Схемы имитаторов звуковых эффектов, изменение голоса
Приведены принципиальнаые схемы приставок для обработки голоса, получения искажения по типу «компьютерный голос». Устройства будут полезны для озвучивания разных событий с использованием звуковых эффектов.
Схема приставки
Схема на рисунке 1 предназначена для работы с любым источником звукового сигнала и позволяет изменить спектр на выходе относительно входного. Например, из обычной разговорной речи сделать “компьютерный голос». Достигается это за счет модуляции исходного сигнала прямоугольными импульсами, которые формирует генератор на микросхеме DA1 (рабочая частота у него выбрана около 10 Гц).
Рис. 1. Схема приставки для имитации компьютерного голоса.
Возникающие при этом искажения создают новые частотные составляющие в спектре исходного сигнала, которые и меняют тембр звука, например голоса, делая его менее похожим на оригинал.
Для получения нужного спектра может потребоваться регулировка элементов R3 и R2. Транзистор используется в качестве управляемого напряжением резистора и образует вместе с R4 управляемый напряжением аттенюатор.
Второй вариант приставки
Еще одна схема для изменения спектра сигнала показана на рисунке 2. В ней звуковой сигнал модулируется с частотой 50-90 Гц (частота изменяется резистором R2), вырабатываемой микросхемой DA1.

Рис. 2. Второй вариант приставки для создания звуковых эффектов.
Чтобы не было сильных искажений и ухудшения разборчивости, входной сигнал не должен превышать уровень в 150 мВ и поступать от источника с низким выходным сопротивлением, например, от электродинамического микрофона. Выходной сигнал подается на любой внешний усилитель. При этом во многих случаях можно не устанавливать конденсаторы С4-С5 (если в звуковом сигнале нет постоянной составляющей).
Преобразователя напряжение-ширина импульсов
Для создания некоторых устройств (стабилизации напряжения или скорости вращения электромотора, автоматического зарядного устройства и др.) может потребоваться преобразователь управляющего входного напряжения в ширину выходных импульсов. Вариант схемы такого узла приведен на рисунке 3, она обеспечивает точность преобразования не хуже 1 %.

Рис. 3. Схема преобразователя напряжение-ширина импульсов и диаграммы, поясняющие работу.
Микросхема DA1 имеет отечественный аналог К140УД7 и работает в качестве интегратора разности напряжений Uвх и Uon, а на таймере DA2 собран одновибратор с запуском от внешнего тактового генератора. Резистор R2 служит для установки нужной минимальной ширины импульсов.
Схема простого вокодера для электромузыкальных инструментов.
Вокодер — нечастый гость в музыкантской оружейни. Большинство гитаристов, так вообще, обходит эту приблуду стороной, не видя в ней целесообразности для использования в музыке своего жанра.
И только отдельные патлатые мужички, местами вполне адекватной наружности, засовывают в рот что-то вроде садового шланга, как будто рассчитывая изжевать его решительно и без остатка.
Делая отчаянное лицо: то вытягивая губы вперёд в форме рупора, то широко раскрывая рот, как будто желая что-то исторгнуть из себя, они тем самым реализуют весьма редкий, но интересный эффект “поющей электрогитары”, т.е. звучания инструмента с речевыми особенностями и интонациями голоса человека.
Эффект этот называется Talkbox, реализуется достаточно просто, но создаёт неудобства организму исполнителя в виде неприятных ощущений от наличия в полости хавальника постороннего объекта.
Гораздо более гуманными методами можно получить подобный результат при помощи устройства, которое называется вокодер.
Вокодер — это полностью электронное устройство, позволяющее перенести свойства сигнала-модулятора, в качестве которого используется голос человека, снимаемый с микрофона, на сигнал, формируемый синтезатором, электрогитарой или иным музыкальным инструментом.
А поупражнявшись в освоении своих внутренних голосовых резервов, от вокодера можно ожидать практически неограниченных и недоступных другим примочкам возможностей по обогащению звучания музыкального инструмента выразительными вариантами тембральных и амплитудных эффектов.
Схемотехническим разнообразием данный звуковой эффект не блещет. Пожалуй, единственная схема в русскоязычном исполнении была опубликована в далёком 1984 году в журнале Радио №9. Схема полностью повторила японский Okita Analog Vocoder, с той лишь разницей, что была переведена на отечественную элементную базу. Ни лучше, ни хуже она от этого не стала, при этом «относительная простота» устройства, продекларированная в источнике, вызывает если уж не явное возмущение, то справедливый скепсис — наверняка.
Попробуем устранить данный недостаток.
Описываемое устройство относится к полосным (канальным) вокодерам.
Полосный вокодер (по типу многополосного графического эквалайзера) разделяет сигнал музыкального инструмента на определённое количество полос (обычно 6-20 полос). Большее число каналов в вокодере даёт большую натуральность и разборчивость.
На такое же количество полос разбивается и модулирующий сигнал, поступающий с микрофона. На выходе каждого из микрофонных ПФ включены детектор и сглаживающий НЧ-фильтр, выделяющий огибающую речевого сигнала.
Далее всё просто — относительно медленная огибающая речевого сигнала управляет амплитудой находящегося в той же частной полосе инструментального сигнала, после чего выходные амплитуды всех инструментальных каналов суммируются и через регулятор громкости подаются на выход устройства.
Матрица фильтров вокодера покрывает частотную полосу 80-6100 Гц. Эта полоса вмещает в себя как полный частотный диапазон (включая обертоны) электрогитары, так и частотный спектр голоса, несущий максимум информации, связанной с формантной разборчивостью речи.
Поскольку задачи достижения максимально достоверного звучания классического хора мальчиков в рамках данной конструкции не подразумевалось, то было решено ограничиться октавными полосовыми фильтрами (по 6 шт. на весь диапазон), а для усиления глубины звучания вокодерного эффекта применить полосовые фильтры не 2-го порядка (что было бы логично для октавных фильтров), а чего уж там мелочиться, сразу 4-го.
Речевой сигнал усиливается операционным усилителем с нормированной характеристикой шума ОР1.1 и поступает на матрицу фильтров, выполненных на ОУ OPf1.1 и OPf1.2. На выходе каждого из микрофонных ПФ включён пиковый детектор уровня звукового сигнала на транзисторе Tf1 и сглаживающий фильтр R17, Cf5, выделяющий огибающую речевого сигнала. Частота среза данных НЧ-фильтров обычно выбирается ≈1/10 от величины минимальной частоты пропускания полосового фильтра. Далее сигнал, следующий с выхода пикового детектора, управляет коэффициентом передачи аналогичного фильтра, входящего в матрицу фильтров инструментального сигнала.
Как это происходит?
А происходит это благодаря жизнедеятельности доморощенного ШИМ-контроллера.
ОР2.1 и ОР2.2 с обвесом — это классический генератор треугольного напряжения.
Размах амплитуды выходного треугольного напряжения составляет в теории: Upp ≈ 2Uпит×R5/R6, частота F≈R6/(4R5×R12×C4).
В реальной жизни, в связи с проявлением инерционности ОУ, получились значения: Upp≈1В, F≈33кГц.
Переменный резистор R8 призван регулировать уровень постоянного смещения треугольного сигнала, а заодно — и глубину влияния модулирующего канала на изменение уровней инструментального.
Треугольное 30-ти килогерцовое напряжение с выхода генератора поступает на прямой (неинвертирующий) вход компаратора, где сравнивается с выходным напряжением детектора огибающей речевого сигнала, подаваемого на инвертирующий вход.
Таким образом на выходе компаратора образуется импульсный сигнал с частотой 33кГц и длительностью, зависящей от уровня напряжения на детекторе. Чем больше этот уровень — тем меньше длительность.
Далее этот широтно-модулированный сигнал поступает на затвор ключевого транзистора Tf2, который и осуществляет ШИМ регулировку уровня сигнала, поступающего с выхода инструментального фильтра. Чем меньше длительность импульсов (т.е. чем больше уровень напряжения на детекторе) тем слабее влияние, ключевого транзистора на работу делителя, образованного R19 и Rси открытого транзистора, а, соответственно — тем выше амплитуда инструментального сигнала. И наоборот.
Каскад на операционном усилителе ОР3 осуществляет функцию суммирования всех сигналов, поступающих с инструментальных каналов. Потенциометром R10 устанавливается уровень выходного сигнала.
Теперь, что касается элементной базы.
Входной усилитель речевого сигнала (ОР1.1) желательно выбрать малошумящим.
Операционники, работающие в генераторе треугольного напряжения (ОР2.1, ОР2.2) должны иметь граничную частоту не менее 10МГц.
Время задержки переключения компараторов (DAf) — не более 100нс.
Транзисторы Tf — любые маломощные, например: КТ3102.
К ОУ, работающему в составе фильтров, никаких особых требований не предъявляется.
И напоследок приведу номиналы пассивных элементов полосовых фильтров.
| Диапазон (Гц) | Rf1 = Rf4 (кОм) | Rf2 = Rf5 (кОм) | Rf3= R f6 (кОм) | Cf1-4 (нФ) | Сf5 (нФ) |
| 80 — 174 | 27 | 8,2 | 56 | 68 | 680 |
| 163 — 354 | 27 | 8,2 | 56 | 33 | 330 |
| 332 — 721 | 27 | 10 | 56 | 15 | 150 |
| 677 — 1469 | 22 | 10 | 47 | 8,2 | 82 |
| 1380 — 2993 | 27 | 10 | 56 | 3,6 | 47 |
| 2811 — 6100 | 27 | 10 | 56 | 1,8 | 22 |
Приведённые в таблице элементы должны иметь отклонения от номинальных значений — не выше 5%.
При исправных деталях и отсутствии ошибок в монтаже устройство не требует налаживания и начинает пахать сразу после включения питания.
Подключив электрогитару (клавишные, балалайку, арфу, либо любой другой предмет, снабжённый звукоснимателем) к инструментальному входу вокодера, покрутите переменный резистор R8, наблюдая за изменением уровня проникновения прямого сигнала инструмента на выход от нулевого до 100%. Чем выше будет установлен этот начальный уровень, тем ниже будет глубина эффекта. Для начала, найдите точку, когда громкость звучания инструмента уже не ненулевая, но достаточно низкая по сравнению с максимальной.
А вот теперь можно подключить микрофон к одноимённому входу примочки и голосом музинструмента отправить вокодерного скептика в эротическое путешествие в места заповедные, да и не столь отдалённые.
Синтезатор речи «для роботов» с нуля

Давным-давно посетила меня идея создать синтезатор речи с «голосом робота», как, например, в песне Die Roboter группы Kraftwerk. Поиски информации по «голосу робота» привели к историческому факту, что подобное звучание синтетической речи характерно для вокодеров, которые используются для сжатия речи (2400 — 9600 бит/c). Голос человека, синтезированный вокодером, отдает металлическим звучанием и становится похожим на тот самый «голос робота». Музыкантам понравился данный эффект искажения речи, и они стали активно его использовать в своем творчестве.
Поиски информации по реализации вокодера вывели меня на книгу «Теория и применение цифровой обработки сигналов», где расписано почти все, что необходимо для создания собственного синтезатора речи на основе вокодера.
Небольшое замечание касательно выбора способа реализации синтеза речи
Конечно, можно было бы и не париться с созданием вокодера, а просто сделать базу заранее записанных звуков всех фонем и проигрывать их в соответствии с текстом. Данный способ мне не был интересен, поэтому я решил сделать синтезатор речи именно с синтезом всех звуков, как согласных, так и гласных. Вокодер для этих целей был выбран потому, что его проще обучить, чем формантный синтезатор речи, хотя звучание в обоих случаях было бы именно то, которое мне нужно. К тому же, синтезирование звуков, возможно, позволит реализовать синтезатор речи на базе микроконтроллера stm32 без внешней памяти! Вопрос тут скорее в том, хватит ли скорости работы МК.
Под спойлером представлен результат обработки речи вокодером
Краткая теория работы вокодера
Самая основная часть вокодера — это гребенка полосовых фильтров. Именно она формирует спектр синтетической речи или, наоборот, определяет уровни спектра естественной человеческой речи в приемной части устройства. Как передающая, так и принимающая часть вокодера содержит гребенку полосовых фильтров.
Принимающая человеческую речь часть вокодера также определяет, помимо спектра звука, является ли звук шумовым, или у него есть тон. Для тона определяется его период. Сигналы с выходов полосовых фильтров детектируются, пропускаются через ФНЧ и используются в дальнейшем в качестве коэффициентов для модуляции сигналов на полосовых фильтрах синтезирующей части вокодера.
Синтезирующая часть вокодера содержит генератор шума и тона (читай: генератор случайной числовой последовательности на основе сдвигового регистра и генератора меандра), а также переключатель между этими двумя генераторами. Сигнал от одного из двух генераторов подается на вход гребенки полосовых фильтров. Для каждого фильтра на входе сигнал от генератора тона или шума модулируется соответствующим коэффициентом. И наконец, с выхода всех фильтров суммируем сигнал и получаем синтезированную речь.
Если кто не понял мое описание работы вокодера, вот блок-схема:
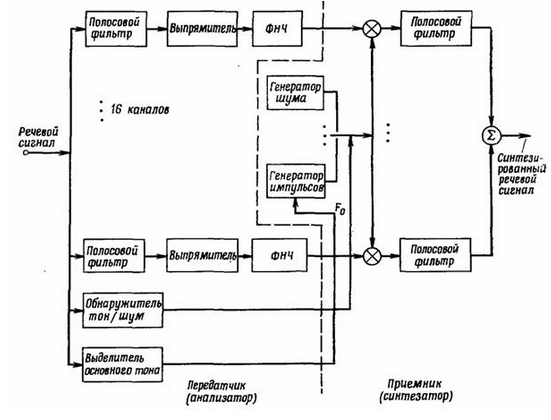
Не все так просто
Чтобы вокодер хоть как-то понятно звучал, нужно выполнить пару требований к его полосовым фильтрам. Нет времени объяснять, просто поверье, что нужно использовать БИХ фильтры Бесселя (пруфы на 749 странице). Также, нужно распределить спектр речи неравномерно по фильтрам, особенно если у нас их немного (в моей реализации вокодера их всего 16 штук). Есть еще одна прелюбопытнейшая вещь, с которой вы можете ознакомиться все в той же книжке. А именно, представим, что сначала мы пропускаем сигнал от генератора тона или шума через гребенку фильтров, затем с выхода каждого фильтра ограничиваем сигнал двумя уровнями -1 и +1 и затем модулируем сигналы и снова пропускаем каждый сигнал через такой же фильтр, как ранее. По идее, такая схема не должна давать ощутимой разницы в синтезируемой речи. Тем не менее, такой прием выравнивания спектра существенно улучшает синтетическую речь вокодера. Почему так, лучше прочесть в книжке. Ну а тем, кому лень читать, скажу кратко: это из-за флуктуаций речи человека. На картинке снизу представлена блок-схема «улучшения» вокодера.
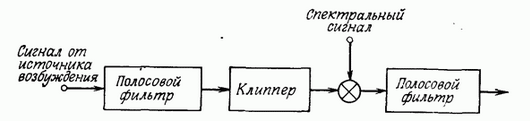
Что же касательно того, как распределить частоты между фильтрами… Основные частоты человеческой речи находятся в диапазоне примерно до 4-5 кГц (очень примерно). Я взял предел в 4 кГц и, используя психофизическую единицу измерения высоты звука «мел», распределил равномерно, правда не по герцам, а по мелам.
Что дает такой способ синтеза речи?
Если коэффициенты модуляции полосовых фильтров «смещать» по номеру фильтра, можно получить из женского голоса мужской. И это несмотря на то, что диапазоны фильтров (в моей реализации вокодера) в частотной области распределены не равномерно.
Также можно менять интонацию речи, можно вообще все менять. Единственный минус остается отстойное низкое качество речи.
Прослушать то, как меняется женская речь в мужскую, можно тут:
Немного кода
Весь код я пока выкладывать не буду (так как еще не дописал синтезатор речи — будет вторая статья). Ниже представлен код для определения высоты основного тона (также можно определить, тон или шум). Для этого измеряется энтропия сигнала, энтропия сигнала после ФНЧ на 600 Гц (в частотной области тона), а также число правильных совпадений в определителе периода тона.
Распознавания голоса на Arduino
Тема распознавания голоса микроконтроллером довольно интересна и нова, поэтому я решил представить вам схему устройства распознавания голоса на микроконтроллере, а точнее на Arduino. Распознавание голоса довольно непростая задача, а реализовать это на микроконтроллере еще сложнее, в силу ограниченности его ресурсов. В нашем случае реализация распознавания голоса будет на микроконтроллере ATmega328P, работающего на частоте 16МГц.

В данном устройстве была использована библиотека uSpeech, которая полностью автономна и не требует передачи голосовых команд на компьютер для дальнейшего распознавания, как того требуют другие библиотеки и модули, например, такие как BitVoicer.
В моей схеме распознавания голоса на микроконтроллере была использована uSpeech в силу своей автономности и малых размеров. Хотя у неё есть недостаток, такой как ограниченность распознавания. Эта библиотека позволяет распознавать только фонемы, т.е. отдельные звуки, но для многих схем и устройств этого более чем достаточно. Ниже приведен список используемых фонем (звуков):
| Фонема (звук) | Соответствующая ей буква (может быть несколько) |
| «е» | е |
| «х» | х, ш, щ, дж, ж, з |
| «в» | в, может срабатывать на з |
| «ф» | ф |
| «с» | с |
| «о» | о, а, ш, л, м, н, у, ю |
| » « | слишком тихий звук |
В качестве микрофона используется электретный микрофон (ссылка на статью на Wikipedia), обычно он выглядит так:

Сигнал с него достаточно слабый, поэтому его необходимо усилить. Усилитель для микрофона можно сделать из пары транзисторов, как было в схеме микрофонного усилителя на Радиодеде, так и на операционном усилителе, например, так:
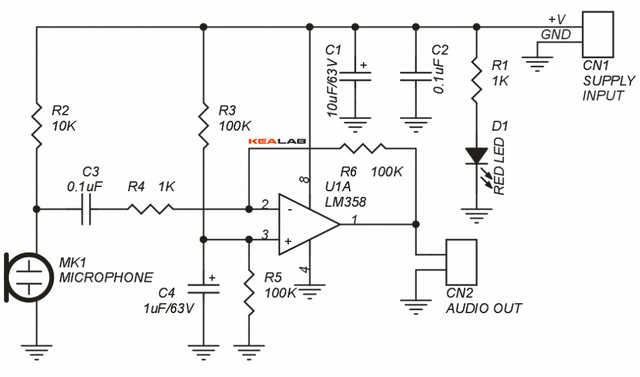
Либо можно купить готовый микрофон с усилителем на eBay или AliExpress, найти можно по запросу «Mic amplifier arduino» или «Микрофонный усилитель Arduino». Выглядит он так:

Микрофон с микрофонным усилителем желательно подключить к микроконтроллеру через резистор 470…2К и разделительный конденсатор (он уже есть в самих схемах усилителей, а также на готовых платах), который убирает постоянную составляющую.
Схема подключения микрофона и усилителя к Arduino следующая: микрофон через усилитель подключается к аналоговому порту Ардуино A0, три светодиода через резисторы подключаются к цифровым выходам 5,6,7 (схему можно изменить, внеся соответствующие, небольшие правки в исходный код программы).
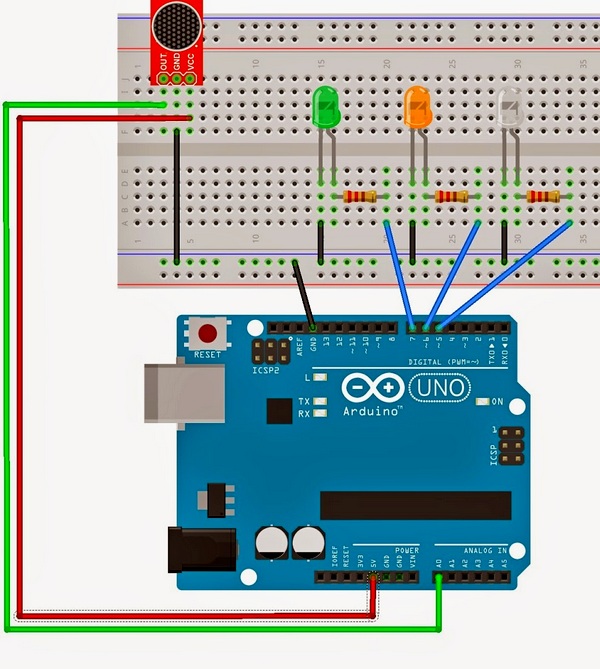
В качестве индикаторов распознанных команд были использованы три светодиода разных цветов.
В исходном примере библиотеки uSpeech сравнивались одиночные фонемы (звуки). Пример позволял распознать 6 фонем (звуков): «ф», «е», «о», «в», «с», «х» (f, e, o, v, s, h). Мной был использован массив байт, который содержал паттерны, распознаваемых слов, что позволило в конечном итоге распознавать не отдельные фонемы (звуки), а целые слова, состоящие из распознаваемых фонем. Массив полученных звуков сравнивается с заранее прописанным массивом байт (паттерном слова), и в случае совпадения, с учетом заданного порога чувствительности, делается вывод о том, какое слово было произнесено.
Например, заранее прописанные паттерны для английских слов green,orange и white были следующие «vvvoeeeeeeeofff», «hhhhhvoovvvvf», «hooooooffffffff». Для нахождения наиболее ближайшего эквивалента произносимом слову необходимо находить минимальное редакционное расстояние (расстояние Левенштейна). Для повышения точности и игнорирования нерелевантных паттернов при распозновании использовалась константа LOWEST_COST_MAX_THREASHOLD, определяющая уровень достоверности. Подбирая её значение можно добиться высокой точности распознавания.
Скомпилированный скетч занимает около 20% FLASH-памяти микроконтроллера и около 500 байт, т.е. 25% ОЗУ. Библиотеку для распознавания голосовых команд на Ардуино – uSpeech можно скачать здесь (необходимо нажать зеленую кнопку «Clone or download»). Установка библиотеки стандартная – необходимо распаковать архив и поместить папку в “C:/Users/<Имя пользователя>/Documents/Arduino/libraries”.