситуацию, когда присутствует сигнал Nack.
1, выберите абзац с спецификации:


После каждого байта будет сигнал ACK. BIT ACK позволяет получателю уведомлять отправителя, что отправитель успешно получил данные и готов получить следующие данные. Все часовые импульсы включают в себя часовой импульс, соответствующий сигналу ACK, создаваемого мастером.
Сигнал ACK: отправитель выпускает линию SDA во время часового импульса ACK, и получатель может вытащить SDA Low и поддерживать низкий уровень, когда тактовый сигнал высока.
NACK SIGNAL: когда линия SDA остается высокой, когда линия SDA импульсна, она определяется как сигнал NACK. Учитель либо производит остановки условий, чтобы отказаться от этой передачи, либо повторять начальные условия для инициирования нового начала.
Вы можете увидеть следующую форму волны, мастер отправляет 01101100 (0x6c, MSB сначала), а SDA высока, когда 9-й часы высоки, указывая, что рабс отправляет сигнал NACK, и все общение I2C закончится. Это неисправная связь I2C, которая может быть выпуски из устройства I2C, или доступа к адресу устройства I2C не соответствует фактическому адресу устройства I2C, что приводит к данным, которые не получают Master для возврата NACK.

Давайте возьмем I2C датчика OV8825.
OV8825 ADDREAVE ADDORAVE OV 8825 ID 0x6c, OV8825 ID-адрес ID ID 0x300A, 0x300b, а значение в реестре ID 0x88,0x25
Нормальные сигналы I2C являются следующими:
1) Установите адрес, написанный I2C: 01101100 (0x6c) 00110000 (0x30) 00001010 (0x0a)
Slave Write Address:0x6c,ID register address:0x300a

2) Установите адрес, прочитанный I2C: 01101101 (0x6d) 10001000 (0x88)
Slave Read Address:0x6d,ID register value:0x88

20150716 немного странно видеть это, i2c запись заканчивается связь с ACK + STOP, а I2C READ — это конец NACK + STOP, из-за следующего:
Когда i2c пишу, Master после записи последнего байта раб вернется в ACK, то MASTER отправляет сигнал остановки для окончания связи.
Когда I2C прочитал, Master вернется в NAK после получения последнего байта, отправленного ведомым, потому что этот режим получил достаточно байтов, а NAK рассказывает раб не отправлять данные.
3) Установите адрес, написанный I2C: 01101100 (0x6c) 00110000 (0x30) 00001011 (0x0b)
RabbitMQ: терминология и базовые сущности
При работе с инструментом важно знать теоретические основы. Во-первых, вам будет значительно проще искать ответы на вопросы в Google и понимать официальную документацию. Во-вторых, при обращении в профильные чаты вы будете называть вещи своими именами, что позволит быстрее получить ответ (или вообще получить его: если ваши слова и термины будут непонятны другим, вряд ли они смогут ответить на вопрос).
Алексей Барабанов, IT-директор «Хлебница» и спикер курса «RabbitMQ для админов и разработчиков», подготовил конспект, который поможет понять терминологию и базовые сущности RabbitMQ.

Базовая схема всех сущностей RabbitMQ

Пробежимся по названиям слева направо:
Publisher — публикует (паблишит) сообщения в Rabbit.
Exchange — обменник. Сущность Rabbit, точка входа для публикации всех сообщений.
Binding — связь между Exchange и очередью.
Queue — очередь для хранения сообщений.
Messages — сообщение, атомарная сущность.
Consumer — подписывается на очередь и получает от Rabbit сообщения.
Также встречаются термины:
Publishing — процесс публикования сообщений в обменник.
Consuming — процесс подписывания consumer ***на очередь и получение им сообщений.
Routing Key — свойство Binding.
Persistent — свойство сохранения данных при перезагрузке сервиса (также известное как стейт).
Publisher

Внешнее приложение (крон/вебсервис/что угодно), генерирующее сообщения в RabbitMQ для дальнейшей обработки.
Создаёт соединение (connection) по протоколу AMQP, в рамках соединения создаёт канал (channel). В рамках одного соединения можно создать несколько каналов, но это не рекомендуется даже официальной документацией RabbitMQ.
«Флаппинг» каналов: если Publisher для каждого сообщения создаёт соединение, канал, отправляет сообщение, закрывает канал, закрывает соединение, это очень плохая история. Rabbit становится плохо уже на
300 таких пересозданий каналов в секунду. Будьте внимательны. Если нет возможности изменить Publisher, можно использовать amqproxy.
Важное замечание: не следует использовать amqproxy для consumer, есть проблемы одностороннего разрушения соединений.
Publisher может декларировать практически все сущности — exchanges, queues, bindings и др. На практике лучше подходит стратегия декларирования всех нужных сущностей consumer, но решать нужно для каждого проекта индивидуально.
Publisher всегда пишет в exchange. Даже если вы думаете, что он пишет напрямую в очередь, это не так. Он пишет в служебный exchange с routing key, совпадающим с названием очереди.
Publisher определяет delivery_mode для каждого сообщения — так называемый «признак персистентности». Это значит, что сообщение будет сохранено на диске и не исчезнет в случае перезагрузки Rabbit.
delivery_mode=1 — не хранить сообщения, быстрее.
delivery_mode=2 — хранить сообщения на диске, медленнее, но надёжнее.
Также publisher определяет Routing Key для каждого сообщения — признак, по которому идёт дальнейшая маршрутизация в Rabbit.

Publisher может выставлять confirm флаг — отправлять указания Rabbitmq через отдельный канал подтверждения об успешной приёмке сообщений. Например, если у Rabbit закончится место на диске, то некоторое время он ещё будет принимать сообщения от Publisher. Publisher будет думать, что всё в порядке, хотя сообщения с высокой долей вероятности не дойдут до Consumer и не сохранятся в очереди для дальнейшей обработки. Полезная вещь, но ощутимо снижает скорость работы и сложно реализуема в однопоточных языках разработки.
Также есть флаг mandatory — указание Rabbit складировать сообщения, не имеющие маршрута в какую-либо очередь в отдельный Exchange. Редкий и мало используемый кейс.
Exchange

Базовая сущность RabbitMQ. Является точкой входа и маршрутизатором/роутером всех сообщений (как входящих от Publisher, так и перемещающихся от внутренних процессов в Rabbit)
Неизменяемая сущность: для изменения параметров Exchange нужно его удалять и декларировать заново.
Binding: не являются частью Exchange, можно менять отдельно.
Рассылает сообщение во все очереди с подходящими binding (но не более одного сообщения в одну очередь, если есть несколько подходящих binding).
Durable/Transient — признак персистентности Exchange. Durable означает, что exchange сохранится после перезагрузки Rabbit.
Exchange не подразумевает хранения! Это не очередь. Если маршрут для сообщения не будет найден, сообщение сразу будет отброшено без возможности его восстановления.
Binding

Базовая сущность Rabbit, статический маршрут от Exchange до Queue (от обменника до очереди).
Неизменяемая сущность: если нужно изменить binding, его удаляют и декларируют заново.
Bindings между парой exchange-очередь может быть несколько, но только с разными параметрами.
Параметры binding — или routingkey, или headers — в зависимости от типа Exchange.
Типы Exchange

После разбора binding вернёмся к типам Exchange, так как их работа неразрывно связана.
Выделяют четыре типа Exchange:
Рассмотрим каждый более подробно.
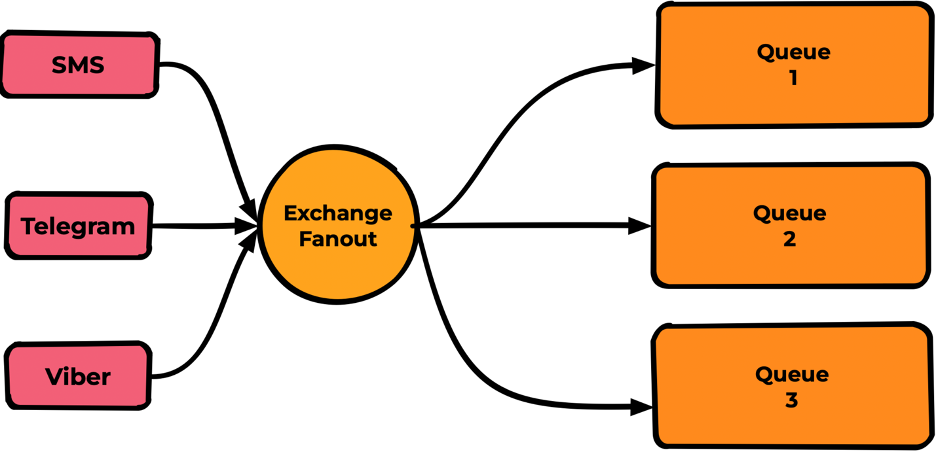
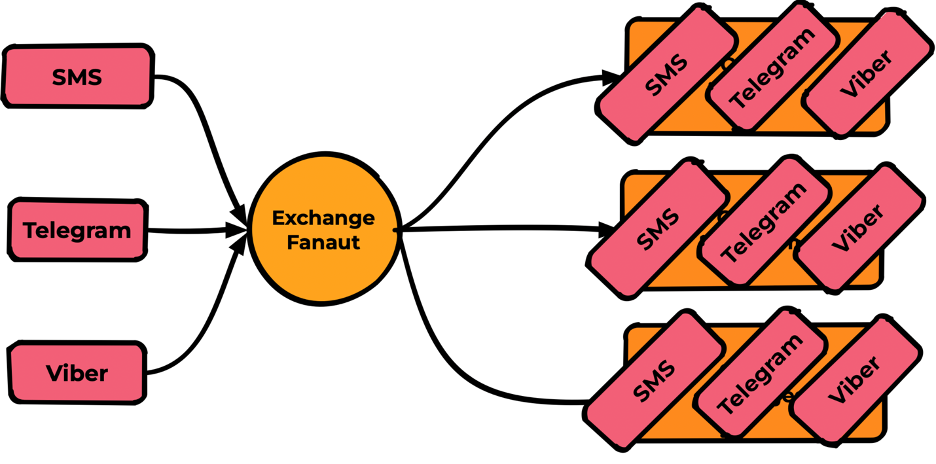
Fanout
Exchange публикует сообщения во все очереди, в которых есть binding, игнорируя любые настройки binding (routing key или заголовки).
Самый простой тип и наименее функциональный. Редко бывает нужен. По скоростям выдает на тестах около 30000mps, но столько же выдает и тип Direct.
Direct
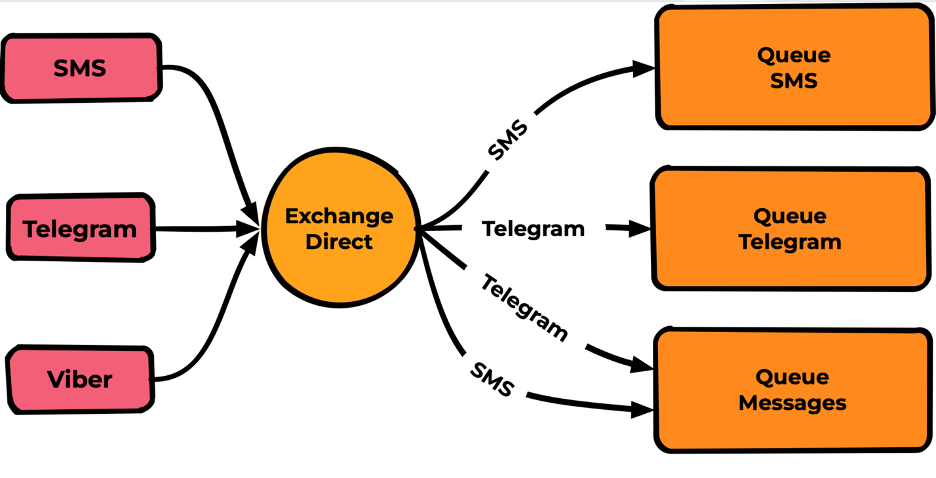
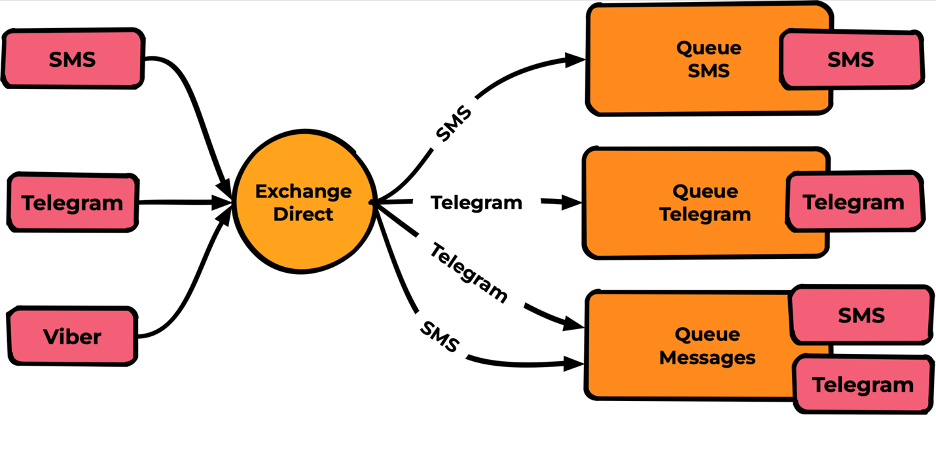
Exchange публикует сообщения во все очереди, в которых Routing Key binding полностью совпадает с Routing Key Messages.
Наиболее популярный тип, по скорости сравнимый с fanout (на тестах не увидел разницы) и при этом обладающий необходимой гибкостью для большинства задач.
Topic
Тип Exchange, похожий на Direct, но поддерживающий в качестве параметров binding Wildcard * и #, где:
— совпадение одного слова (слова разделяются точкой);
# — любое количество слов.
Производительность топика на тестах показала скорости в три раза ниже fanaut/direct — не более 5000-10000mps


Headers
Наиболее гибкий, но наименее производительный тип. Скорости очень сильно зависят от сложности условий и поэтому труднопрогнозируемы. Оперирует не Routing key, а заголовками сообщений и binding. В binding указываются ожидаемые заголовки, а также признак x-match, где:
x-match=all — необходимы все совпадения для попадания сообщения;
x-match=any — необходимо хотя бы одно совпадение.

Queue

Базовая сущность RabbitMQ, представляет из себя последовательное хранилище для необработанных сообщений.
Хранение сообщений на диске (persistent) зависит от флага delivery_mode, назначаемым publisher для каждого сообщения.
Durable/Transient — признак персистентности очереди. Durable значит, что exchange сохранится после перезагрузки Rabbit.
Важно понимать, что даже если вы отправили сообщения с признаком delivery_mode=2 (persistent), но очередь задекларирована не как Durable, то при перезагрузке Rabbit очередь и все содержащиеся в ней сообщения будут безвозвратно утрачены.
Есть три типа очередей:
Classic — обычная очередь, используется в большинстве случаев.
Quorum — аналог классической очереди, но с обеспечением гарантий консистентности, достигаемый кворумом в кластере.
Stream — новый вид очередей (начиная с версии Rabbimq 3.9), пока ещё мало кем используемый, аналог принципов Apache Kafka.
Message

Базовая сущность RabbitMQ — само сообщение, несёт полезную нагрузку (payload), проходит весь путь от Publisher до Consumer.
payload — полезная нагрузка, может быть как string, так и base64. Можно закидывать туда хоть картинки, но потом не надо удивляться огромным трафикам между сервисами. Теоретический лимит размера одного сообщения — 2Gb, но на практике рекомендуемый размер сообщения 128mb;
routing key — ключ маршрутизации, может быть только один для одного сообщения;
delivery_mode — признак персистентности;
headers — заголовки сообщения. Нужны для работы Exchange типа headers, а также для дополнительных возможностей Rabbit типа TTL.
Consumer

Замыкает обработку Сonsumer — демон, получающий сообщения из Queue и выполняющий ту самую логику, ради которой сообщение проделало весь этот путь. Например, отправка уведомления, запись в базу данных, генерация оффлайн отчёта или отправка сообщения в другую Queue.
Так же, как и Publisher, Consumer создаёт соединение (connection) по протоколу AMQP. В рамках соединения создаёт канал (channel) и уже инициирует consuming в рамках этого канала.
Consumer может декларировать практически все сущности — exchanges, queues, bindings и тд. На практике мы стараемся декларировать все сущности именно Consumer, но решать нужно для каждого проекта индивидуально.
Consumer подписывается только на одну очередь. Если вы хотите получать сообщения из разных очередей, правильнее будет корректно смаршрутизировать их потоки в одну очередь, чем городить пулы Consumer внутри приложения.
Сообщения в Consumer попадают по push-модели — протакливаются Rabbit в канал по мере их появления и (или) освобождения Consumer. Никакой периодики, задержки — это жирный плюс.
Prefetch count — важный параметр Consumer, обозначающий количество неподтверждённых Consumer сообщений в один момент. По умолчанию во многих библиотеках он равен 0 (по сути отключен). В такой ситуации Rabbit проталкивает все сообщения из очереди в Consumer, а тот во многих случаях при достаточном количестве сообщений просто отъезжает.
Если нет понимания, какое значение ставить, лучше ставить «1» — пока Consumer не обработает одно сообщение, следующее к нему не поступит. Как только Rabbit подтвердит обработку, следующее сообщение будет получено незамедлительно.
Когда вы поймёте, что у вас есть мультитред, и вы можете обрабатывать большие нагрузки, вы поднимете этот параметр, но уже осознанно.
Consumer может подтвердить обработку сообщения — механизм Acknowledge (ack). Или вернуть сообщение в Queue при неудачной обработке — механизм Negative acknowledge (nack).
Механизм nack также срабатывает автоматически при разрушении канала к Consumer. Это удобно использовать: если на горячую выключить Consumer, сообщения, которые он обрабатывал, автоматически вернутся в очередь.
AutoAck — флаг автоматического подтверждения всех протакливаемых сообщений (не требует ack от Consumer). Работает быстро, но не даёт никаких гарантий успешной обработки сообщений.
FIFO очереди
Основу Rabbit представляют собой именно такие очереди:

Попадая в очередь, сообщения выходят из неё в той же последовательности, что и вошли. Последовательность определяется моментом попадания сообщения в очередь, не бывает «одновременных сообщений» в рамках одной очереди, у них всегда есть порядок.

После выстраивания очереди по порядку мы переходим к «обслуживанию» этой очереди. Для этого подключается Consumer (например, как открытие одного кабинета в очереди к врачу).

Если мы не укажем prefetch_count, его значение будет равным нулю. Это значит, что все сообщения протолкнутся в Consumer — ничего хорошего обычно в таком поведении нет. Аналогия: открылся кабинет, и все люди в очереди ввалились туда решать свои вопросы.

Поэтому мы явно укажем prefetch_count=1. Теперь без подтверждения более одного сообщения в Consumer находится не сможет.

Далее после успешной обработки Consumer выполняет «ack» для данного сообщения:

Получив ack, Rabbit удалит сообщение из очереди и незамедлительно протолкнёт в Consumer следующее сообщение (и так далее):

А если мы захотим увеличить скорость обработки? Можем поставить в «кабинете» ещё один «стол с врачом». Для этого укажем prefetch_count=2

Теперь будет идти обработка сразу двух сообщений. А если мы хотим быстрее? Добавляем ещё один сonsumer-кабинет (например с prefetch_count=1)
NACK против ACK? Когда использовать один поверх другого?
Лично я даже не чувствую, что есть необходимость в ACK. Это быстрее, если мы просто отправим NACK (n) для потерянных пакетов вместо отправки ACK для каждого полученного пакета. Итак, когда / в каких ситуациях можно использовать ACK поверх NACK и наоборот?
Причиной ACK является то, что NACK просто недостаточно. Допустим, я отправляю вам поток данных из X сегментов (скажем, 10 для простоты).
У вас плохое соединение, и вы получаете только сегменты 1, 2, 4 и 5. Ваш компьютер отправляет NACK для сегмента 3, но не понимает, что должны быть сегменты 6-10, и не NACK их.
Итак, я пересылаю сегмент 3, но затем мой компьютер ошибочно полагает, что данные успешно отправлены.
ACK обеспечивают некоторую гарантию того, что сегмент прибыл в пункт назначения.
Если вы хотите, чтобы приложение обрабатывало порядок данных и повторных передач, вы можете просто выбрать использование протокола, такого как UDP (например, как TFTP).
Все сводится к распределению вероятности потерь и типу трафика.
Возьмем, к примеру, типичное беспроводное соединение с устойчивым уровнем потерь 10-30%. Если вы подтвердите каждый полученный кадр (например, 802.11abg), вы быстро обнаружите, когда кадр был потерян, поэтому вы не потеряете время для ожидания тайм-аута.
Если вместо этого вы использовали NAK, вы будете зависеть от схемы трафика: — Если вы отправляете один пакет запроса и ожидаете ответа, и этот запрос теряется, у вас должен быть тайм-аут, который истекает, если вы не получаете ответ. — Если вы просто отправляете поток пакетов практически беззвучному получателю, то приемлемо получать NAK только тогда, когда получатель получит следующий пакет или около того. Но это означает, что получатель должен переупорядочить пакеты и что отправитель должен отслеживать большой список невыполненных отправленных им сообщений.
(угадайте, какое решение выберет 802.11n? и то и другое. Получатель отправляет битовую карту с переменной длиной кадра, которую он получил)
Теперь возьмем типичную сеть Интернет: у вас потеря пакетов близка к 0%, пока не случится что-то плохое, и у вас будет потеря пакетов, близкая к 100%, в течение определенного времени, следуя некоторому экспоненциальному закону распределения, от прерывания 200 мс до минуты и половина.
Захватывать каждый пакет в сети без потерь может показаться бессмысленным, пока вы не рассмотрите случай, когда связь разорвана: вы не будете получать ACK или NACK в течение возможно длительного промежутка времени, а получатель, как правило, не будет отправлять что-либо до соединения восстанавливается.
Если вы используете ACK, отправитель прекратит отправку и сохранит свое отставание до восстановления ссылки. Если вместо этого вы используете NACK, то получатель может в конечном итоге сказать вам, что он не получил пакет, который долгое время оставался в резерве отправителя, и соединение по существу невозможно восстановить.
ACK полезны в протоколах скользящего окна, они позволяют передатчику A знать, что отправленные данные были получены удаленным B. Затем передатчик A может продолжить отправку следующих данных — до тех пор, пока его окно передачи не заполнится (данных, отправленных на удаленный, но еще нет). признал).
ACK могут считаться более важными, чем NAK. NAK просто обеспечивают более быстрое восстановление в случае, когда пакет / блок, отправленный A, не принят B, и B каким-то образом обнаруживает, что пакет / блок отсутствует.
Совершенно возможно разработать протокол, поддерживающий надежную передачу и управление потоком только с ACK, без NAK (с повторной передачей передатчиком в случае, если передатчик не получает ACK, механизм повторной передачи, который необходим в любом случае).
Здесь я хотел бы добавить одну самую важную вещь: в TCP мы НЕ отправляем ACK для каждого полученного пакета.
Communication Protocols
A communication protocol is a combination of rules utilized in the process of data exchange of various network devices and software systems. Communication protocols normally incorporate a list of all formal requirements and standards, including syntax, restrictions, procedures, error recovery, and synchronization of communication.
The need for a centralized standard communication protocol came because of the increase in the number of electronic devices. For example, there can be more than 7 TCU for various subsystems such as dashboard, transmission control, engine control unit, and many more in a modern vehicle. If all the nodes are connected one-to-one, then the speed of the communication would be very high, but the complexity and cost of the wires would be very high.CAN was introduced as a centralized solution that requires two wires, i.e., CAN high and CAN low. The solution of using CAN protocol is quite efficient due to its message prioritization, and flexible as a node can be inserted or removed without affecting the network.
Data frame
SOF: SOF stands for the start of frame, which indicates that the new frame is entered in a network. It is of 1 bit.
● Identifier: A standard data format defined under the CAN 2.0 A specification uses an 11-bit message identifier for arbitration. Basically, this message identifier sets the priority of the data frame.
● RTR: RTR stands for Remote Transmission Request, which defines the frame type, whether it is a data frame or a remote frame. It is of 1-bit.
● Control field: It has user-defined functions. ○ IDE: An IDE bit in a control field stands for identifier extension. A dominant IDE bit defines the 11-bit standard identifier, whereas recessive IDE bit defines the 29-bit extended identifier.
○ DLC: DLC stands for Data Length Code, which defines the data length in a data field. It is of 4 bits.
○ Data field: The data field can contain upto 8 bytes.
● CRC field: The data frame also contains a cyclic redundancy check field of 15 bit, which is used to detect the corruption if it occurs during the transmission time. The sender will compute the CRC before sending the data frame, and the receiver also computes the CRC and then compares the computed CRC with the CRC received from the sender. If the CRC does not match, then the receiver will generate the error.
● ACK field: This is the receiver’s acknowledgment. In other protocols, a separate packet for an acknowledgment is sent after receiving all the packets, but in case of CAN protocol, no separate packet is sent for an acknowledgment.
● EOF: EOF stands for end of frame. It contains 7 consecutive recessive bits known End of frame.
Voltage specs
○ Logic 1 is a recessive state. To transmit 1 on CAN bus, both CAN high and CAN low should be applied with 2.5V.
○ Logic 0 is a dominant state. To transmit 0 on CAN bus, CAN high should be applied at 3.5V and CAN low should be applied at 1.5V. ○ The ideal state of the bus is recessive.
○ If the node reaches the dominant state, it cannot move back to the recessive state by any other node.
UART
UART, or universal asynchronous receiver-transmitter, is one of the most used device-to-device communication protocols. When properly configured, UART can work with many different types of serial protocols that involve transmitting and receiving serial data. In serial communication, data is transferred bit by bit using a single line or wire. In two-way communication, we use two wires for successful serial data transfer. Depending on the application and system requirements, serial communications needs less circuitry and wires, which reduces the cost of implementation.
The two signals of each UART device are named:
The main purpose of a transmitter and receiver line for each device is to transmit and receive serial data intended for serial communication.
The transmitting UART is connected to a controlling data bus that sends data in a parallel form. From this, the data will now be transmitted on the transmission line (wire) serially, bit by bit, to the receiving UART. This, in turn, will convert the serial data into parallel for the receiving device. For UART and most serial communications, the baud rate needs to be set the same on both the transmitting and receiving device. The baud rate is the rate at which information is transferred to a communication channel. In the serial port context, the set baud rate will serve as the maximum number of bits per second to be transferred.
Data Transmission
In UART, the mode of transmission is in the form of a packet. The piece that connects the transmitter and receiver includes the creation of serial packets and controls those physical hardware lines. A packet consists of a start bit, data frame, a parity bit, and stop bits.
Start Bit
The UART data transmission line is normally held at a high voltage level when it’s not transmitting data. To start the transfer of data, the transmitting UART pulls the transmission line from high to low for one (1) clock cycle. When the receiving UART detects the high to low voltage transition, it begins reading the bits in the data frame at the frequency of the baud rate.
Data Frame
The data frame contains the actual data being transferred. It can be five (5) bits up to eight (8) bits long if a parity bit is used. If no parity bit is used, the data frame can be nine (9) bits long. In most cases, the data is sent with the least significant bit first.
Parity
Parity describes the evenness or oddness of a number. The parity bit is a way for the receiving UART to tell if any data has changed during transmission. Bits can be changed by electromagnetic radiation, mismatched baud rates, or long-distance data transfers.
After the receiving UART reads the data frame, it counts the number of bits with a value of 1 and checks if the total is an even or odd number. If the parity bit is a 0 (even parity), the 1 or logic-high bit in the data frame should total to an even number. If the parity bit is a 1 (odd parity), the 1 bit or logic highs in the data frame should total to an odd number.
When the parity bit matches the data, the UART knows that the transmission was free of errors. But if the parity bit is a 0, and the total is odd, or the parity bit is a 1, and the total is even, the UART knows that bits in the data frame have changed.
Stop Bits
To signal the end of the data packet, the sending UART drives the data transmission line from a low voltage to a high voltage for one (1) to two (2) bit(s) duration.
I2C Protocol
I2C stands for the inter-integrated controller. This is a serial communication protocol that can connect low-speed devices. It is a master-slave communication in which we can connect and control multiple slaves from a single master.
SDA (Serial Data) — The line for the master and slave to send and receive data.
SCL (Serial Clock) — The line that carries the clock signal.
I2C is a serial communication protocol, so data is transferred bit by bit along a single wire (the SDA line).
HOW I2C WORKS
With I2C, data is transferred in messages. Messages are broken up into frames of data. Each message has an address frame that contains the binary address of the slave, and one or more data frames that contain the data being transmitted. The message also includes start and stop conditions, read/write bits, and ACK/NACK bits between each data frame:
Start Condition: The SDA line switches from a high voltage level to a low voltage level before the SCL line switches from high to low.
Stop Condition: The SDA line switches from a low voltage level to a high voltage level after the SCL line switches from low to high.
Address Frame: A 7 or 10 bit sequence unique to each slave that identifies the slave when the master wants to talk to it.
Read/Write Bit: A single bit specifying whether the master is sending data to the slave (low voltage level) or requesting data from it (high voltage level).
ACK/NACK Bit: Each frame in a message is followed by an acknowledge/no-acknowledge bit. If an address frame or data frame was successfully received, an ACK bit is returned to the sender from the receiving device.
STEPS OF I2C DATA TRANSMISSION
- The master sends the start condition to every connected slave by switching the SDA line from a high voltage level to a low voltage level before switching the SCL line from high to low:
- The master sends each slave the 7 or 10 bit address of the slave it wants to communicate with, along with the read/write bit:
- Each slave compares the address sent from the master to its own address. If the address matches, the slave returns an ACK bit by pulling the SDA line low for one bit. If the address from the master does not match the slave’s own address, the slave leaves the SDA line high.
- The master sends or receives the data frame.
- After each data frame has been transferred, the receiving device returns another ACK bit to the sender to acknowledge successful receipt of the frame.
- To stop the data transmission, the master sends a stop condition to the slave by switching SCL high before switching SDA high.
SPI Protocol
SPI stands for the Serial Peripheral Interface. It is a serial communication protocol that is used to connect low-speed devices. It was developed by Motorola in the mid-1980 for inter-chip communication. It is commonly used for communication with flash memory, sensors, real-time clock (RTC), analog-to-digital converters, and more. It is a full-duplex synchronous serial communication, which means that data can be simultaneously transmitted from both directions.
MOSI (Master Output/Slave Input) — Line for the master to send data to the slave.
MISO (Master Input/Slave Output) — Line for the slave to send data to the master.
SCLK (Clock) — Line for the clock signal.
SS/CS (Slave Select/Chip Select) — Line for the master to select which slave to send data to.
MOSI AND MISO
The master sends data to the slave bit by bit, in serial through the MOSI line. The slave receives the data sent from the master at the MOSI pin. Data sent from the master to the slave is usually sent with the most significant bit first.
The slave can also send data back to the master through the MISO line in serial. The data sent from the slave back to the master is usually sent with the least significant bit first.
STEPS OF SPI DATA TRANSMISSION
1. The master outputs the clock signal:
2. The master switches the SS/CS pin to a low voltage state, which activates the slave:
3. The master sends the data one bit at a time to the slave along the MOSI line. The slave reads the bits as they are received:
4. If a response is needed, the slave returns data one bit at a time to the master along the MISO line. The master reads the bits as they are received.