Конвейер команд.
Любая команда процессора выполняется в несколько этапов. Такими этапами могут быть следующие: выборка команды, дешифрация кода операции, формирование исполнительных адресов и выборка операндов, выполнение операции и запись результата. В зависимости от форматов команд, типов команд и способов адресации, принятых в данном процессоре, количество этапов и их насыщенность микрооперациями может меняться. Поскольку за выполнением каждого этапа команды закрепляется своя ступень, то для команд одного типа могут работать все ступени, а для команд другого типа часть ступеней может постаивать. Например, команды арифметических операций могут использовать все ступени конвейера, а при выполнении команд условного и безусловного переходов не требуются ступени, обеспечивающие выборку операндов, их обработку и размещение результата, т.е. эти ступени, будут простаивать.
При работе конвейера команд могут возникнуть три типа конфликтов [л 2, л 3, л4]:
конфликт по данным,
конфликт по управлению.
Структурный конфликт связан с обращением различных ступеней конвейера к одному и тому же устройству. Его еще называют конфликтом по ресурсам.
Конфликт по данным заключается в том, что следующая команда может требовать операнд, который еще не вычислен предыдущей командой.
Конфликт по управлению возникает, когда на вход конвейера загружается какая-либо из команд управления и следующей исполняемой командой должна быть команда, определяемая адресом перехода. Это изменяет последовательность загрузки на вход конвейера команд программы и нарушает работу ступеней конвейера.
При появлении любого типа конфликта в конвейере появляется «пузырь», который связан с не использованием очередного такта работы конвейера. Этот «пузырь» проходит по всему конвейеру. В зависимости от типа конфликта может занимать от 1 и более тактов, что приводит к общей потере производительности конвейера.
Рассмотрим их по порядку.
1.3.2. Структурные конфликты
Структурные конфликты чаще всего возникает при обращении различных ступеней к памяти.Предположим, что процессор работает с одноадресными командами. Тогда структуру цикла исполнения команды можно представить как последовательность трех этапов (рис.12а): выборка команды из ОЗУ и дешифрация КОП, выборка операнда и выполнение операции. Напомним, что при данной адресности команд второй операнд берется из регистра-аккумулятора и в него же записывается результат арифметической операции.
Закрепим за каждым этапом ступень конвейера. В результате получим следующую временную диаграмму работы конвейера (рис.12б). Очевидно, что для выполнения команд арифметики и ряда логических операций необходимы все 3 ступени конвейера. Для команд управления первая ступень выбирает команду, а третья ступень должна занести на программный счетчик адрес перехода. Вторая ступень в этих случаях простаивает.
Компьютерная Энциклопедия
Вы здесь: Главная ![]() Процессор
Процессор ![]() Конвейер команд
Конвейер команд ![]() Конвейер команд. Конвейеризация — способ обеспечения параллельности выполнения команд
Конвейер команд. Конвейеризация — способ обеспечения параллельности выполнения команд
Архитектура ЭВМ
Компоненты ПК
Интерфейсы
Мини блог
Самое читаемое
- Арифметико логическое устройство (АЛУ)
- Страничный механизм в процессорах 386+. Механизм трансляции страниц
- Организация разделов на диске
- Диск Picture CD
- White Book/Super Video CD
- Прямой доступ к памяти, эмуляция ISA DMA (PC/PCI, DDMA)
- Карты PCMCIA: интерфейсы PC Card, CardBus
- Таблица дескрипторов прерываний
- Разъемы процессоров
- Интерфейс Slot A
Процессор
Конвейер команд. Конвейеризация — способ обеспечения параллельности выполнения команд
Первым шагом на пути обеспечения параллельности уровня команд явилось создание конвейера команд. Идея конвейера команд была предложена в 1956 году С.А. Лебедевым. Команда подразделяется на несколько этапов, каждый из которых выполняется своей частью аппаратуры, причем, эти части могут работать параллельно. Если на выполнение каждого этапа расходуется одинаковое время (один такт), то на выходе процессора в каждый такт появляется результат очередной команды. Производительность при этом возрастает благодаря тому, что одновременно на различных ступенях конвейера выполняется несколько команд. Конвейерная обработка такого рода широко применяется во всех современных быстродействующих процессорах. Количество этапов, на которые конструкторы разбивают выполнение процессорной команды, может быть различным (в разных моделях процессоров х86 колеблется от 2 i8088 до 20 Pentium IV).
Конвейеризация — способ обеспечения параллельности выполнения команд
Выполнение типичной команды можно разделить на следующие этапы:
- выборка команды — IF (по адресу, заданному счетчиком команд, из памяти извлекается команда);
- декодирование команды / выборка операндов из регистров — ID;
- выполнение операции / вычисление эффективного адреса памяти — EX;
- обращение к памяти — MEM;
- запоминание результата — WB.
В зависимости от типа команды и способа адресации, время выполнения команды сильно варьируется. Дольше всего выполняются этапы, связанные с обращением к памяти. На рисунках показаны блоки и конвейер команд гипотетического процессора, имеющего пять блоков исполнения команд и соответственно пять этапов (ступеней). Изображены выполняемые команды, номера тактов и этапы выполнения команд. На первом такте считывается первая команда. На втором, пока декодируется первая команда, считывается вторая. На пятом такте в процессоре одновременно находятся пять команд, каждая в своем узле.

Блоки прохождения команды в процессоре
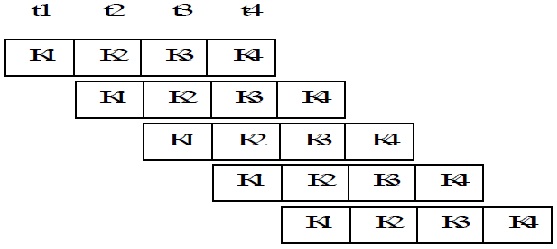
Пятиступенчатая схема конвейера
Конвейеризация увеличивает пропускную способность процессора (количество команд, завершающихся в единицу времени), но она не сокращает время выполнения отдельной команды. Имеются некоторые накладные расходы на конвейеризацию, возникающие в результате несбалансированности задержки на каждой его ступени. Частота синхронизации (такт синхронизации) не может быть выше, чем время, необходимое для работы наиболее медленной ступени конвейера. Конвейер не всегда представляет собой линейную цепочку этапов. В ряде ситуаций оказывается выгодным, когда функциональные блоки соединены между собой не последовательно, а в соответствии с логикой обработки. Отдельные блоки в цепочке могут пропускаться, а другие — образовывать циклические процедуры. Это позволяет с помощью одного конвейера вычислять более одной функции.
Поток команд — естественная последовательность команд, проходящая по конвейеру процессора. Процессор может поддерживать несколько потоков команд (суперпроцессоры 5 и 6 поколения), если для каждого потока и каждого этапа есть исполнительные элементы.
Суперконвейер команд — разбиение каждой ступени на подступени при одновременном увеличении тактовой частоты внутри конвейера; включение в состав процессора многих конвейеров, работающих с перекрытием. Дробление ступеней позволяет поднять тактовые частоты процессора. К суперконвейерным относятся процессоры, в которых число ступеней больше шести (см. таблицу).
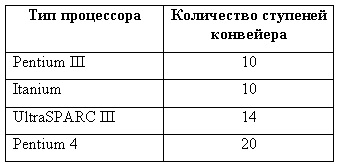
Суперконвейер
Cуперконвейер ведет не только к увеличению скорости вычислений, но и к возникновению дополнительных сложностей. Возрастает вероятность конфликтов. Дороже встает ошибка предсказания перехода — приходится сбрасывать весь длинный конвейер, на что требуется дополнительное время. Усложняется логика взаимодействия ступеней. Однако за счет использования новых архитектур удается справиться с большинством проблем. При рассмотрении современных процессоров будут описаны новые идеи: исполнения команд с изменением последовательности, переименования регистров, спекулятивного исполнения и другие.
Что такое конвейер команд в теории ос
Основная проблема быстродействия – вызов команд из памяти. Для решения этой проблемы разработаны методы опережающего вызова команд из памяти. Эти команды помещаются в специальный набор регистров, называемый буфером выборки с упреждением. Поэтому когда команда потребуется, она вызывается из буфера, а не из памяти.
Поскольку выполнение команды делится на ряд этапов, каждый из которых выполняется отдельной частью аппаратных средств ЦП, то эти части могут работать параллельно.
Процесс выполнения короткой команды (логическая или ФЗ) — цикл процессора — м.б. разделён на микрокоманды (такты процессора). Их пять. Все такты выполняются для команды только один раз и в одном и том же порядке. Т.о. если первая микрокоманда выполнилась для очередной команды и передала результат второй, то она может начать выполнять следующую команду.
Конвейеризация осуществляет многопоточную параллельную обработку команд, т.ч. в любой момент одна команда считывается, другая декодируется и т.д. и всего обрабатывается пять команд. На выходе конвейера на каждом такте процессора выдаётся результат выполнения одной команды.
| С1 | С2 | С3 | С4 | С5 |
| Блок выбора команды | Блок декодирования | Блок выбора операндов | Блок выполнения команд | Блок записи результата |
Рассмотрим конвейер из 5 блоков – стадий. Блок С1 вызывает команду из памяти и помещает её в буфер, где она хранится до тех пор, пока не будет нужна. Стадия С2 декодирует эту команду, определяя её тип, тип её операндов. Блок С3 определяет местонахождение операндов и вызывает их из регистра или из памяти. Блок С4 выполняет команду. Блок С5 записывает результат обратно в нужный регистр.
| С1 |
| С2 |
| С3 |
| С4 |
| С5 |
| Время (такты) |
Здесь показано 9 тактов действия конвейера во времени.
Во время такта 1 Блок С1 вызывает команду 1 из памяти.
Во время такта 2 Блок С2 декодирует команду 2, в то время как Блок С1 вызывает команду 2.
Во время такта 3 Блок С3 работает с операндами команды 1, Блок С2 декодирует команду 2, Блок С1 вызывает команду 3.
Во время такта 4 Блок С4 выполняет команду1, Блок С3 работает с операндами команды 2, Блок С2 декодирует команду 3, Блок С1 вызывает команду 4.
Во время такта 5 Блок С5 возвращает результат работы команды 1, Блок С4 выполняет команду 2, Блок С3 работает с операндами команды 3, Блок С2 декодирует команду 4, Блок С1 вызывает команду 5.
Для лучшего понимания принципа работы конвейера МП можно рассмотреть работу любого конвейера, например, кондитерского. В отделе отправки установлен длинный конвейер, у которого стоят 5 рабочих. Каждые 10 секунд (время такта) рабочий 1 ставит пустую коробку для торта на ленту конвейера, рабочий 2 кладёт в неё торт, рабочий 3 закрывает коробку, рабочий 4 маркирует её, рабочий 5 кладёт её в контейнер для отправки.
Пусть время такта нашего конвейера 2 нс. Тогда цикл выполнения команды 10 нс. Казалось бы, такой процессор может выполнить в секунду 100 млн. команд, но в действительности скорость работы ЦП выше. Во время каждого такта завершается выполнение одной команды, поэтому ЦП выполняет не 100 млн., а 500 млн. операций в секунду.
Т.о. конвейер обеспечивает компромисс между временем ожидания (время выполнения одной команды) и пропускной способностью ЦП (число млн команд, выполняемых в секунду) При времени такта Т нс и числе стадий конвейера К время ожидания составит КТ нс, а пропускная способность 1000/Т млн. операций в секунду.
Конвейерный принцип выполнения команд
В соответствии с этим принципом процесс выполнения команды разбивается на ряд этапов. Рассмотрим его особенности на конкретном примере при следующих условиях [9]:
- • команда разбивается на шесть этапов:
- 1) выборка очередной команды (ВК);
- 2) декодирование выбранной команды (ДК);
- 3) формирование адреса операнда (ФА);
- 4) прием операнда из памяти (ПО);
- 5) выполнение операции (ВО);
- 6) размещение результата в памяти (PP);
В конвейере одновременно может находиться несколько (для рассматриваемого примера три) команд на разных этапах их выполнения. В идеальном варианте при полной загрузке конвейера однотипными командами на его выход в каждом такте будет поступать результат выполнения очередной команды (рис. 2.1,а,б). В этом случае производительность процессора (операций/с) будет равна его тактовой частоте (тактов/с).
Однако в реальных условиях отдельные ступени конвейера могут оказаться:
- • в состоянии ожидания (ОЖ), когда ступень не может выполнить требуемую микрооперацию из-за отсутствия необходимых данных. Например, не получен необходимый операнд, являющийся результатом выполнения предыдущей команды;
- • в состоянии простоя (ПР), когда ступень вынуждена пропустить очередной такт, так как поступившая команда не требует выполне-

Рис. 2.1. Конвейерный принцип выполнения команд
ния соответствующего этапа. Например, безадресные команды не требуют выполнения этапов формирования адреса (ФА) и приема операнда (ПО), поэтому ступени ФА и ПО конвейера будут находиться в состоянии простоя.
На рис. 2.1 ,я показан пример работы 6-ступенчатого конвейера для случая, когда при выполнении фрагмента реальной программы отдельные ступени оказываются в состоянии ожидания (ОЖ) или простоя (ПР).
Команда I инкрементации INC R2 (увеличивает содержимое регистра R2 на 1) не требует выборки операндов из памяти и размещения в ней результата. Поэтому при ее выполнении исполнительные ступени конвейера, выполняющие микрооперации ФА, ПО, PP, находятся в состоянии простоя (ПР).
Команда 2 означает пересылку содержимого ячейки памяти, адресуемой содержимым регистра R2, в регистр R3 – MOV (R2), R3. При ее выполнении реализуются состояния ожидания, пока в регистре R2 не будет получен результат предыдущей операции.
Команда 3.Т акты ожидания вводятся также при выполнении команды сложения ADD R3 (R4) до получения необходимого значения операнда в регистре R3.
Тактовая частота современных высокопроизводительных процессоров достигает нескольких гигагерц, и на выполнение одной микро-операции отводится время менее одной наносекунды. Поэтому процедура выполнения команд разбивается на более мелкие этапы и число ступеней конвейера увеличивается до 10 и более. Например, в микропроцессорах Pentium 4 используется 20-ступенчатый конвейер.
Эффективность использования конвейера определяется типом поступающих команд:
- • однородные команды сокращают число состояний простоя и ожидания в процессе их выполнения, в результате чего повышается производительность процессора;
- • разноформатные команды, содержащие различное количество байтов, имеют большое количество состояний простоя и ожидания. Поэтому принятый во многих RISC-процессорах стандартный 4-байтный формат команд обеспечивает существенное сокращение числа ожиданий и простоев конвейера, что позволяет значительно повысить производительность.
На эффективность использования конвейера влияют также команды ветвления (условных переходов). При выполнении условия ветвления необходимо перезагружать конвейер командами из другой ветви программы, что ведет к значительному снижению производительности процессора. Для сокращения числа перезагрузок конвейера используются различные способы предсказания ветвлений (Branch Prediction), реализуемых с помощью блоков предсказания ветвления, вводимых в структуру процессора.
Один из способов предсказания базируется на предположении, что при повторном обращении к команде условие ветвления сохраняется. Для реализации этого способа используется специальная память ВТВ (Branch Target Buffer – буфер флагов ветвлений), где хранятся адреса ранее выполненных условных переходов. При повторном поступлении команды ветвления предсказывается переход к ветви, которая была выбрана в предыдущем случае, и производится загрузка в конвейер команд из той же ветви. При правильном предсказании не требуется перезагрузка конвейера и эффективность его использования не снижается. Эффективность такого способа предсказания зависит от емкости ВТВ и оказывается достаточно высокой: вероятность правильного предсказания составляет 80% и более.
Повышение точности предсказания достигается при использовании более сложных способов, когда хранятся и анализируются результаты нескольких предыдущих команд ветвления по данному адресу (предыстория переходов).
Записки IT специалиста
Linux — начинающим. Часть 7. Потоки, перенаправление потоков, конвейер
- Автор: Уваров А.С.
- 28.10.2021
 После того, как вы освоили базовые принципы работы с Linux, позволяющие более-менее уверенно чувствовать себя в среде этой операционной системы, следует начать углублять свои знания, переходя к более глубоким и фундаментальным принципам, на которых основаны многие приемы работы в ОС. Одним из важнейших является понятие потоков, которые позволяют передавать данные от одной программы к другой, а также конвейера, позволяющего выстраивать целые цепочки из программ, каждая из которых будет работать с результатом действий предыдущей. Все это очень широко используется и понимание того, как это работает важно для любого Linux-администратора.
После того, как вы освоили базовые принципы работы с Linux, позволяющие более-менее уверенно чувствовать себя в среде этой операционной системы, следует начать углублять свои знания, переходя к более глубоким и фундаментальным принципам, на которых основаны многие приемы работы в ОС. Одним из важнейших является понятие потоков, которые позволяют передавать данные от одной программы к другой, а также конвейера, позволяющего выстраивать целые цепочки из программ, каждая из которых будет работать с результатом действий предыдущей. Все это очень широко используется и понимание того, как это работает важно для любого Linux-администратора.Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Прежде всего определимся с терминами. Мы часто говорим: «консоль», «терминал», «командная строка» — не сильно задумываясь о смысле этих слов и подразумевая под этим в большинстве своем CLI — интерфейс командной строки. Во многих случаях такое упрощение допустимо и широко используется в профессиональной среде. Но в данном случае точный смысл этих терминов имеет значение для правильного понимания происходящих процессов.
Стандартные потоки
Начнем с основного понятия — терминал. Он уходит корнями в далекое (по компьютерным меркам) прошлое и обозначает собой оконечное устройство, предназначенное для взаимодействия оператора и компьютера, к одному компьютеру может быть присоединено несколько терминалов, каждый из которых работает самостоятельно и независимо от других. Смысл современного терминала, а приложение для работы с командной строкой называется в Linux именно так, не изменился и сегодня, хотя, если быть точными, его название — эмулятор терминала.
Данное приложение все также эмулирует оконечное устройство, предназначенное для взаимодействия пользователя с компьютером. Точно также мы можем запустить сразу несколько терминалов, каждый из которых будет работать независимо. Кроме того, следует понимать, что терминал может быть запущен как локально, так и удаленно, способ подключения к компьютеру может быть разным, но свойства терминала от этого не изменяются.
Работая с терминалом нам нужно каким-то образом передавать ему команды и получать результаты. Для этого предназначена консоль — совокупность устройств ввода-вывода обеспечивающих взаимодействие пользователя и компьютера. В качестве консоли на современных ПК выступают клавиатура и монитор, но это только один из возможных вариантов, например, в самых первых моделях терминалов в качестве консоли использовался телетайп. Консоль всегда подключена к текущему рабочему месту, в то время как терминал может быть запущен и удаленно.
Но в нашей схеме все еще чего-то не хватает. При помощи консоли мы вводим определенные команды и передаем их в терминал, а дальше? Терминал — это всего лишь оконечное устройство для взаимодействия с компьютером, но не сам компьютер, выполнять команды или производить какие-либо другие вычисления он не способен. Поэтому на сцену выходит третий компонент — командный интерпретатор. Это специальная программа, обеспечивающая базовое взаимодействие пользователя и ОС, а также дающая возможность запускать другие программы. В большинстве Linux-дистрибутивов командным интерпретатором по умолчанию является bash.
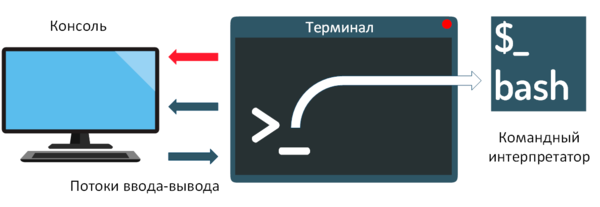
Теперь все становится на свои места. Для каждого сеанса взаимодействия пользователя и компьютера создается отдельный терминал, внутри терминала работает специальная программа — командный интерпретатор. При помощи консоли пользователь передает командному интерпретатору или запущенной с его помощью программе входящие данные и получает назад результат их работы. Осталось разобраться каким именно образом это происходит.
Для взаимодействия запускаемых в терминале программ и пользователя используются стандартные потоки ввода-вывода, имеющие зарезервированный номер (дескриптор) зарезервированный на уровне операционной системы. Всего существует три стандартных потока:
- stdin (standard input, 0) — стандартный ввод, по умолчанию нацелен на устройство ввода текущей консоли (клавиатура)
- stdout (standard output, 1) — стандартный вывод, по умолчанию нацелен на устройство вывода текущей консоли (экран)
- stderr (standard error, 2) — стандартный вывод ошибок, специальный поток для вывода сообщения об ошибках, также направлен на текущее устройство вывода (экран)
Как мы помним, в основе философии Linux лежит понятие — все есть файл. Стандартные потоки не исключение, с точки зрения любой программы — это специальные файлы, которые открываются либо на чтение (поток ввода), либо на запись (поток вывода). Это вызывает очевидный вопрос, а можно ли вместо консоли использовать файлы? Да, можно и здесь мы вплотную подошли к понятию перенаправления потоков.
Перенаправление потоков
Начнем с наиболее простого и понятного — потока вывода. В него программа отправляет результат своей работы, и он отображается на подключенном к консоли устройстве вывода, в современных системах это экран. Допустим мы хотим получить список файлов в директории, для этого мы набираем на устройстве ввода консоли команду:
Которая через стандартный поток ввода будет доставлена командному интерпретатору, тот запустит указанную программу и передаст ей требуемые аргументы, а результат вернет через стандартный поток вывода на устройство отображения информации.
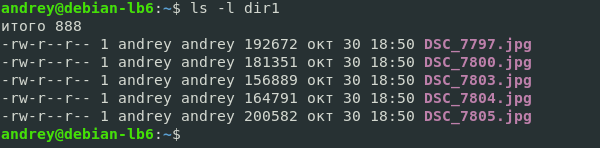
Но что, если мы хотим сохранить результат работы команды в файл? Нет ничего проще, воспользуемся перенаправлением, для этого следует использовать знак > .
На экран теперь не будет выведено ничего, но весь вывод команды окажется в файле result, который мы можем прочитать следующим образом:
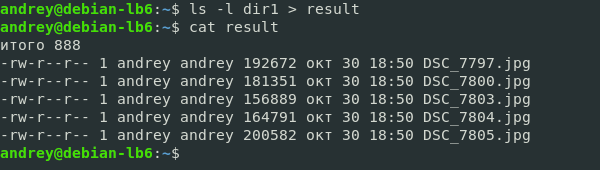
При таком перенаправлении вывода файл-приемник каждый раз будет создаваться заново, т.е. будет перезаписан. Это очень важный момент, сразу и навсегда запомните > — всегда перезаписывает файл!

Можно ли этого избежать? Можно, для того, чтобы перенаправленный поток был дописан в конец уже существующего файла используйте для перенаправления знак >> .
Немного изменим последовательность команд:
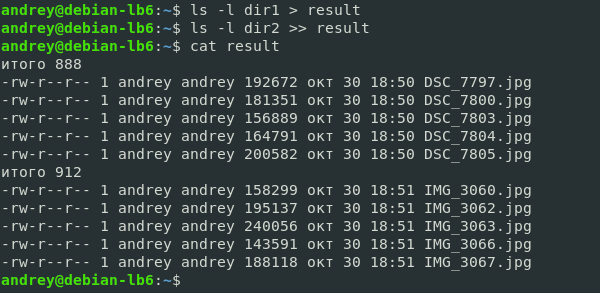
Теперь в файл попал вывод сразу двух команд, при этом, обратите внимание, первой командой мы перезаписали файл, а второй добавили в него содержимое из стандартного потока вывода.
Пойдем дальше. Как видим в выводе кроме списка файлов присутствуют строки «итого», нам они не нужны, и мы хотим от них избавиться. В этом нам поможет утилита grep, которая позволяет отфильтровать строки согласно некому выражению. Например, можно сделать так:
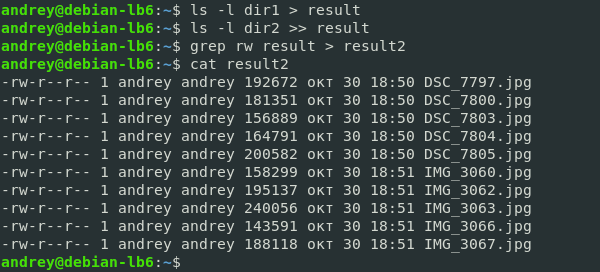
В целом результат достигнут, но ценой трех команд и наличием одного промежуточного файла. Можно ли сделать проще?
До этого мы перенаправляли поток вывода, но тоже самое можно сделать и с потоком ввода, используя для этого знак < . Например, мы можем сделать так:
Но это ничего не изменит, поэтому мы пойдем другим путем и перенаправим на ввод одной команды вывод другой:
На первый взгляд выглядит несколько сложно, но обратимся к man по grep:
В качестве паттерна мы используем rw, который есть в каждой интересующей нас строке, а в качестве файлов отдаем стандартный файл потока ввода, содержимого которого является результатом работы команды, указанной в скобках. А можно направить результат этой команды в файл? Конечно, можно:
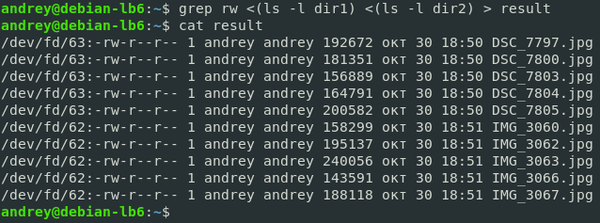
В последней команде мы перенаправили не только потоки ввода, но и поток вывода, при этом нужно понимать, что все перенаправления относятся к первой команде, иначе можно подумать, что в result будет выведен результат работы ls -l dir2, однако это неверно.
Немного особняком стоит стандартный поток вывода ошибок, допустим мы хотим получить список файлов несуществующей директории с перенаправлением вывода в файл, но сообщение об ошибке мы все равно получим на экран.

Почему так? Да потому что вывод ошибок производится в отдельный поток, который мы никуда не перенаправляли. Если мы хотим подавить вывод сообщений об ошибках на экран, то можно использовать конструкцию:
В данном примере весь вывод стандартного потока ошибок будет перенаправлен в пустое устройство /dev/null.
Но можно пойти и другим путем, перенаправив поток ошибок в стандартный поток вывода:

В этом случае мы перенаправили поток вывода об ошибках в стандартный поток вывода и сообщение об ошибке не было выведено на экран, а было записано в файл, куда мы перенаправили стандартный поток вывода.
Конвейер
В предыдущих примерах мы научились перенаправлять стандартные потоки ввода-вывода и даже частично коснулись вопроса о направлении вывода одной команды на вход другой. А почему бы и нет? Потоки стандартные, это позволяет использовать вывод одной команды как ввод другой. Это еще один очень важный механизм, позволяющий раскрыть всю мощь Linux в реализации очень сложных сценариев достаточно простым способом.
Для того, чтобы перенаправить вывод одной программы на вход другой используйте знак | , на жаргоне «труба».
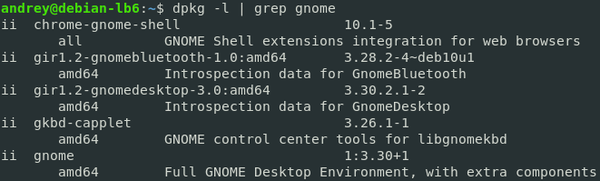
Самый простой пример:
Первая команда выведет список всех установленных пакетов, вторая отфильтрует только те, в наименовании которых есть строка «gnome».
Длинна конвейера ограничена лишь нашей фантазией и здравым смыслом, никаких ограничений со стороны системы в этом нет. Но также в Linuх нет и единственно верных путей, каждую задачу можно решить самыми различными способами. Возвращаясь к получению списка файлов двух директорий мы можем сделать так:
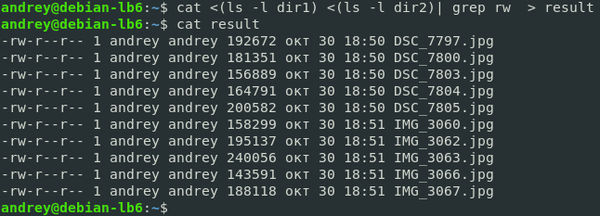
Какой из этих способов лучше? Любой, Linux ни в чем не ограничивает пользователей и предоставляет им много путей для решения одной и той же задачи.
Еще один важный момент, если вы повышаете права с помощью команды sudo, то данное повышение прав через конвейер не распространяется. Например, если мы решим выполнить:
То первая команда будет выполнена с правами суперпользователя, а вторая с правами запустившего терминал пользователя.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Дополнительные материалы:
Помогла статья? Поддержи автора и новые статьи будут выходить чаще:

Или подпишись на наш Телеграм-канал:

Конвейерная организация работы микропроцессора
Выполнение каждой команды складывается из ряда последовательных этапов, суть которых не меняется от команды к команде. С целью увеличения быстродействия процессора и максимального использования всех его возможностей в современных микропроцессорах используется конвейерный принцип обработки информации. Этот принцип подразумевает, что в каждый момент времени процессор работает над различными стадиями выполнения нескольких команд, причем на выполнение каждой стадии выделяются отдельные аппаратные ресурсы. По очередному тактовому импульсу каждая команда в конвейере продвигается на следующую стадию обработки, выполненная команда покидает конвейер, а новая поступает в него.
В различных процессорах количество и суть этапов различаются.
Рассмотрим принципы конвейерной обработки информации на примере пятиступенчатого конвейера, в котором выполнение команды складывается из следующих этапов:
- IF ( INsTRuction Fetch ) — считывание команды в процессор;
- ID ( INsTRuction DecodINg ) — декодирование команды;
- OR ( Operand ReadINg ) — считывание операндов;
- EX ( ExecutINg ) — выполнение команды;
- WB ( Write Back ) — запись результата.
Выполнение команд в таком конвейере представлено в табл. 9.1.
Таблица 9.1. Порядок выполнения команд в 5-ступенчатом конвейре
Команда Такт 1 2 3 4 5 6 7 8 9 i IF ID OR EX WB i+1 IF ID OR EX WB i+2 IF ID OR EX WB i+3 IF ID OR EX WB i+4 IF ID OR EX WB Оценка производительности идеального конвейера
Поскольку в каждом такте могут выполняться различные стадии обработки команд, длительность такта выбирается исходя из максимального времени выполнения всех стадий. Кроме того, следует учитывать, что для передачи команды с одной стадии обработки на другую требуется дополнительное время ( t), связанное с записью промежуточных результатов обработки в буферные регистры.
Пусть для выполнения отдельных стадий обработки требуются следующие затраты времени (в некоторых условных единицах):
TIF = 20, TID = 15, TOR = 20, TEX = 25, TWB = 20 .
Тогда, предполагая, что дополнительные расходы времени составляют t = 5 единиц, получим время такта :
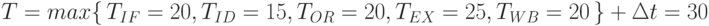
Таблица 9.2. Оценка эффективности конвейерной обработки
Количество команд Время при последовательном выполнении при конвейерном выполнении 1 100 150 2 200 180 10 1000 420 100 10000 3120
Значительное преимущество конвейерной обработки перед последовательной имеет место в идеальном конвейере, в котором отсутствуют конфликты и все команды выполняются друг за другом в установившемся режиме, то есть без перезагрузки конвейера. Наличие конфликтов в конвейере и его перезагрузки снижают реальную производительность конвейера по сравнению с идеальным случаем.