1. Случай 1
При использовании Keil для моделирования программы STM32 программа иногда убегает.Остановите программу моделирования и остановитесь в бесконечном цикле while (1) в функции HardFault_Handler. Это показывает, что STM32 имеет аппаратную ошибку.
1.1 Аппаратные ошибки STM32 могут иметь следующие причины:
- Операция с массивом вне границ;
- Переполнение памяти, доступ за пределы;
- Переполнение стека, сбой программы;
- Ошибка обработки прерывания;
- Переполнение памяти или доступ за пределы. Когда вам нужно написать свою собственную программу, вам нужно стандартизировать код.Если вы столкнетесь с ней, вам нужно будет медленно ее проверить.
- Переполнение стека. Увеличьте размер стопки.
1.2 Как устранить неполадки при возникновении проблем:
1. После возникновения исключения вы можете сначала проверить значение в регистре LR, чтобы определить, является ли текущий используемый стек MSP или PSP, затем найти указатель соответствующего стека и просмотреть содержимое соответствующего стека в памяти. Когда возникает исключение, ядро по очереди помещает в стек регистры R0
R3, R12, адрес возврата, PSR и LR, где адрес возврата — это адрес следующей инструкции, которая должна быть выполнена ПК до возникновения исключения, поэтому третья инструкция засчитывается в стеке обратно. Слово — это место ошибки.
2. Метод обработки HardFault_Handler по умолчанию — B. Измените его на форму прямого возврата BX LR. Затем нажмите точку останова в этом операторе, как только вы остановитесь на точке останова, это означает, что что-то пошло не так, а затем вернувшись, вы можете вернуться к следующему оператору, в котором произошла ошибка.
Иногда может потребоваться отладка в режиме дизассемблирования, поскольку HardFault_Handler может появиться после того, как программа на некоторое время завершит работу.
3. Измените функцию прерывания и распечатайте некоторую информацию при прерывании:
CPSR Текущий государственный регистр программы (Current Program State Register)
SPSR Имеется шесть регистров сохраненного состояния программы (Saved Program State Register), которые в основном используются при обработке исключений.
В каждом режиме процессора имеется специальный физический регистр в качестве регистра состояния программы резервного копирования SPSR. Когда возникает определенное исключение, этот физический регистр отвечает за сохранение содержимого регистра текущего состояния программы CPSR. Когда обработчик исключения возвращается, тогда Восстановите содержимое на устройстве текущего состояния программы и продолжите выполнение исходной программы.
PC Программный счетчик используется для подсчета, указывая место хранения инструкции в памяти, которая является адресной информацией.
1.3 Есть две основные причины ошибки HardFault_Handler в STM32:
Как устранить неполадки при возникновении проблем:
После возникновения исключения вы можете сначала проверить значение в регистре LR, чтобы определить, является ли текущий используемый стек MSP или PSP, затем найти указатель соответствующего стека и просмотреть содержимое соответствующего стека в памяти. Когда возникает исключение, ядро последовательно помещает регистры R0
R3, R12, LR, PC и XPRS в стек, где LR — адрес следующей инструкции, которую ПК выполнит до возникновения исключения.
Примечание: все регистры 32-битные, а STM32 находится в режиме прямого порядка байтов. (Ссылка на Cortex-M3)
Значение SP — 0x20008560, а значения в стеке — R0
R3, R12, LR, PC, XPRS, например R0 (10 27 00 00). Очевидно, что байты с 21-го по 24-й после стека являются LR. Адрес 0x08001FFD — это адрес следующей инструкции, которую ПК выполнит перед исключением (то есть RCC-> CR & = (uint32_t) 0xFFFBFFFF в инструкции, следующей за StackFlow ())
Значение SP равно 0x20001198, а значения в стеке — R0
R3, R12, LR, PC, XPRS, например R0 (10 27 00 00). Очевидно, что байты с 21-го по 24-й после стека являются LR. Адрес 0x08003B61 — это адрес следующей инструкции, которую ПК выполнит перед исключением (то есть RCC-> CR & = (uint32_t) 0xFFFBFFFF в инструкции, следующей за StackFlow ())



2. Случай 2
После возникновения исключения мы можем сначала проверить значение регистра LR, подтвердить, является ли текущий используемый стек MSP или PSP, затем найти соответствующий указатель стека и просмотреть содержимое соответствующего стека в памяти, ядро будет R0
R3, R12, LR , Регистры PC и XPRS по очереди помещаются в стек, где LR — адрес следующей инструкции, которую ПК выполнит до возникновения исключения.
Тогда методы отладки и позиционирования ошибок HardFault ядра Cortex-M3:
2.1 Метод 1 Как точно определить местоположение кода проблемы:
В качестве примера возьмем трансграничный доступ: (имитируйте EEPROM для внутренней флэш-памяти STM32F103C8T6)
#define STM32_FLASH_SIZE 64
#define STM32_FLASH_WREN 1
#define FLASH_SAVE_ADDR 0X08078000
#define FLASH_HIS_ADDR 0X08078002
FLASH_SAVE_ADDR — это базовый адрес для начала хранения. Размер внутренней флэш-памяти STM32F103C8T6 составляет 64 КБ. Адрес внутренней флэш-памяти (FLASH) STM32 начинается с 0x08000000. Как правило, программа начинает запись с этого адреса. Следовательно, конечный адрес STM32F103C8T6 должен быть 64 * 1024, преобразованный в шестнадцатеричный, а результат, полученный путем добавления базового адреса флэш-памяти микроконтроллера, равен 0x08010000, тогда указанная выше установка кода FLASH_SAVE_ADDR на 0X08078000 выходит за рамки микроконтроллера, поэтому, если вы используете это Когда микроконтроллер управляет флеш-памятью, произойдет ошибка, если адрес будет записан или прочитан. Теперь предположим, что вы работаете с этим адресом без вашего ведома, а затем вводите его, когда программа работает.
HardFault_Handler прерван. Затем, чтобы узнать, где находится код ошибки, вы можете использовать следующий метод (отладка программного обеспечения MDK):
1: войдите в интерфейс отладки и поместите точку останова в while (1) HardFault_Handler.
3: Подождите, пока код дойдет до этого, затем проверьте регистр LR
Если он работает нормально, отображаемый регистр похож на следующий рисунок:
После возникновения исключения вы можете сначала проверить значение в регистре LR, чтобы определить, является ли текущий используемый стек MSP или PSP, затем найти указатель соответствующего стека и просмотреть содержимое соответствующего стека в памяти. В авторитетном руководстве Cortex_M3 вы можете увидеть следующую картинку:

Из этого рисунка видно, что функция этого побитового ИЛИ состоит в том, чтобы установить младшие 4 бита регистра R14 в D. После возврата этого исключения он переходит в режим потока и использует стек потоков PSP, потому что режим потока должен использоваться при выполнении задачи. Только при возникновении прерывания или исключения позвольте системе войти в режим обработки и использовать MSP.
Причина, по которой в xPortPendSVHandler нет строки, заключается в том, что перед вводом исключения система запускает задачу, используя режим потока и PSP, после ввода исключения она становится режимом обработки и MSP, но автоматически вернется к этому, когда исключение вернется. Режим до возникновения исключения — это режим потока и PSP.
Перед вызовом функции vPortSVCHandler система находилась в режиме обработки и использовала MSP. (Поскольку после сброса он находится в режиме Handle, большинство проектов STM32, которые не используют систему, запускаются в самом высоком режиме Handle.)
Я вижу, что значение в регистре LR равно 0xFFFFFFFD, поэтому я должен посмотреть на адрес PSP, найти адрес адреса, а затем открыть память, как показано на рисунке ниже, ввести адрес регистра, указанный выше, щелкнуть правой кнопкой мыши и выбрать длинный, чтобы просмотреть адрес, как показано ниже:

Затем посмотрите на этот адрес и отсчитайте шесть длинных адресов. Почему существует шесть длинных адресов? Потому что, когда возникает исключение, ядро последовательно помещает регистры R0
R3, R12, Returnaddress, PSR и LR в стек, где адрес возврата — это вхождение Адрес следующей инструкции, которую ПК выполнит перед исключением;
Вероятно, 0x08xxxxxx — это расположение кода ошибки, который можно разобрать для просмотра, как показано на следующем рисунке:

Видно, что соответствующая программа на языке C имеет ошибку при чтении функции FLASH, поэтому ее можно расценить как проблему нарушения доступа.

2.2 Метод 2: самый простой и очевидный
В состоянии отладки после входа в точку останова HardFault в строке меню Peripherals> Core Peripherals> FaultReports открывается отчет об аномальном возникновении, чтобы просмотреть причину сбоя.

В приведенном выше отчете произошел сбой шины, и служба прерывания сбоя была переведена в режим жесткого сбоя.
Более важно определить местонахождение аномалии, чем обнаружить аномалию.
(1) Откройте окно стека вызовов (как показано на рисунке ниже, точка останова останавливается в служебной программе Hard Fault)



2.3 Метод 3: этот метод примерно такой же, как и метод 1
Далее описывается, как обнаружить отклонения в программе.

Затем в проекте keil_MDK скомпилируйте код, выполните отладку и затем запустите на полной скорости, вы можете увидеть, что программа входит в исключение HardFault, как показано на рисунке ниже.

Как показано ниже, мы находим регистр SP, 0x200045B8 — это адрес стека, а значения в стеке — R0
R3, R12, PC (адрес возврата), xPSR (CPSR или SPSR), LR. Как показано на рисунке, мы видим место, где проведена красная линия, обратите внимание на то, чтобы смотреть справа налево. Это 0x0800427D и 0x08004BFA.

Введите 0x08004BFA в коде показа по адресу и нажмите «Перейти к», чтобы найти программу, которая будет выполняться рядом с сегментом аномального кода

Мы используем тот же метод, чтобы ввести 0x0800427D в код показа по адресу и найти следующий сегмент кода

Можно обнаружить, что аномальный код находится в функции uart_send_noackdata.В этой функции мы определяем указатель и начинаем его использовать, не выделяя для него места. Из этого мы освоили первый метод поиска аномалий. Просто запишите содержимое байтов с 21-го по 24-й и с 25-го по 28-й в стек, чтобы легко найти код исключения. Ниже описывается использование файла .map для поиска аномалий. Файл .map автоматически создается в проекте keil при компиляции программы.
В файле .map мы искали 0x08004BFA и обнаружили, что 0x08004bd8 указывает на функцию uart_send_noackdata.Пока мы нашли местоположение аномального кода.

Из этого мы знаем, что нам нужно только найти адрес памяти в регистрах ПК (адрес возврата) и xPSR (CPSR или SPSR) в стеке, чтобы найти код исключения.

CPSR
Текущий государственный регистр программы (Current Program State Register)
SPSR
Имеется 6 регистров сохраненного состояния программы (Saved Program State Register), которые в основном используются при обработке исключений.
В каждом режиме процессора есть специальный физический регистр в качестве регистра состояния программы резервного копирования SPSR. Когда возникает конкретное исключение, этот физический регистр отвечает за сохранение содержимого регистра текущего состояния программы CPSR. Когда обработчик исключения возвращается, тогда Восстановите содержимое на устройстве текущего состояния программы и продолжите выполнение исходной программы.
PC
Программный счетчик используется для подсчета, указывая место хранения инструкции в памяти, которая является адресной информацией.
Что делать, если поймал HardFault?
Что делать, если поймал HardFault? Как понять, каким событием он был вызван? Как определить строчку кода, которая привела к этому? Давайте разбираться.
Всем привет! Сложно найти программиста микроконтроллеров, который ни разу не сталкивался с тяжелым отказом. Очень часто он никак не обрабатывается, а просто остаётся висеть в бесконечном цикле обработчика, предусмотренном в startup файле производителя. В то же время программист пытается интуитивно найти причину отказа. На мой взгляд это не самый оптимальный путь решения проблемы.
В данной статье я хочу описать методику анализа тяжелых отказов популярных микроконтроллеров с ядром Cortex M3/M4. Хотя, пожалуй, «методика» — слишком громкое слово. Скорее, я просто разберу на примере то, как я анализирую возникновение тяжелых отказов, и покажу, что можно сделать в подобной ситуации. Я буду использовать программное обеспечение от IAR и отладочную плату STM32F4DISCOVERY, так как эти инструменты есть у многих начинающих программистов. Однако это совершенно не принципиально, данный пример можно адаптировать под любой процессор семейства и любую среду разработки.

Падение в HardFault
Перед тем, как пытаться анализировать HatdFault, нужно в него попасть. Есть много способов это сделать. Мне сразу же пришло на ум попытаться переключить процессор из состояния Thumb в состояние ARM, путем задания адреса инструкции безусловного перехода четным числом.
Небольшое отступление. Как известно, микроконтроллеры семейства Cortex M3/M4 используют набор ассемблерных инструкций Thumb-2 и всегда работают в режиме Thumb. Режим ARM не поддерживается. Если попытаться задать значение адреса безусловного перехода(BX reg) со сброшенным младшим битом, то произойдет исключение UsageFault, так как процессор будет пытаться переключить своё состояние в ARM. Подробнее об этом можно почитать в [1](пункты 2.8 THE INSTRUCTION SET; 4.3.4 Assembler Language: Call and Unconditional Branch).
Для начала, я предлагаю смоделировать безусловный переход по четному адресу на языке C/C++. Для этого я создам функцию func_hard_fault, затем попытаюсь вызвать ее по указателю, предварительно уменьшив адрес указателя на единицу. Сделать это можно следующим образом:
Посмотрим с отладчиком, что же у меня получилось.

Красным я выделил текущую инструкцию перехода по адресу в РОН R1, который содержит чётный адрес перехода. Как результат:

Еще проще данную операцию можно выполнить с помощью ассемблерных вставок:
Ура, мы попали в HardFault, миссия выполнена!
Анализ HardFault
Откуда мы попали в HardFault?
На мой взгляд, самое важное — узнать то, откуда мы попали в HardFault. Сделать это не сложно. Для начала напишем свой обработчик ситуации HardFault.
Теперь поговорим о том, как выяснить, как мы здесь оказались. В процессорном ядре Cortex M3/M4 есть такая замечательная вещь, как сохранение контекста [1](пункт 9.1.1 Stacking). Если говорить простым языком, при возникновении любого исключения, содержимое регистров R0-R3, R12, LR, PC, PSR сохраняется в стеке.

Здесь для нас самым важным будет регистр PC, который содержит информацию о текущей выполняемой инструкции. Так как значение регистра было сохранено в стек во время возникновения исключительной ситуации, то там будет содержаться адрес последней выполняемой инструкции. Остальные регистры менее важны для анализа, но нечто полезное можно выцепить и из них. LR — адрес возврата последнего перехода, R0-R3, R12 — значения, которые могут подсказать в каком направлении двигаться, PSR — просто общий регистр состояния программы.
Предлагаю выяснить значения регистров в обработчике. Для этого был написал такой код (подобный код я встречал в одном из файлов производителя):
Как результат, имеем значения всех сохраняемых регистров:
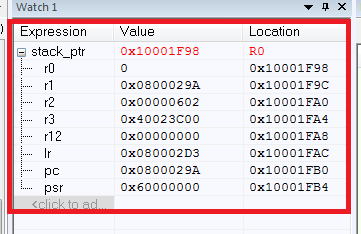
Что же здесь произошло? Сначала мы завели указатель стека stack_ptr, тут все понятно. Сложности возникают с ассемблерной вставкой (если есть потребность в понимании ассемблерных инструкций для Cortex, то рекомендую [2]).
Почему мы просто не сохранили стек через MRS stack_ptr, MSP? Дело в том, что ядра Cortex M3/M4 имеют два указателя стека [1](пункт 3.1.3 Stack Pointer R13) — основной указатель стека MSP и указатель стека процесса PSP. Они используются для разных режимов работы процессора. Не буду подробно углубляться в то, для чего это сделано и как это работает, однако дам небольшое пояснение.
Для выяснения режима работы процессора(используется в данный MSP или PSP), нужно проверить третий бит регистра связи. Этот бит определяет то, какой указатель стека используется для возвращения из исключения. Если этот бит установлен, то это MSP, если нет, то PSP. В целом, большинство приложений, написанных на C/C++ используют только MSP, и эту проверку можно и не делать.
Так что же по итогу? Имея список сохраняемых регистров, мы можем без труда определить то, откуда программа упала в HardFault по регистру PC. PC указывает на адрес 0x0800029A, который и является адресом нашей «ломающей» инструкции. Не стоит также забывать о важности значений остальных регистров.
Причина возникновения HardFault
На самом деле, мы можем также выяснить причину возникновения HardFault. В этом нам помогут два регистра. Hard fault status register (HFSR) и Configurable fault status register (CFSR; UFSR+BFSR+MMFSR). Регистр CFSR состоит из трёх регистров: Usage fault status register (UFSR), Bus fault status register (BFSR), Memory management fault address register (MMFSR). Почитать про них можно, например, в [1] и [3].
Предлагаю посмотреть, что эти регистры выдают в моём случае:

Во-первых, установлен бит HFSR FORCED. Значит произошёл отказ, который не может быть обработан. Для дальнейшей диагностики следует изучить остальные регистры статуса отказов.
Во-вторых, выставлен бит CFSR INVSTATE. Это значит, что произошёл UsageFault, так как процессор попытался выполнить инструкцию, которая незаконно использует EPSR.
Что такое EPSR? EPSR — Execution program status register. Это внутренний регистр PSR — специального регистра состояния программы(который, как мы помним, сохраняется в стеке). Двадцать четвертый бит этого регистра указывает на текущее состояние процессора (Thumb или ARM). Это как раз может определять нашу причину возникновения отказа. Давайте попробуем его считать:
В результате выполнения получаем значение EPSR = 0.

Получается, что регистр показывает состояние ARM и мы нашли причину возникновения отказа? На самом деле нет. Ведь согласно [3](стр. 23), считывание этого регистра с помощью специальной команды MSR всегда возвращает нуль. Мне не очень понятно почему это работает именно так, ведь этот регистр и так только для чтения, а тут его полностью и считать нельзя(можно только некоторые биты через xPSR). Возможно это некие ограничения архитектуры.
По итогу, к сожалению, вся эта информация практически ничего не дает рядовому программисту МК. Именно поэтому я рассматриваю все данные регистры только как дополнение к анализу сохраненного контекста.
Однако, например, если отказ был вызван делением на нуль(данный отказ разрешается установкой бита DIV_0_TRP регистра CCR), то в регистре CFSR будет выставлен бит DIVBYZERO, что укажет нам на причину возникновения этого самого отказа.
Что дальше?
Что же можно сделать после того, как мы проанализировали причину возникновения отказа? Мне кажется хорошим вариантом такой порядок действий:
Hardfault handler stm32 как бороться
Ядро ARM Cortex-M реализует набор исключений отказов (fault exceptions). Каждое исключение относится к определенному условию возникновения ошибки. Если ошибка произошла, то ядро ARM Cortex-M останавливает выполнение текущей инструкции и делает ветвление на функцию обработчика исключения (exception handler). Этот механизм очень похож на тот, который используется для прерываний, где ядро ARM Cortex-M делает ветвление на обработчик прерывания (interrupt handler, ISR), когда принимает прерывание.
CMSIS определяет следующие имена для обработчиков отказов (fault handlers):
UsageFault_Handler()
BusFault_Handler()
MemMang_Handler()
HardFault_Handler()
Перечисление всех причин и обстоятельств, при которых ядро ARM Cortex-M вызывает каждый из этих обработчиков, выходит за рамки этого документа (перевод статьи [1]). См. литературу по ARM Cortex-M для ARM и разные другие источники, если нужны подробности. Ошибки типа HardFault встречаются наиболее часто, поскольку другие типы отказов, не разрешенные по отдельности, пройдут эскалацию, чтобы превратиться в hard fault.
Несмотря на многочисленные запросы поддержки RTOS, когда люди жаловались, что при использовании ядра RTOS, их приложение падает в обработчик ошибки hard fault, причина аппаратного сбоя оказывалась вовсе не в ядре. Обычно это было одно из следующего:
• Неправильное понимание приоритетов прерываний ядра ARM Cortex-M (эту оплошность допустить весьма просто!), или неправильное понимание, как использовать модель вложенности прерываний FreeRTOS (см. [2]).
• Общая пользовательская ошибка RTOS. См. статью FAQ «My Application Does Not Run – What Could Be Wrong» [3], специально написанную для помощи в подобных случаях.
• Баг в коде приложения.
Отладка ошибки Hard Fault должна начаться с проверки, что программа приложения следует руководствам [2, 3]. Если после этого ошибка hard fault все еще не исправлена, то необходимо определить состояние системы (system state) в момент времени, когда произошел сбой. Отладчики не всегда упрощают эту задачу, поэтому остальная часть этой статьи описывает техники программирования, используемые для отладки.
[Какой Exception Handler выполнился?]
В таблице векторов прерываний обычно устанавливается один и тот же обработчик для каждого источника прерывания/исключения. Обработчики по умолчанию (default handlers) декларируются как weak-символы (код заглушки), чтобы разработчик приложения мог установить свой собственный обработчик простой реализацией функции с корректным именем. Если произошло прерывание, для которого разработчик приложения не предоставил свой отдельный обработчик, то будет выполнен обработчик по умолчанию (default handler).
[weak-функции на ассемблере]
Символ weak это по сути метка с указанием на код, который может быть при необходимости переопределен простым созданием функции с таким же именем. К примеру, weak-обработчики прерываний проекта IAR для STM32, сгенерированного с помощью STM32CubeMX, для микроконтроллера STM32F407 в коде запуска startup_stm32f407xx.s ;будут выглядеть примерно так (weak-обработчики отказов выделены жирным шрифтом):
В модуле кода (это тоже автоматически сгенерированный код) заглушки обработчиков отказов выглядят следующим образом:
[weak-функции на языке C]
Обработчики по умолчанию обычно реализуются как бесконечный цикл. Если приложение заканчивает работу на таком default handler, то сначала необходимо определить, где именно произошло прерывание выполнения кода.
Следующий кусок кода демонстрирует, как добавить несколько инструкций к бесконечному циклу обработчика по умолчанию, чтобы загрузить номер выполняющегося прерывания в регистр 2 (r2) перед входом в бесконечный цикл.
Номера прерываний здесь считываются из NVIC относительно начала таблицы векторов, в которой есть записи для системных исключений (таких как hard fault), они находятся выше записей прерываний периферийных устройств. Если в r2 находится значение 3, то обработано исключение hard fault. Если r2 содержит значение, равное или больше 16, то это обрабатывается прерывание периферии, и периферийное устройство, которое вызвало прерывание, можно определить вычитанием 16 из номера прерывания.
[Отладка ARM Cortex-M Hard Fault]
Окно стека (stack frame) обработчика fault handler содержит состояние регистров ARM Cortex-M в момент времени, когда произошла ошибка. Код ниже показывает, как прочитать значения регистров из стека в переменные C. Когда это сделано, значения этих переменных могут быть проинспектированы в отладчике точно так же, как и другие переменные.
Сначала определяется очень короткая функция на ассемблере, чтобы определить, какой стек использовался, когда произошла ошибка. Как только это выполнено код ассемблера fault handler передает указатель на стек в C-функцию с именем prvGetRegistersFromStack() .
Обработчик fault handler показан ниже в синтаксисе GCC. Обратите внимание, что функция была декларирована как naked, так что она не содержит никакого кода, генерированного компилятором (например, здесь нет кода пролога входа в функцию).
Реализация функции prvGetRegistersFromStack() показана ниже. Она копирует значения из стека в переменные C, после чего падает в цикл. Имена переменных выбраны, в соответствии с именами регистров, чтобы было проще проанализировать значения, считанные из соответствующих регистров. Другие регистры не будут изменяться с момента возникновения ошибки, и их можно просмотреть в окне отображения регистров CPU отладчика.
[Использование значений регистров]
Самый первый из интересующих регистров это программный счетчик. В показанном выше коде переменная pc как раз и содержит значение программного счетчика. Когда ошибка это точный отказ (precise fault), pc хранит адрес инструкции, которая была выполнена, когда произошла ошибка hard fault (или другой fault). Когда ошибка это неточный отказ (imprecise fault), то требуются дополнительные шаги, чтобы найти адрес инструкции, которая привела к ошибке.
Чтобы найти инструкцию по адресу которая хранится в переменной pc, сделайте одно из следующего.
1. Откройте окно кода ассемблера (точнее дизассемблированного кода) в отладчике, и вручную введите значение адреса из переменной pc, чтобы посмотреть инструкции по этому адресу.
2. Откройте окно точек останова (break point) в отладчике, и вручную определите точку останова (break point) на этом адресе (execution break) или точку останова по доступу (access break) к этому адресу. С установленной break point перезапустите приложение, чтобы увидеть строку кода, относящуюся к адресу инструкции, которая соответствует переменной pc.
Когда известна инструкция, которая была выполнена при возникновении fault, можно узнать интересующие значения в других регистрах. Например, если инструкция использовала значение R7 в качестве адреса, то нужно знать значение R7. В будущем, анализируя код ассемблера и код C, из которого был сгенерирован этот ассемблерный код, можно увидеть, что реально содержится в R7 (например, это может быть значение переменной).
[Как разобраться с неточным отказом]
Отказы (faults) платформы ARM Cortex-M могут быть точными (precise fault) или неточными (imprecise fault). Если установлен бит IMPRECISERR (бит 2) в регистре отказа шины (BusFault Status Register, или BFSR , который доступен как байт по адресу 0xE000ED29), то это сигнал неточного отказа (imprecise fault).
Обнаружить причину imprecise fault сложнее, потому что fault не обязательно будет происходить одновременно с выполнением инструкции, приведшей к отказу. Например, если идет кэшированная запись в память, то может быть задержка между инструкцией ассемблера, инициировавшей запись в память, и реальной операцией записи в память. Если такая отложенная запись в память недопустима (например, попытка записи в несуществующую физически память) то произойдет imprecise fault, и значение программного счетчика, полученного с помощью вышеуказанного примера кода, не будет соответствовать адресу инструкции, которая инициировала недопустимую операцию записи.
В примере, показанном выше, выключите буферизацию записи установкой бита DISDEFWBUF (бит 1) в регистре ACTLR (Auxiliary Control Register), что в результате превратит imprecise fault в precise fault, и это упростит отладку ценой замедления выполнения программы.
Hardfault handler stm32 как бороться
mainly has two aspects:
1. Memory overflow or access out of range. When you need to write your own program, you need to standardize the code. If you encounter it, you need to check it slowly.
2. Stack overflow. Increase the size of the stack.
Troubleshooting method for HardFault_Handler fault in STM32:
method one
After an exception occurs, you can first check the value in the LR register, make sure that the currently used stack is MSP or PSP, and then find the pointer of the corresponding stack, and view the contents of the corresponding stack in the memory. When an exception occurs, the kernel pushes the R0
R3, R12, Returnaddress, PSR, and LR registers into the stack in turn, where the Return address is the address of the next instruction that the PC will execute before the exception occurs.
Note: The registers are all 32 bits, and STM32 is in little-endian mode. (Reference Cortex-M3 authority)

Write the problem code as follows:
DEBUG is as shown below
SP value is 0x20008560, the values in the stack are R0
R3, R12, Return address, PSR, LR, for example R0 (1027 00 00), obviously the 21st word after the stack Section to 24 bytes is the Returnaddress, and the address 0x08001FFD is the address of the next instruction that the PC will execute before the exception (that is, the statement after StackFlow() at RCC->CR &= (uint32_t)0xFFFBFFFF)

Method Two
The default HardFault_Handler processing method is not B. Is this an endless loop? The host changed it to the form of BXLR direct return. Then hit a breakpoint at this statement, once you stop at the breakpoint, it means that something went wrong, and then return, you can return to the next statement where the error occurred.
Fault of Cortex-M3/4
Cause and type
Cortex-M3/4 fault exceptions are usually caused by illegal memory access (such as accessing address 0, writing read-only memory locations, etc.) and illegal program behavior (such as dividing by 0, etc.).
The 4 common types of abnormalities and the abnormalities are as follows:
BusFault: In the case of fetch instruction, data read and write, fetch interrupt vector or store and restore register stack during interrupt, a BusFault is generated when a memory access error is detected.
Memory ManagementFault: Access to an illegal memory area defined by the memory management unit (MPU), such as writing data to a read-only area.
UsageFault: An undefined instruction is detected or there is misalignment when accessing memory. You can also configure the software to check whether other than 0 and other unaligned memory accesses also generate this exception. It is disabled by default and needs to be configured during project initialization:
HardFault: In the process of debugging a program, this abnormality is most common. The occurrence of any of the above three exceptions will cause HardFault. When the above three exceptions are not enabled, the HardFault interrupt service routine is entered by default when an exception occurs. The first three exceptions should also be configured during initialization:
★★★In the default reset initialization, HardFault is enabled, and the other three are not enabled. Therefore, when there is an illegal memory access (usually caused by pointer errors) or illegal program behavior (usually divided by 0 in mathematics) ) Will generate a HardFault interrupt.
HardFault debugging method
Detect abnormal type
Assuming that the IDE environment is Keil and the chip is STM32F103.
In stm32f10x_it.c, add a software breakpoint, once a Hard Fault occurs during debugging, it will stop at __breakpoint(0).
After entering the HardFault breakpoint, the menu bar Peripherals>Core Peripherals>FaultReports opens the report of the abnormal occurrence to view the cause of the abnormality.


The above report has occurred BUS FAULT, and the fault interrupt service is turned to Hard Fault.
Abnormal positioning
It is more important to locate the location of the abnormality than to detect the abnormality.
(1) Open the Call Stack window (the left side of the figure below, the breakpoint stops in the Hard Fault service program)

(2) Right-click Show CallerCode on HardFault_Handler of Call Stack (some Keil versions can also be directly double-clicked)

will then jump to the source code location where the exception occurred (as shown in the figure above). The exception occurred on the line p->hour=0. The error here is obvious: the pointer p has not allocated memory space for member variables, and it must be an error to directly access the unallocated inner coarse space.
Two more points:
[1] In complex situations, it is difficult to easily correct the error even if the location of the abnormality is located. Learn to use the Watch window to track the pointer variable where the error occurs;
[2] When the problem is not clear, try to analyze the disassembly code, and I encountered it. In some cases, the exception occurred at the jump instruction such as BL, and the BL jumped An exception occurs when an illegal memory address is reached
Refrences
[1] Application Note209. Using Cortex-M3 and Cortex-M4 FaultExceptions.
[2] The Definitive Guide to Cortex-M3