Укрощая зверя: legacy-код, тесты и вы
Legacy-код — это «старый» код, возраст которого может быть как 2 месяца, так и 10 лет. Часто его писали разработчики, о которых в компании смутно помнят. Возможно, их вообще не было, а legacy-код родился вместе со Вселенной во время Большого Взрыва. С тех пор требования к нему менялись много раз, код правили в режиме «нужно было еще вчера», а документацию никто не писал, как и тесты. Legacy-код запутан и хрупок, в нем не видно ни начала, ни конца. Как к нему подступиться?
Здесь и далее кадры из сериала «Рик и Морти». Авторы Джастин Ройланд и Дэн Хармон.
Подбираться к нему нужно с тестов, но готовьтесь к боли. Проблемы начнутся уже с того момента, как вы решите взяться за такой проект. Вам нужно понять, зачем вы хотите за него браться, убедить руководство одобрить тестирование legacy-кода, а коллег — помочь. После этого возникнут вопросы, с чего начать изучение, какие тесты запустить первыми и как все не сломать? Но главное — как не впасть в отчаяние, когда поймете, что работе нет конца.
Кирилл Борисов 12 лет в индустрии, за эти годы прошел долгий путь по костылям, битому коду и гниющим каркасам старых систем: от монолитных учетных систем до микросервисов авторизации. Путешествие наградило его опытом и историями, которыми он поделится в виде ценных советов.
У меня есть мечта — когда-нибудь поработать над новым проектом. В нем все будет хорошо с самого начала и свежо, как первый снег: тесты, архитектура и смысл. Но это лишь мечта, потому что уже 10 лет я продаю свой талант за деньги и перехожу из одного legacy-проекта к другому.
За это время у меня не осталось нервов, но я могу сберечь ваши, поделившись своим опытом взаимодействия с legacy. Я расскажу, как укрощать зверя (legacy-код): работать с кодом и людьми, внедрять тестирование, нужно ли это делать и как к этому относятся и разработчики.
Чего здесь не будет:
- Советов, как писать тесты. Множество книг, статей и разных видео закрывают этот вопрос.
- Обсуждения методологий. BDD, TDD, ATDD — все на ваше усмотрение.
- Всего, что может нарушить NDA. У людей долгая память, а у юристов — длинные руки.
Что такое legacy-код
Определений много. Я считаю, что это «достаточно старый» код возрастом от 2 месяцев до 10 лет. Legacy-код запутан и хрупок, но как гигантский змей пожирает свой хвост.
Именно это не позволяет начать его спокойно тестировать. Все разработчики, от начинающих до опытных, когда приходят на legacy-проект, хватаются за копье тестов и несутся убивать это чудовище. Копье ломается, а вместе с ним люди. В итоге остается разработчик без признаков жизни, который работает на legacy-проекте десятки лет.
Возможно ли побороть этого зверя? Да, но нужна подготовка.
Подготовка
Борьба со зверем не так важна, как подготовительный этап. Он начинается с трех вопросов самому себе.

«Зачем я это делаю?» Серьёзно, зачем? Ведь варианта всего два.
- Вы хотите славы, чтобы люди говорили, как вы великолепны, потому что внедрили тесты.
- Чтобы облегчить жизнь себе, коллегам и компании.
«Знаю ли я, что делаю?» Если вы писали тесты, то знаете. Если нет, то прежде чем бросаться на монстра, овладейте азами: напишите 3-4 теста, покройте небольшую часть кода, набейте руку и почувствуйте силу.
«Есть ли у меня на это время?» Замечательнос благими порывами вмешиваться в код и улучшать его, работая на будущее. Но, возможно, на это нет времени, когда горит настоящее. Если так, то проекту нужны вы, а не светлый образ будущего.
Когда вы ответите на все вопросы утвердительно — переходите к следующему этапу.
Разведка местности
Изучите структуру проекта. У вас есть представление о структуре проекта, составных частях и принципе работы? Наверняка да, но, возможно, оно не совпадает с реальностью. Важно понимать, с чем придется столкнуться перед началом работы. Посвятите немного времени, чтобы пройтись по проекту и изучить его досконально.
Составьте схему зависимостей. Ни один проект не живет в вакууме. Базы данных, внешние сервисы, библиотеки — все это может использоваться в проекте.
Что сделано до вас? Возможно, вы не первый, кто боролся со зверем. Изучите наработки «предков», которые сгорели и ушли с проекта.
После разведки переходим к боевым действиям.
Борьба с организацией
Первый раунд — борьба с вашей организацией. Главный в ней — ваш менеджер, непосредственный начальник.
Менеджер. Он не так страшен, как кажется. Это обычный человек с обычными потребностями: сдать проект вовремя и без лишних проблем, получить за это деньги и бонусы и жить дальше.
Руководитель не против ваших начинаний. Он против того, чтобы вы кидались на проект с криками: «Тесты! Тесты! Тесты!». Если будете так делать, он посмотрит на вас как на человека, который тратит его время и тормозит остальных.
Покажите пользу. Менеджер говорит на языке пользы, времени и денег. Поймите, что им движет желание закрыть проект в срок и получить больше результата за меньшие ресурсы.
Тест не стоит подавать так:
— О, это будет круто!
Свои идеи надо продвигать так:
— В прошлом квартале у нас было 50 падений, которые можно было исправить на стадии разработки продукта. Исправить можно с помощью тестов. Они подтвердят, что внесённые изменения не изменили функционал, если мы того не ожидаем. Мы сэкономим часы, потраченные на устранение этих проблем и снизим сумму неустойки, которую выплатили из-за неработающей системы.
Произнося «оптимизация, деньги, экономия времени», вы говорите на языке менеджера. Когда он слышит эти слова, то проникается идеей. Он видит в вас не очередного оголтелого программиста, увлеченного свежей технологией, а человека, который заинтересован в улучшении продукта. Все ваши идеи он не одобрит сразу, но высока вероятность, что предложит сделать Proof Of Concept.
Proof of Concept повышает шансы. Предоставьте менеджеру отдельный изолированный участок кода, подсистему, которая покрывается тестами, запускается и работает. Это можно сделать, если взять один из наболевших багов, который всплывает с определенной периодичностью и попытаться его отловить и устранить тестом. PoC подтвердит ваши намерения, покажет, что у вас есть план и ваша работа приносит результат.
Не обещайте много. Для менеджера важны цифры: какие результаты, сроки и какими силами. Но менеджер — существо жадное до результатов. Не обещайте слишком много с самого начала. Если пообещаете решить все проблемы сразу, менеджер пойдет с этим к начальству. Начальство скажет: «Замечательно!», но сократит финансирование и срежет сроки в надежде, что мы сдадим систему намного раньше.
Когда договоримся с менеджером, переходим к тем, с кем приходится работать каждый день.
Коллеги
Не любят перемены. Типичный коллега на типичном legacy-проекте — это человек, который потерял веру в жизнь и будущее. Он не склонен к изменениям и смирился с судьбой: «Я здесь навсегда, выхода из болота нет». Проблема в том, что вы начинаете мутить воду в этом болоте. Вы требуете, чтобы он писал и запускал какие-то тесты, а он хочет выполнить свою работы, закрыть задачу и уйти домой.

Заинтересуйте коллег пользой — объясните, почему им станет лучше. Например, они постоянно тратят время и силы, оставаясь после работы, чтобы залечить какие-то баги. Надавите на это: «Если не деплоить на продакшн сломанный код, не придется тратить время на его починку. Напишем тесты, будем вылавливать такой код, меньше будет ломаться».
Проявите терпение и эмпатию. Вы общаетесь с людьми — спросите почему их беспокоит ваша идея? Предложите найти точку соприкосновения, чтобы понять друг друга. В этом основная тактика работы с людьми: не враждуйте, не сталкивайтесь лбами, будьте дружелюбнее.
Вам может помешать презентация идеи перед собранием коллег на очередном стендапе команды. В коллективе работает механизм «группового мышления»: никто не хочет принимать решение, все смотрят друг на друга и видят, что никто не горит энтузиазмом.
Для решения этой проблемы есть один грязный трюк. К сожалению, в своей жизни я пользовался им не раз.
Разделяйте и властвуйте. Подойдите к одному из коллег за обедом или в уголке и скажите: «Вся команда уже подписалась, ты один тормозишь процесс. Может быть, мы найдем общий язык?»
Пройдя всех по очереди вы подпишите всех. Всем будет стыдно признаться, что они подумали, что все остальные уже подписались. Это бесчестно и ужасно, но работает. Используйте этот прием ответственно и в крайнем случае. Помните — вам еще работать с этими людьми.
Когда разобрались с коллегами, нас ждет еще один жадный зверь.
Борьба с машиной
Это хитросплетение кода, которое называется продуктом. Начнем с азов.
Разберите хлам. Тестировать необходимо так, чтобы при минимальном воздействии на систему получать проверяемый результат. Но любая legacy-система полна данными: они добавлялись годами с момента запуска и влияют на поведение системы. Поэтому необходимо тестировать «с чистого листа».
Подготовьте «сферическую систему в вакууме»: опустошите источники данных, сделайте минимальные конфиги, которые запускает система, отключите все возможные «хаки» и «фичи». Заставьте систему запуститься. Если запустится — у вас есть минимальный набор данных, который необходим для функционирования. Это уже хорошая отправная точка — «чистый лист».
Применяя какие-то измеряемые воздействия, например, нажатие на определенную кнопку, вы получите измеряемый рабочий результат. С этим можно переходить к следующему шагу.
Распутайте данные. Любой legacy-проект работает на принципе «надо сдать вчера». Все, что вы проходили в университете или читали в книгах, здесь не работает. Когда начнете тестировать, столкнетесь, например, с циклической зависимостью, невозможной для воссоздания в программе, но необходимой для функционирования.
Начните с «главного объекта». Чтобы разобраться с лесом зависимостей, попробуйте задуматься о том, какой объект главный. Например, для системы учета склада главный объект — «ящик». С ним связан объект «полка», а с «полкой» — объект «ряд».
Воссоздайте необходимый минимум. Если смотреть по ссылкам между объектами и переходить всё глубже по дереву зависимостей, вы сможете определить необходимый минимум данных зависимых объектов. Вам его нужно воссоздать, чтобы система работала и могла функционировать для тестирования вашего функционала.
Не бойтесь менять ссылки. Возможно, придется засучить рукава и погрузиться глубоко в это месиво: удалять и менять ссылки, изменять структуру базы данных. Вы пришли, чтобы улучшить систему, поэтому не бойтесь вводить изменения.
Переходим к тестированию. Для запутанных старых продуктов хорошая стратегия — это smoke-тесты.
Smoke-тесты
Понятие «дымовое тестирование» пришло к нам из мира электроники. Один инженер собрал гигантскую схему с кучей лампочек и проводов. Но прежде, чем начал тестировать, просто включил схему в розетку. Если пошел дым, значит что-то пошло не так.
В информационных системах концепция smoke-тестов достаточно простая. Представим веб-сервис, у него есть endpoint. Попробуем отправить ему GET-запрос без параметров. Если по какой-то причине продукт неожиданно сломался (ошибка 500), то что-то пошло не так.
Smoke-тест — хорошее начало. Это тест, который проверяет некоторую функциональность и дает понять, что система работает или сломана. Даже простой запрос к самому простому endpoint уже затрагивает больше 1% кода. Такими небольшими тестами готовим плацдарм для дальнейшего тестирования.
Smoke-тест вскрывает множество проблем. Возможно, что за все время функционирования сервиса никто не догадался отправить запрос без параметров.
Используйте такую тактику, чтобы покрыть несколько основных точек входа в вашу программу: форму ввода логина/пароля, основные веб-сервисы, кнопки. Это что-то уже можно показать менеджеру и коллегам.
Функциональные тесты
Это не тесты отдельных классов или метод, а самый высокий возможный уровень тестирования определенной части функционала.
Представим функционал «сгенерировать отчет в сервисе». Вместо проверки отдельных частей, тестируем ситуацию запроса на создание отчета с определенными параметрами и получим файл с данными. Не обязательно знать механизм генерации отчета, но если с определенными входными данными сервис выдает определённые выходные данные, то этот черный ящик с некоторой вероятностью работает как надо.
Покрытие основного функционала подобными тестами позволяет быстро стартовать и сразу покрывает большие участки. Вы будете уверены, что код работает хотя бы приблизительно так, как вы представляете, приобретете больше уверенности, набьете руку и вскроете еще больше проблем.
На иглу функциональных тестов легко подсесть: «Я же тестирую реальный функционал! Это то, с чем сталкиваются пользователи».
Функциональный тест задействует большие куски кода, которые могут взаимодействовать с гигантскими объемами данных. Поэтому 3-4 функциональных теста — это хорошо, 10 хуже, а тысячи тестов, проходящие 9 часов, — перебор. К сожалению, такое тоже бывает.
После функциональных тестов беритесь за unit-тесты. Но о них я не буду рассказывать — вы и так все знаете.
Мы прошлись по азам машинного тестирования и возвращаемся к основной теме. Коллеги и менеджер — не самый страшный враг в бою с legacy. Самый страшный враг — вы сами.
Борьба с собой
Будьте готовы к тому, что путь будет казаться бесконечным. Работа на неделю в вашем плане займет полгода без перспектив завершения проекта.

Сопротивление неизбежно. Все союзники со временем начнут сомневаться, пытаться сойти с колеи, уговаривать бросить тесты и перейти к фичам. Будьте к этому готовы. Напомните всем, зачем вы вообще во все это ввязались, сколько сил и времени вложено. Слабый аргумент, но может сработать.
Никто не гарантирует успех. Даже если проявите героические усилия, вложите всего себя в работу, ваш проект все равно может сгореть, а крестовый поход с тестированием завершится ничем.
Это нормально, это не конец жизни и карьеры. Это даже не подтверждение того, что вы плохой профессионал. Единственный вывод здесь, что конкретно этот проект завершился неудачей.
Зато у вас появился опыт и знания. В следующий раз, когда возьмете в руку новое копье, и ваш конь разгонится на очередную ветряную мельницу, вы будете готовы сломать и это копье, но позже, другим методом и с меньшим ущербом.
Теперь обидное, горькое и вечное.
Напутствия
Не бойтесь обратной связи. Мне приходилось наступать в эту ловушку и видеть, как в нее попадают другие. Я что-то сделал и принес похвалиться коллегам: «Я сделяль!» Но неожиданно оказывается, что мой удобный механизм неудобен коллегам, а я и не спрашивал.
Пишите тесты, пробуйте то, что внедряете. Часто внедрение нового тестового фреймворка увлекает, а непосредственно сами тесты вы не пишите. Тогда может случиться так, что как только их напишите, поймете, что не сможете воспользоваться тестами. Возможно, коллеги тоже это видят, но молчат, либо просто не пишут тесты.
Помогайте коллегам с проблемами, даже если они об этом не просят. Помощь не означает взять всю работу на себя — это расслабляет коллег и снимает с них ответственность, а «автобусное» число снижается до единицы.Тогда вы становитесь человеком-тестировщиком: что-то сломалось, CI красный, тест-гайд. Помогайте в рамках разумного.
«Автобусное» число не шутка. Вы не сможете всегда тащить проект на себе. Каждый может выгореть, уйти в отпуск или уволиться. Поэтому передавайте коллегам ваши знания и ответственность, которая необходима, чтобы справиться без вас. Это поможет избежать неприятных звонков, когда вы расслабились на пляже, а CI снова красный.
Улучшайте механизмы тестирования. Многих проблем можно избежать просто потому, что медленные тесты неожиданно стали быстрыми. Раньше они занимали 20 строк кода, а теперь одну. Вы этого не замечали, потому что один раз что-то написали и забыли: «Работает — не трогай!» Но это правило не всегда применимо.
Вы — не центр Вселенной. Снова повторю, что «автобусное» число это не шутка. Не раз сталкивался с ситуацией, когда человек начал тестирование, а потом получил предложение в проект посвежее: все бросил, убежал, а комментариев и документации не оставил. Все работает до нового коммита, а починить невозможно — никто не понимает, как все устроено.
Не хочу, чтобы вы оказались этим человеком. Не превращайтесь в ограничивающий фактор.
- Пишите документацию.
- Проводите тренинги.
- Распространяйте свой опыт.
27 марта на Moscow Python Conf++ Кирилл расскажет о технической стороне рефакторинга кода с Python 2 на Python 3 — что может быть актуальнее в 2020 году.
Что еще нас ждёт на конференции, можно посмотреть в статье с обзором программы или в соцсетях (fb, vk, twitter) и telegram-канале мероприятия. Скоро увидимся!
Унаследованный код
Если вы работаете в большой продуктовой группе, то скорее всего за время чтения статей на сайте less.works вы, вероятно, думали: “Этот ресурс содержит столько полезных идей, но у нас пять миллионов строк кода, написанных на нашем собственном языке программирования, которые нам нужно поддерживать. У нас это не сработает”. Тогда эта статья как раз для вас.
Существующий хорошо структурированный переиспользуемый код безусловно является ценным активом. Тем не менее, со временем этот актив может превратиться в унаследованный (legacy code) — с плохой структурой, без автотестов, с неактуальной документацией и большим количеством дублирований. Унаследованный код ограничивает организационную гибкость, и как мы увидим, ведёт к серьёзному ослаблению вашей конкурентной способности. Это статья о том, как писать такой унаследованный код, и том как этого избегать.
Но перед погружением в тему нужно будет отметить, сколько рабочих мест существует благодаря унаследованному коду. Мы путешествуем по миру и часто работаем в развивающихся странах. В этих странах люди вышли из бедности благодаря рабочим местам, созданным для поддержки устаревшего кода. Например, в Индии и Китае несколько городов существенно развились, как в размерах, так и по уровню жизни за последнее десятилетие не без помощи индустрии заказной разработки (outsourcing industry), а большая её часть относится к унаследованному коду. Мы это ценим.
С другой стороны, что бы произошло, если бы всю эту энергию направили на творческие, инновационные продукты? Кроме того, унаследованный код разрушал компании…
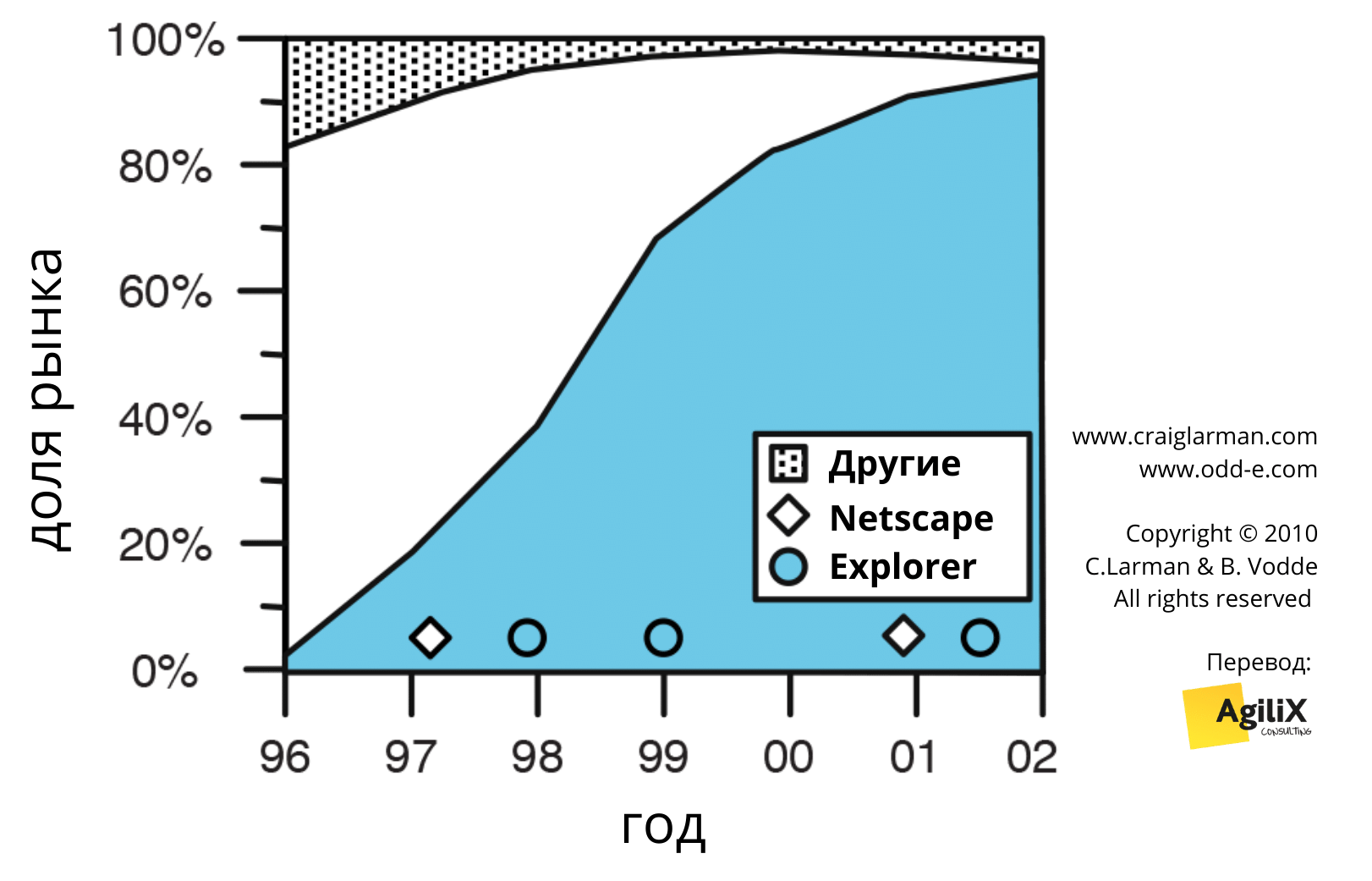
Рис. 1. Доля рынка браузеров и их версии
Браузер Netscape — один из лучших примеров, который по началу владел рынком. Но в 1995 году компания Microsoft осознала громадный потенциал сети Интернет и начала то, что в последствии назовут “войнами браузеров“ [см. книгу Competing On Internet Time]. В 2000 году она выиграла первую битву этой войны.
Этому произошло по ряду причин. Одна из них в том, что Netscape не выпускала новую версию своего браузера три с половиной года. Но почему? “Потому что браузер был переписан заново без использования прежней кодовой базы Netscape Communicator”. В 2007 году компания AOL, (которая купила Netscape в 1999 году) официально убила браузер Netscape.
Это статья решит все ваши проблемы с унаследованным кодом… ладно, а может и нет. Но она определённо притупит вашу боль от унаследованного кода и возможно когда-то, вы сможете полностью от него избавиться.
Как Писать Новый Унаследованный Код
Писать унаследованный код просто — мы объясним это на примере нескольких простых шагов. За десятки лет компании создали кучу унаследованного кода. В компании Xerox мы однажды услышали: “Нам давали много уроков, но выучили мы лишь часть”. Это особенно касается унаследованного кода. Мы из раза в раз проходим этот урок, но почему-то так и не можем его выучить.
Как давно это началось? Ещё в 1967 году, возможно, в первой книге по управлению проектами разработки Чарльз Лехт (Charles Lecht) писал:
Ответственность за запуск заранее обречённого проекта в равной степени лежит как на менеджменте, который настаивает на фиксации определённых обязательств со стороны программистов, так и на самих программистах, которые не понимают то, на что соглашаются. Слишком часто менеджмент не осознает, что, прося сотрудников о “невозможном”, сотрудники будут чувствовать себя обязанными согласиться из уважения, страха или ложной лояльности. Чтобы сказать начальнику “нет”, часто требуется смелость, политическая и психологическая мудрость, а также понимание бизнеса, которые приходят с большим опытом.
Ниже указаны явные причины появления унаследованного кода:
И конечно в этих причинах лежат ключи к предотвращению его возникновения…
Как Избежать Написания Унаследованного Кода
Избегайте нереалистичных сроков и фиксированного объёма работ
“Мы обещали этот релиз нашему основному заказчику к первому февраля, и отдел разработки должен сдержать это обещание” — было написано в недовольном письме директора менеджменту продуктовой группы, которую мы консультировали. Мы недоверчиво прочитали это письмо и задались вопросом о “сдержать это обещание”. Решили не обращать пока на него особого внимания и вернуться к обычной работе — обучению одного из разработчиков рефакторингу унаследованного компонента, который был сляпан на скорую во время последнего релиза, чтобы успеть в срок.
Многие компании застряли в порочном круге навязанных обещаний и невыполнимых обязательств. Сегодня, в эру высоких скоростей, клиенты ‘принуждают’ их обещать слишком многое. “Если вы не можете поставить к концу года, мы купим у вашего конкурента, который даст такое обещание”. Отдел продаж или руководство могли бы отреагировать, проявив прозрачность и стремясь к взаимовыгодным долгосрочным отношениям (сотрудничество с заказчиком), но вместо этого они озадачены, прописана ли неустойка в договоре за несоблюдение приемлемых сроков (согласование условий контракта), и отвечают: “Да, без проблем, мы это сделаем!”. После этого тот же цикл начинается уже внутри организации. Руководство приказывает главе разработки “сделать это” или “сделать так, чтобы это случилось”, потому что “это обещано клиентам”. Обещание путешествует по организационной структуре к разработчикам, которые не могут передать его дальше.
Как разработчик обычно реагирует? Чарльз Лехт уже нас предупреждал более 50 лет назад: Разработчик будет “обязан согласиться из уважения, страха или ложной лояльности” и неохотно, но соглашается на эти сроки. Разработчик открывает свой секретный ящик с инструментами и делает всё возможное, чтобы успеть к ближайшему сроку, используя инструменты, такие, как хардкод, копипаст-программирование, игнорирование тестов, сверхурочные и другие, разрушающие качество и срезающие углы практики см. книгу The Enterprise and Scrum. Никто не обращает внимание на использование этих ‘инструментов’, поэтому что сроки соблюдены. Менеджмент награждает разработчиков за их тяжёлый труд и восхваляет их за “отличную командную работу” и “боевой дух”.
Эти разрушающие качество и срезающие углы практики приводят к ужасному унаследованному коду, который замедляет разработку, а организация проигрывает конкурентам. Предсказуемый сценарий. Им необходимо вернуть себе рынок и, следовательно, дать новые обещания, снова запуская этот порочный круг. Технический долг — это унаследованный код, замедляющий разработку. Долг обучения — нехватка новых навыков у разработчиков усугубляет это отставание. Разработчики настолько заняты, выполняя неосуществимые обязательства, что у них нет времени развивать свои навыки.
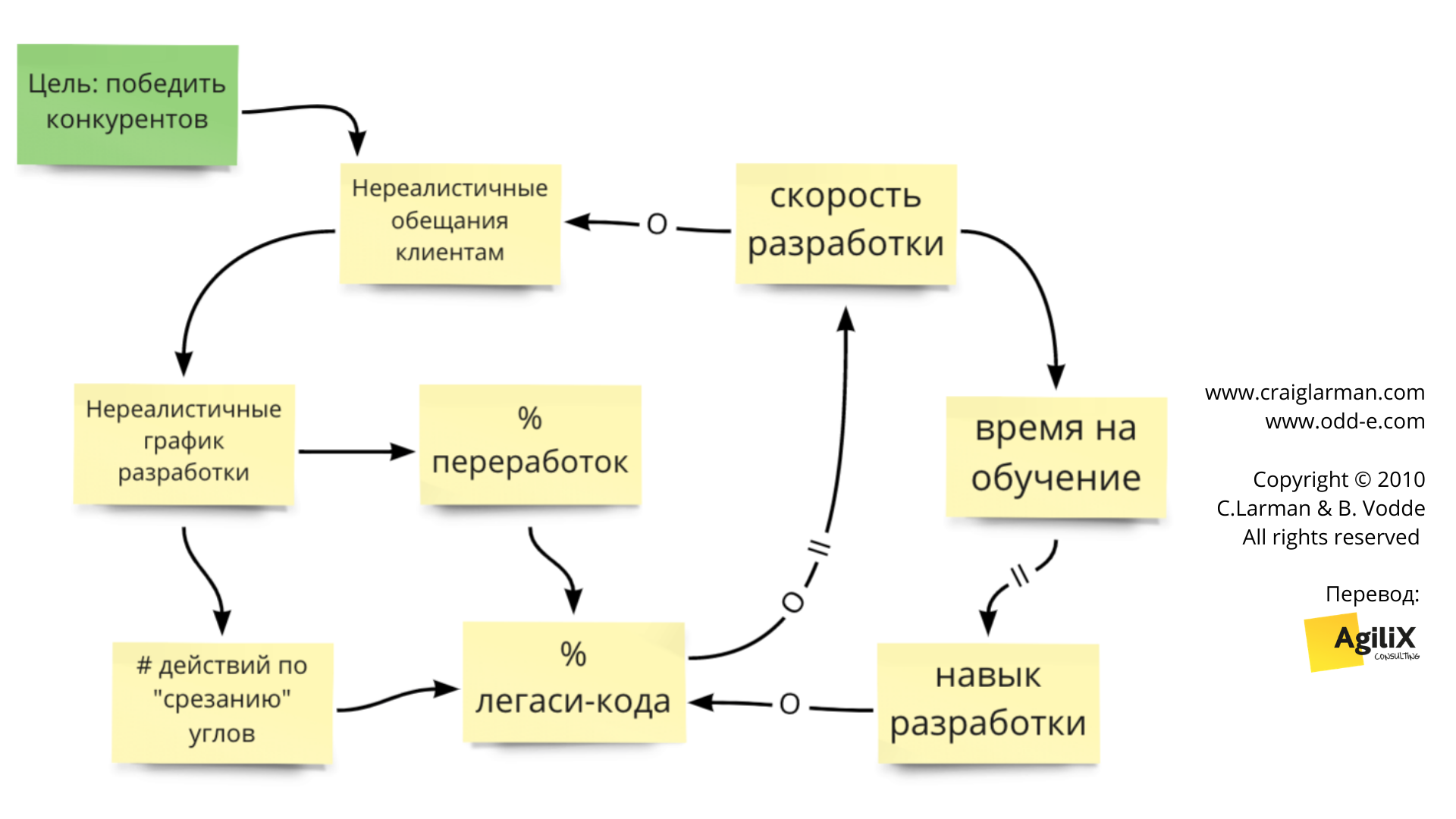
Рис. 2. Динамика нереалистичных сроков
Боб Мартин в книге Чистый Код утверждает, что настоящие мастера своего дела не давали бы таких невыполнимых обещаний, а проблема унаследованного кода могла быть решена обучением разработчиков, чтобы повысить их профессионализм.
Мартин частично прав. Но этот взгляд игнорирует тот факт, что разработчик является частью бóльшей системы, которая усиливает это поведение. Нужно, не только развивать мастерство разработчиков, но и улучшать систему, в которой они работают, в целом.
Однажды в Европе мы посетили директора большой продуктовой группы (которая разрабатывала встраиваемые системы) и его команду менеджеров. Директор объяснил, что группа успешно выпустила последний релиз, и поставил под сомнение необходимость внедрения масштабируемого Скрама. В этот момент один из его подчинённых сказал: “Ну, на самом деле ближе к дате релиза мы сильно отставали, поэтому мы много работали сверхурочно, выдернули более сотни человек из другого продукта нам в помощь. Поэтому мы и успели. Сейчас мы серьёзно отстаём от графика, потому что в последнем релизе было создано так много плохого кода, что мы тратим бóльшую часть времени на исправление дефектов, о которых сообщают нам наши клиенты, и вынуждены работать с беспорядком в кодовой базе”.
Обратите внимание на взаимосвязь между этими событиями и отсутствием бережливого мышления. Например, в этих случаях прослеживается утрата связи с реальностью (waste of wishful thinking). Один из трёх источников потерь в бережливом мышлении — перегрузка (overburden) — часто можно увидеть, как героический рывок ближе к концу релиза приводит к ещё большим потерям в будущем. Также отсутствует культура остановись и исправь (stop and fix) — а наблюдается противоположная ей “нет времени точить, нужно пилить” (carry on and don’t fix).
Если вы скажите своим клиентам: “Мы не понимаем, что происходит, и понятия не имеем, когда это будет сделано”, то это будет коммерческим самоубийством. Мы часто слышим от руководителей фразу: “Либо мы берём на себя нереалистичные обязательства, либо у нас не будет работы”. Это убеждение является ложной дихотомией.
Есть другой способ, когда клиент и заказчик вместе понимают суть продуктовой разработки: она не предсказуема на 95%. Вы можете принять эту реальность, если будете демонстрировать прозрачность по отношению к своим клиентам во время разработки. Например, …
- предоставляя информацию о текущем статусе разработки вашим ключевым клиентам каждую итерацию; например, с помощью Диаграммы Сгорания Релиза (Release Burndown Chart) и обновлённого Бэклога Продукта
- давая возможность ключевым клиентам предоставлять обратную связь по приоритетам и изменению целей по мере того, как они видят, как идут дела, а затем корректируя план соответствующим образом
- предоставляя оценки с указанием их точности (вероятности) или несколько оценок (по разным сценариям) см. книгу Вальсируя с Медведями
- используя другие техники, которые поощряет частое взаимодействие с клиентами, основанные на реальности и прозрачности
Благодаря изменениям в том, как продуктовые компании взаимодействуют со своими клиентами, снижается давление, приводящее к созданию унаследованного кода.
Часто менеджмент прибегает к “быстрому решению” (quick-fix) в ответ на давление рынка — ‘заказать’ разработке “ещё ресурсов”, так как это ‘дёшево’. Мы работали с продуктовой группой, которую принудили нанять сотни людей в течение года. Исключение? Нет, вот ещё пример: лидер продуктовой группы, с которой мы работали, недавно был ‘назначен‘ руководить новым продуктом. В этом продукте работало 900 человек в 12 разных офисах и 20 активных филиалах. Этот продукт отставал от конкурентов, и предыдущее руководство пыталось спасти его, добавляя больше людей — теперь они отставали ещё больше.
Вот ещё урок, который даётся снова и снова. Возможно, первым крупномасштабным проектом в мире была SAGE система, которая разрабатывалась в 1950-х. Команда проекта торопилась, поэтому…
В течение года примерно 1000 человек были вовлечены в разработку системы SAGE. Люди из самых разных слоёв общества были наняты и обучены. Проводники трамвая, сотрудники похоронного бюро (изучавших математику не менее года), школьные учителя, мойщики окон и другие в спешном порядке были собраны, обучены программированию в течение нескольких недель и распределены по разным отделам очень большой организации… Изначально ожидаемый объем работ был значительно уменьшен. Первый релиз состоялся с опозданием на год и значительно превысил бюджет 1 .
Вместо воспитания великих разработчиков или найма небольшого количества крутых людей они сконцентрировались на найме максимального количества “голов” (англ. heads, head count) что, в свою очередь, привело к поспешной и неполноценной образовательной программе для новых сотрудников. Это быстрое решение приводит в целом к низкому уровню навыков разработки в командах, снижает вероятность стать хорошими разработчиками и, в конечном итоге, к всё значительному увеличению количества плохого унаследованного кода.
Низкие Навыки Разработки
Системная динамика обещаний и обязательств полностью не описывает историю об унаследованном коде. Боб Мартин прав — индустрии определённо точно нужны хорошие инженеры.
В целом по нашим наблюдениям уровень навыков разработчиков в больших продуктовых группах довольно низкий. Разработчики часто не знакомы с хорошими базовыми техниками — простыми практиками, такими как сокрытие и инкапсуляция, или принципами хорошего дизайна. От разработчиков встраиваемых систем мы иногда слышим восклицания: “Это техники для ООП, а мы пишем на языке Си”. Но они не понимают, что некоторые из этих идей были изначально разработаны не для объектно-ориентированных технологий 2 . Мы наблюдали следующий зависимость:
Чем больше продуктовая группа, тем меньший объём знаний ‘современных’ практик разработки
Но эти практики являются основой для бесконечно повторяемого процесса разработки. К счастью, навыки разработки зависят не только от чистого таланта; они могут быть изучены и улучшены:
- в школах
- при поддержке организаций
- путём самообучения
Лидеры продуктовой группы могут думать, что понимают, как работают образовательные программы, но это может быть не так…
Школы — В университетах не преподают базовых навыков разработки. Есть шокирующий разрыв между академическим образованием и коммерческой разработкой. Многие преподаватели никогда не работали разработчиками и не видели долгосрочную динамику развития навыков разработки и унаследованного кода. Им также не хватает практики Go See. Некоторые университеты недавно добавили практики Agile-разработки в их учебную программу по информатике. Это хорошо. Однако требуется глубокий опыт, чтобы действительно понять Agile-практики такие, как разработка через тестирование (TDD), а преподаватели редко имеют такой опыт.
Поэтому, не ожидайте от выпускников университетов, что они будут иметь хорошие навыки, особенно в Agile-разработке.
Поддержка в организации — Многие компании не считают должным обучать разработчиков. Мы часто слышим: “Любой выпускник университета может писать код”, тем самым подразумевая, что уже не требуется обучение базовым навыкам разработки. Наш опыт в консалтинге говорит об обратном. Многим разработчикам в больших продуктовых группах не хватает фундаментальных навыков, таких как: навыки дизайна программного обеспечения, эффективная работа с редакторами, эффективное использование основного языка программирования или автоматизация задач путём написания скриптов. Организации не уделяют вниманию обучению в этих областях, потому что многие бизнес-лидеры логично, но ошибочно предполагают, что люди приобрели эти навыки в университете, не зная, что учебная программа по информатике не учит навыкам разработки программного обеспечения, и что большинство университетских профессоров не знают и не могут преподавать современные практики разработки 3 .
В отличие от них бережливые (lean) организации инвестируют в обучение своих сотрудников. Одно из исследований показывает, что японские компании тратят в восемь раз больше на обучение новых сотрудников, чем в США, и в два раза больше, чем их европейские конкуренты [см. книгу The Machine That Changed the World].
Организации также не осознают необходимость постоянного улучшения. Им необходимо не только обучать базовым навыкам, но и создавать среду, в которой сотрудники постоянно сталкиваются с вызовами и учатся отвечать им. Как? Менеджеры в роли учителей, коллеги, обучающие друг друга (например, с помощью парного программирования), а также внутренние или внешние выделенные коучи — все это поддерживает культуру обучения и постоянного совершенствования.
Самообучение — Многие разработчики не следят за развитием своих навыков. Гуру по качеству ПО Филип Кросби (Philip Crosby) назвал недостаток знаний, вызванный нехваткой обучения, главной причиной плохого качества.
Люди подсознательно тормозят собственное развитие. Они начинают полагаться на клише и привычки. Когда они достигают определённого уровня личного комфорта, они перестают учиться, и их ум остаётся бездействующим до конца своих дней. Они могут подниматься по карьерной лестнице, могут быть амбициозными, напористыми и даже работать с утра до ночи. Но они больше ничему не научатся. Филип Кросби (Philip Crosby) Quality Is Free, 1980.
В 1999 году Дейв Томас (Dave Thomas) и Энди Хант (Andy Hunt) опубликовали превосходную книгу Программист-прагматик. Путь от подмастерья к мастеру], резюмирующую мировоззрение и поведение современного профессионального разработчика. Мы призываем людей прочитать её и взять на себя ответственность за собственное развитие.
Избегайте тривилизации разработки
“Я архитектор, написание кода — этой низкоквалифицированной работой должны заниматься другие люди”. Мы слышим подобные заявления от архитекторов из “башни из слоновой кости”, которые считают, что программирование ниже их уровня. Организация, в которой работают такие архитекторы, создала культуру тривилизации (упрощение, признание обыденным, англ. trivializing) программирования. Такая культура принижает значение кода, обесценивает написание чистого кода и познание навыков программирования. В такой культуре люди хотят подняться по социальной и организационной лестнице — а это означает отход от программирования. Программирование является всего лишь ранним этапом карьеры, который им предстоит пройти. Такая культура поощряет распространение унаследованного кода.
Организации тривилизируют разработку при помощи:
- аутсорсинга разработки
- карьерного роста
- разницы в зарплатах
Аутсорсинг разработки — Особенно в больших продуктовых группах мы сталкиваемся с компаниями, которые не считают написание кода своим “основным бизнесом”, и поэтому передали его на аутсорсинг. Они составляют спецификации, архитектурную и проектную документацию, а затем отправляют их дешёвым разработчикам в оффшор, чтобы “выполнить разработку и тестирование.” Рецепт катастрофы. Исходный код — это место создания реальной ценности — гемба. Подробнее смотрите:
Карьерный рост — Крупные организации хотят обеспечить будущее для своих сотрудников; типичное решение — это установленные карьерные пути для менеджеров и инженеров. Люди, идущие по пути менеджмента, уходят от технической работы и становятся “профессиональными менеджерами”. Те, кто идёт по техническому пути, тратят своё время на написание “архитектурных документов”. Какой бы карьерный путь вы ни выбрали, в нем не будет программирования.
Разница в зарплатах — Из всех профессий, связанных с разработкой программного обеспечения, зарплата программистов в среднем одна из самых низких (см. книгу Applied Software Measurement). Естественно, и к сожалению, эта разница в заработной плате не способствует тому, чтобы стать лучшим разработчиком, а вместо этого способствует прекращению работы в в этом качестве. Есть ли альтернатива? Пит МакБрин (Pete McBreen) продвигает модель мастерства в области программного обеспечения, в которой зарплата напрямую связана с навыками. Навыки разработчиков оцениваются по портфолио и отзывами коллег.
Повышайте осведомлённость о негативном влиянии унаследованного кода
Накопление унаследованного кода — это не только помеха, это якорь. Трудно быстро поставить ценность и быстро адаптироваться, когда ваши 15 миллионов строк кода представляют собой дымящуюся кучу… ну, вы сами знаете чего.
Некоторые разработчики и многие нетехнические специалисты в продуктовой разработке не осознают негативное влияние унаследованного кода — с точки зрения затрат на обслуживание этого технического долга и с точки зрения возможностей, упущенных из-за снижения скорости и способности вносить изменения.
Мы призываем технических руководителей активно просвещать свои бизнес- и техническое сообщества по этому вопросу и осознавать стоимость владения унаследованным кодом.
Хорошо, у нас есть унаследованный код, что дальше
Вы, вероятно, узнали причины появления унаследованного кода, и его у вас уже кучи. Как от него избавиться? В своей книге Working Effectively with Legacy Code Майкл Физерс (Michael Feathers) рассказывает о конкретных техниках работы с кодом для его постепенного улучшения. В этой статье мы не будем повторяться, рекомендуем прочесть книгу Физерса. Но мы рассмотрим некоторые общие стратегии работы с унаследованным кодом.
Не переписывайте унаследованный код
Столкнувшись с унаследованным кодом, разработчики часто предлагают его переписать, изменить дизайн или перестроить архитектуру — отказаться от унаследованного кода и написать его снова. В следующий раз будет лучше… Сопротивляйтесь этому искушению. Почему?
В продуктовой группе с 30-летней кодовой базой разработчик спросил нас, можем ли мы помочь в рефакторинге функции из 5000 строк. Мы думали, что он преувеличивает. Но когда мы сели в пару и посчитали количество строк функции, мы обнаружили, что она даже немного больше 5000. Как могла быть создана такая функция? Просыпается разработчик и думает: “Боже, какой сегодня чудесный день! Напишем-ка функцию из 5000 строк?”. Вероятно, что нет. Когда разработчик пишет новый код, он обычно пишет его с приличным качеством. Но со временем качество ухудшается. И функция вырастает до 5000 строк. Почему так происходит? Клиент запрашивает новую фичу, и она впихивается из-за плохих навыков разработки или нереалистичных сроков. Качество кода снижается, а усилия, необходимые для внесения изменений, возрастают (см. рис. 3).
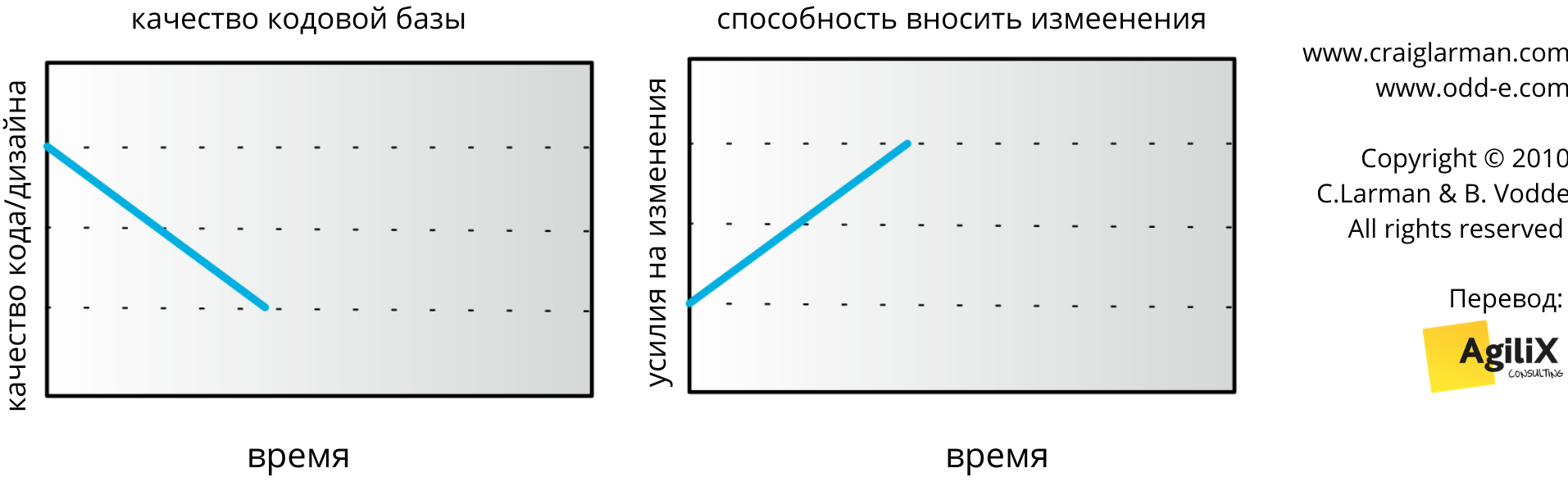
Рис. 3. Качество кода снижается со временем
Через какое-то время вносить изменения в код становится слишком болезненно и для этого требуется слишком много усилий; разработчики начинают просить его переписать. Сначала Владелец Продукта отказывается — переписывание означает высокие затраты без добавления новой ценности. Но по мере того, как скорость разработки падает, разработчики жалуются все больше, и в конечном итоге Владелец Продукта ‘соглашается’ переписать. В это время способность реагировать на изменения — новые требования — равна нулю. И после окончания переработки код получается качественным, а значит, и новая разработка идёт быстрее (см. рис. 4).
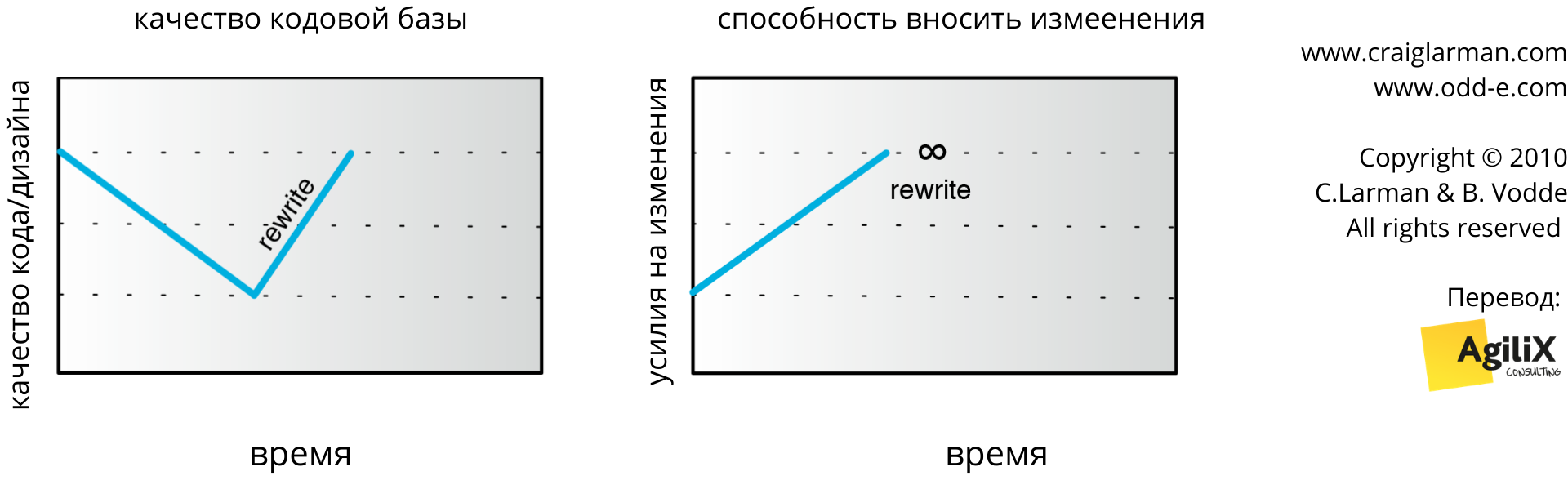
Рис. 4. Переписывание улучшает качество
Что происходит после? Спешка при реализации новых требований приводит к “срезанию углов” только что вычищенного кода, что снова приводит к ухудшению качества и увеличению усилий по разработке (см. рис. 5). Через некоторое время разработчики требуют ещё раз всё переписать. В некоторых крупных продуктовых группах мы видели, как компоненты переписывались трижды.
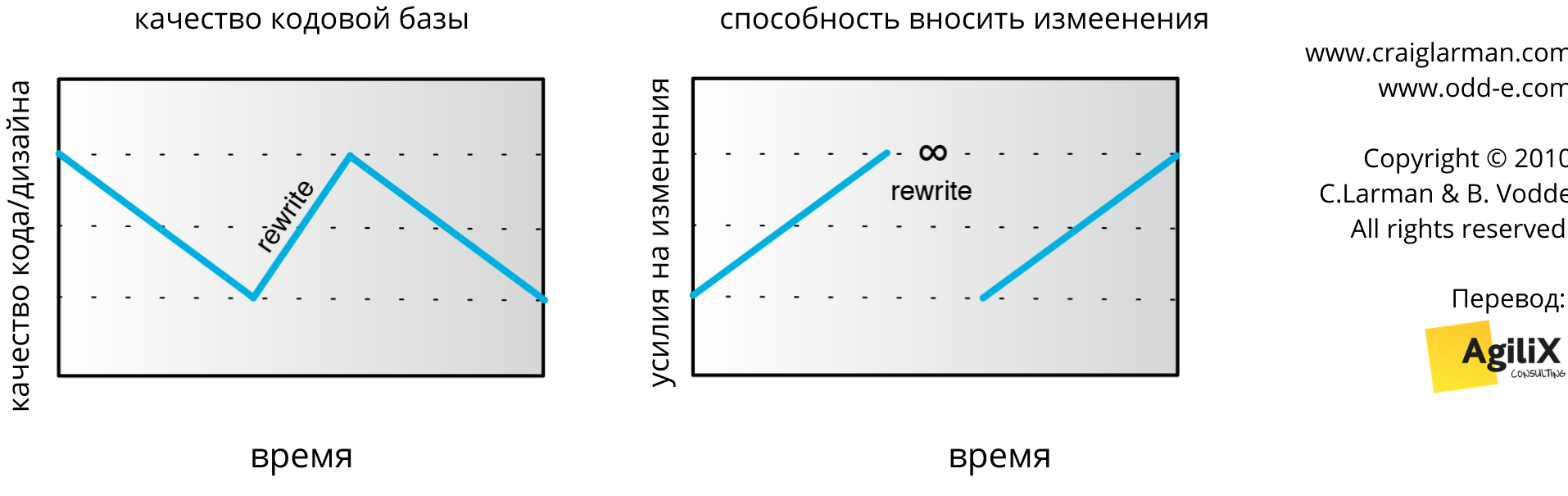
Рис. 5. Качество кода снижается вновь после переписывания
Key insight: The problem is not having legacy code, it is creating legacy code.
Ключевая идея: Проблема не в наличии унаследованного коде, а в его создании.
Мысль в том, что нужно предотвращать создания нового унаследованного кода, а не бороться с ним самим. Фокус должен быть на выращивании здорового кода и не давать ему ухудшаться со временем. Но как? Улучшайте качество кода каждый раз, когда его меняете. “Если бы мы все оставляли после себя наш код немного чище, чем когда мы за него взялись, то код попросту не будет загнивать” — утверждает Боб Мартин (см. рис. 6).
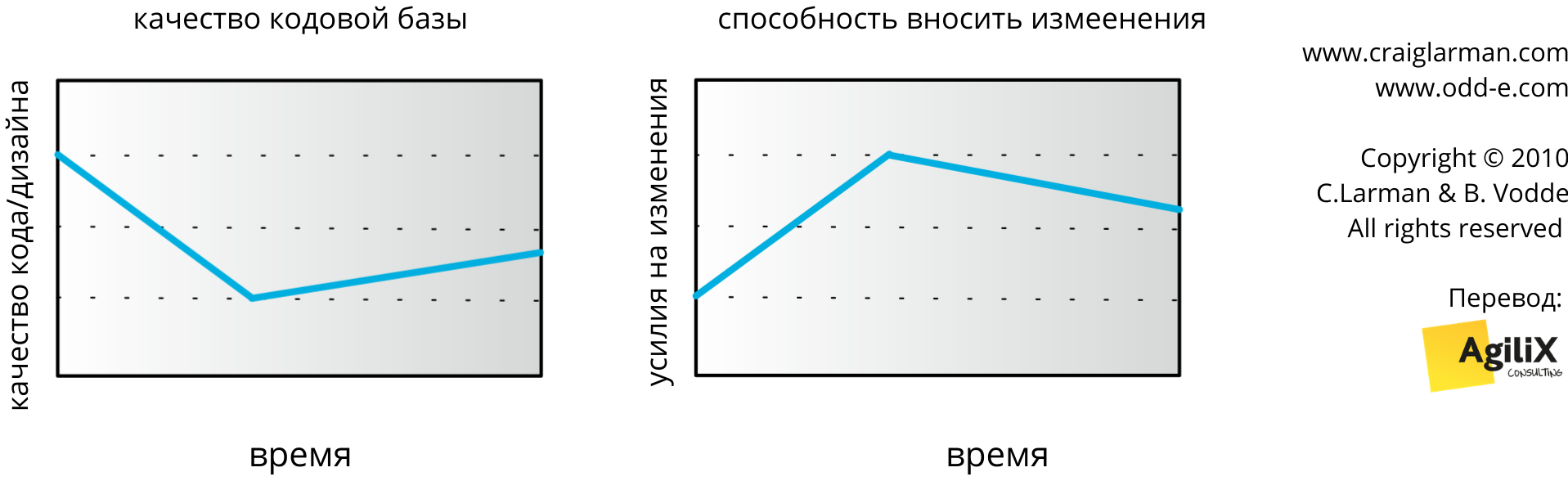
Рис. 6: Выращивание здорового кода
Улучшайте код по соседству
Выращивание здорового кода — ключевая стратегия устранения унаследованного кода. Вы можете следовать ей, улучшая код по соседству и постепенно устраняя “разбитые окна“. Каждый раз, когда вы вносите изменения, осматривайтесь вокруг места их внесения — на его соседей, код, который может быть улучшен, “разбитые окна”: добавьте пару тестов и проведите рефакторинг (см. рис. 7). Когда начнёте применять эту практику, каждое изменение будет происходить немного медленнее. Но со временем код улучшается, а скорость разработки увеличивается из-за более здорового кода.
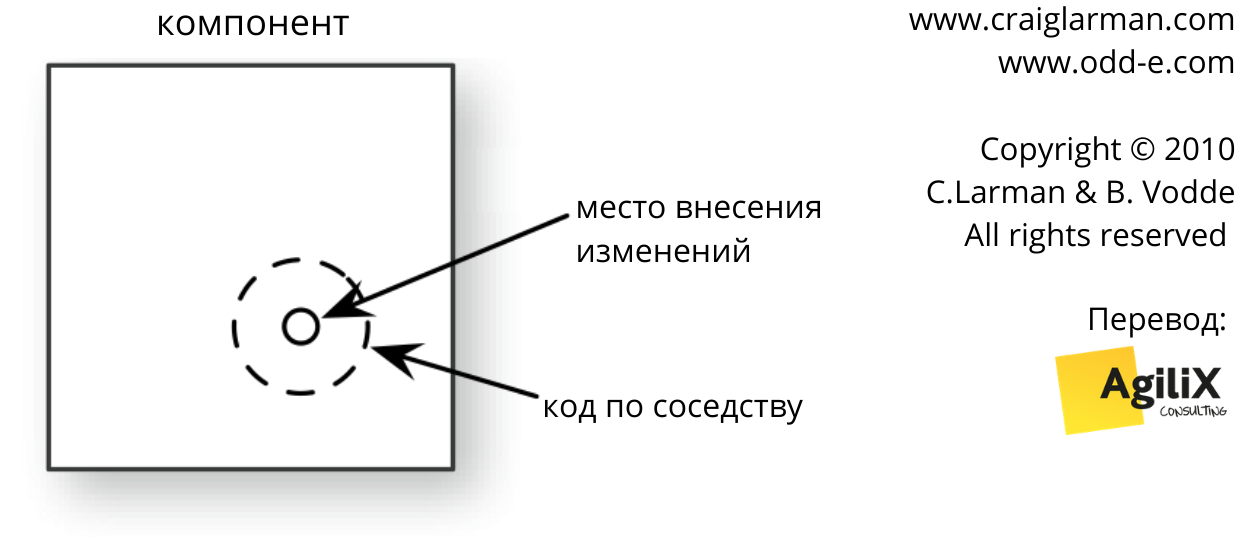
Рис. 7: Улучшайте код по соседству
Унаследованный код означает наличие технического долга — а выплата долгов не бесплатна. Стратегия переписывания пытается погасить долг сразу. С другой стороны, улучшение кода по соседству распределяет выплаты во времени. Она направляет усилия на самые важные части, которые меняются чаще всего. Унаследованный код, который не меняется и не улучшается — и это нормально.
Пишите высокоуровневые и модульные тесты
Нас часто спрашивают, начинать ли с модульных тестов или с высокоуровневых тестов. Ещё одна ложная дихотомия. Они все важны! Часто проще добавить высокоуровневые тесты к унаследованной кодовой базе, они дают уверенность, что существующая функциональность работает. Но модульные тесты выполняются быстро. Быстро выполняемые модульные тесты помогают при пошаговом рефакторинге унаследованного кода. Поэтому пишите модульные и высокоуровневые тесты при улучшении кода по соседству.
Переписывайте мёртвый унаследованный код
Иногда невозможно постепенно провести оздоровление кодовой базы. Предположим, что часть низкоуровневого кода написана на PL/M (устаревший процедурный язык, прим. переводчика), и его никто не хочет изучать. Или часть вашего кода написана на доморощенном языке, компилятор которого работает только на VAX/VMS (проприетарная серверная операционная система, прим. переводчика). Когда постепенное изменение невозможно 4 — то унаследованный код уже мёртв, т.е. необходимо ‘ампутировать‘ эту часть кода вместо того, чтобы позволить ей убить ваш продукт. 5
При замене мёртвого кода:
- покройте его тестами
- не добавляйте функциональности в старый код
- не добавляйте функциональности в заменённый код
Заключение
В мире существуют миллиарды строк унаследованного кода, и их количество увеличивается с каждым днём. Это уже создавало огромные проблемы в прошлом (например, Проблема 2000 года), и будет в будущем. Но унаследованный код не исчезнет, если не будут устранены первопричины:
- нереалистичные сроки и фиксированный объём работ
- низкие навыки разработки
Их можно решить, обучая людей о причинах возникновения унаследованного кода и улучшая систему обучения разработчиков. Однако индустрия десятилетиями не осознавала этих проблем. Вряд ли это изменится в ближайшие несколько лет.
Что делать с существующим унаследованным кодом? Лучше постепенно улучшать код, чем полностью заменять его. Это требует инвестиций в навыки разработки и применения современных практик, таких как TDD. Единственный способ вырастить лучший код — это вырастить блестящих сотрудников. Это тематика бережливого мышления.
Рекомендуем к Прочтению
На момент написания этой статьи, было написано на удивление мало о такой огромной и дорогостоящей проблеме, как унаследованный код (в 2020 году ситуация не изменилась, прим. переводчика). Вот некоторые книги по постепенному улучшению вашего кода, которые мы считаем полезными:
-
Майкла Физерса. Конкретные советы о том, как постепенно улучшать унаследованную систему на уровне кода. Мартина Фаулера. Классическая работа про улучшение существующего кода. Билла Вейка. Конкретное руководство по совершенствованию рефакторинга кода. Джошуа Кериевски. В этой книге Джошуа объясняет, как постепенно реорганизовать код по стандартным надёжным шаблонам проектирования. Стефана Рука и Мартина Липперта. Для больших систем может потребоваться большой рефакторинг. В этой книге объясняется, как это сделать мелкими шагами, чтобы ваши системы оставались стабильными.
Следующий материал охватывает организационную динамику, связанную с унаследованным кодом:
-
Кена Швабера. Глава 9 — одно из немногих описаний, объясняющих взаимосвязь между обещаниями клиентов и созданием унаследованного кода. Кэвина Тейта. Эта книга не охватывает многих новых техник, но даёт отличный обзор методов устойчивого создания программного обеспечения.
Мастер разработки программного обеспечения предотвращает создание унаследованного кода и, следовательно, разрабатывает программное обеспечение с устойчивой скоростью. Некоторые материалы о том, как стать мастером разработки:
Как работать с legacy-системами

На самом деле, по-хорошему статью следовало бы назвать так: «Как работать с legacy-системами и сохранять психическое здоровье». Любой, кто имеет с ними дело, меня поймет, — пишет Dmitriy Kouperman в своей статье на DOU.UA.
Эта статья — попытка обобщения многолетнего опыта знакомства с legacy-системами в виде набора подходов и практических советов. Примеры буду приводить из собственного опыта — в частности, работы с унаследованной Java-системой.
Кстати, материалов о работе с legacy в структурированном виде почти нет — оба источника, посвященных именно ей, приведены в конце материала. И это при том, что на legacy приходится чуть ли не половина всего аутсорсинга.
Особенности legacy
Legacy — в переводе с английского «наследство», и наследственность эта тяжелая. Почти всем доводилось, придя в проект, получить код десятилетней давности, написанный кем-то другим. Это и есть унаследованный код — то есть код исто(е)рический, который часто бывает ужасен настолько, что оказывается вообще непонятно, как с ним работать. И если нам достается legacy-система, то мы, кроме старого кода, также имеем:
- устаревшие технологии;
- неоднородную архитектуру;
- недостаток или даже полное отсутствие документации.
Со всем этим нам нужно разбираться и как-то жить дальше. И тут без хорошего чувства юмора, пожалуй, не обойтись — те, кто воспринимают жизнь слишком серьезно, обычно сбегают сразу же, как только увидят настоящее legacy.
На самом деле, legacy-система — это не так уж страшно, и вот почему: если система жила все эти десять лет и до сих пор работает, значит, какой-то толк от нее есть. Может быть, она приносит хорошие деньги (в отличие от вашего последнего стартапа на новейших технологиях). Кроме того, код такой системы относительно надежен, если он смог так долго выживать в продакшне. Поэтому вносить в него изменения нужно с осторожностью.
Прежде всего, нужно понять две вещи:
- Мы не можем неуважительно относиться к системе, которая зарабатывает миллионы, или к которой обращаются тысячи людей в день. Как бы плохо она ни была написана, этот отвратительный код дожил до продакшна и работает в режиме 24/7.
- Раз эта система приносит реальные деньги, работа с ней сопряжена с большой ответственностью. С самого начала ясно, что это не стартап в стол, а то, с чем пользователи будут работать уже завтра. Это подразумевает и очень высокую цену ошибки, причем дело здесь не в претензиях клиента, а в реальном положении вещей.
Какие задачи нам придется решать, работая с такой системой? Во-первых, мы, очевидно, будем разрабатывать новую функциональность, раз система жива, а значит развивается. Во-вторых, мы будем исправлять ошибки, и это тоже очевидно. И наконец, хотя многие предпочитают про это забыть, мы будем заниматься оптимизацией и стабилизацией системы, даже если напрямую такой задачи перед нами в начале проекта никто не ставил.
Обратный инжиниринг
Для успешной работы с унаследованными системами нам придется много пользоваться приемами reverse engineering.
Прежде всего, нужно внимательно читать код, чтобы точно понимать, как именно он работает. Это обязательно — ведь достаточной документации у нас, скорее всего, не будет. Если мы не поймем хода мыслей автора, то будем делать изменения, последствия которых окажутся не вполне предсказуемыми. Чтобы обезопасить себя от этого, нужно вникать еще и в смежный код. И при этом двигаться не только вширь, но и вглубь, докапываясь до самого нутра. Откуда вызывается метод с ошибкой? Откуда вызывается вызывающий его код? В legacy-проекте «call hierarchy» и «type hierarchy» используется чаще, чем что бы то ни было другое.
Конечно, придется проводить много времени с отладчиком — во-первых, чтобы находить ошибки, и во-вторых, чтобы понять, как все работает — потому что логика обязательно будет такой, что по-человечески прочитать ее мы не сможем. Собственно говоря, дебажить нужно будет вообще все, в том числе и open source-библиотеки. Даже если проблема где-то в Spring, значит, придется отлаживать и, возможно, пересобирать Spring, если возможности его обновить не окажется. Именно так нам неоднократно приходилось делать, причем не только со Spring.
Что касается документации, не лишним будет прибегнуть к тому, что я бы назвал промышленной археологией. Очень полезно бывает откопать где-нибудь старую документацию и поговорить с теми, кто помнит, как писался доставшийся вам код. Возможно, где-то есть старый Confluence, возможно, хотя бы дамп его базы, где вы что-то, может быть, и найдете. Иногда это бывает проще, чем сидеть с дебаггером. Но нередко там окажутся только документы, не имеющие прямого отношения к коду, например, руководства по настройке серверов, которые все в принципе боятся трогать.
Используя эти приемы, рано или поздно вы начнете более или менее понимать код. Но чтобы ваши усилия не пошли прахом, вы должны обязательно сразу же документировать результаты своих изысканий — для этого я советую рисовать блок-схемы или диаграммы последовательности (sequence diagrams). Конечно, вам будет лень, но делать это точно нужно — через полгода без документации вы сами в этом коде будете копаться как в первый раз. А если через полгода с кодом будете работать уже не вы, ваши последователи будут очень благодарны вам за имеющуюся документацию.
Кстати, зачастую для себя и для бизнеса документацию нужно готовить разную: в вашей, рассчитанной на инженеров, представители бизнеса ничего не поймут. Им потребуется что-то понятное, описывающее функционирование системы на верхнем уровне. И наконец, нужно не забывать самим пользоваться этой документацией и читать ее. Однажды, решив проблему после двух дней героической борьбы, мы обнаружили собственный документ, подробно описывающий точно такой же случай.

Процесс разработки
Итак, что нужно и что не нужно делать:
Не переписывать
Самое важное здесь — вовремя бить себя по рукам и не пытаться переписать весь код заново. Прикиньте, сколько человеко-лет для этого потребуется — вряд ли заказчик захочет потратить столько денег на переделывание того, что уже и так работает. Это касается не только системы в целом, но и любой ее части. Вам, конечно, могут дать неделю на то, чтобы во всем разобраться, и еще неделю на то, чтобы что-то исправить. Но вряд ли дадут два месяца на написание части системы заново.
Вместо этого реализуйте новый функционал в том же стиле, в каком написан остальной код. Другими словами, если код старый, не стоит поддаваться соблазну использовать новые красивые технологии — такой код потом будет очень тяжело читать. Например, вы можете столкнуться с ситуацией, которая была у нас — часть системы написана на Spring MVC, а часть — на голых сервлетах. И если в части, написанной на сервлетах, нужно дописать еще что-то, то дописываем мы это так же — на сервлетах.
Соблюдать бизнес-интересы
Нужно всегда помнить, что любые задачи обусловлены прежде всего ценностью для бизнеса. Если вы не докажете заказчику необходимость тех или иных изменений с точки зрения бизнеса, этих изменений не будет. А для того, чтобы убедить заказчика, вы должны попробовать встать на его место и понять его интересы. В частности, если вам хочется провести рефакторинг только потому, что код плохо читается, вам не дадут этого сделать, и с этим нужно смириться. Если совсем уж невмоготу, реорганизовывать код можно по-тихому и понемногу, размазывая работу по бизнес-тикетам. Либо убедить заказчика в том, что это, например, сократит время, необходимое для поиска ошибок, а значит, в конечном итоге сократит расходы.
Тестировать
Понятно, что тестирование необходимо в любом проекте. Но при работе с legacy-системами тестированию нужно уделять особое внимание еще и потому, что влияние вносимых изменений не всегда предсказуемо. Тестировщиков потребуется не меньше, чем разработчиков, в противном случае у вас должно быть все просто невероятно хорошо с автоматизацией.
В нашем проекте тестирование состояло из следующих фаз:
- Верификация, когда реализованный функционал фичи проверяется в отдельной ветке.
- Стабилизация, когда проверяется ветка релиза, в которой все фичи слиты вместе.
- Сертификация, когда все то же самое прогоняется еще раз на немного других тест-кейсах в сертификационном окружении, максимально приближенном к продакшну по характеристикам железа и конфигурации.
И только после прохождения всех этих трех фаз мы можем делать релиз. Кто-то наверняка считает, что сертификация — лишняя фаза, так как на стадии стабилизации все уже выяснено, но наш опыт говорит о том, что это не так — иногда во время регрессионного теста, который прогоняется по второму кругу на другой машине, что-нибудь да вылезет.
Формализовать DevOps и релиз
При работе с legacy-системой важно наладить все, что касается DevOps и прочих практик, напрямую не связанных с разработкой. В частности, очень хорошо совместно с девопсами на стороне заказчика прописать определенную процедуру релиза, каждый шаг которой будет строго документирован. Только тогда процесс становится предсказуемым и ясным для каждого из участников.
Релизная процедура может быть, например, следующей. Когда заканчивается разработка и пройдены две или три фазы тестирования, мы пишем письмо DevOps-команде за 36 часов до предполагаемого времени релиза. После этого созваниваемся с девопсами и обсуждаем все изменения окружений (мы сообщаем им обо всех изменениях в БД и конфигурации). На каждое изменение у нас есть документ (тикет в Jira). Затем во время релиза все причастные к этому собираются вместе, и каждый говорит, что он сейчас делает: «Мы залили базу», «Мы перезапустили такие-то серверы», «Мы пошли прогонять регрессионные тесты в рабочем окружении». Если же что-то идет не так, запускается процедура отката релиза, точно описанная в изначальном документе на релиз — без такого документа мы обязательно что-нибудь забудем или напутаем (вспомните, в какое время суток обычно происходят релизы).
Выстроить branching strategy
Основные модели бренчинга давно описаны на сайте того же Atlassian, их можно адаптировать под ваши нужды. Главное — ни в коем случае не коммитить изменения сразу в транк: должны быть stable trunk и feature branches. Я советую делать релизы из релизных веток, а не из транка. То есть у вас есть транк, от которого отходят ветки на конкретные фичи, соответствующие тикетам в Jira. Когда вы закончили разработку в спринте, вы собираете отдельную релизную ветку из готовых фич и ее сертифицируете. Если же что-то пойдет не так, из такой ветки можно будет легко устранить то, что по какой-то причине из релиза в итоге выпадает. Когда же релиз произошел, релизная ветка вливается в stable trunk.
Контролировать качество кода
И наконец, code review — это, казалось бы, достаточно очевидная практика, к которой прибегают почему-то далеко не во всех проектах. Очень хорошо, если каждая часть кода проверяется более чем одним человеком. Даже в очень сильной команде в процессе code review обязательно обнаруживаются какие-то косяки, а если смотрят несколько человек, количество выявленных косяков возрастает. Иногда самое страшное находит третий или четвертый reviewer. Но во избежание как саботажа, так и излишнего фанатизма, необходимо договориться, сколько review достаточно для того, чтобы считать фичу готовой.
Для проверки можно использовать пул-реквесты (конечно, если у вас Git), далее есть Crucible и FishEye — оба прикручиваются к Jira. И наконец существует очень удобный инструмент Review Board, который работает и с SVN, и с Git. Он позволяет послать запрос на проверку кода, который соберет в себе все изменения в данном feauture branch.

Управление проектом
Подбор команды
Самое первое, что должен помнить Team Lead или PM при наборе людей в проект — далеко не всем разработчикам подходит работа с legacy-системами. Даже если человек пишет замечательный код, не факт, что он сможет целыми днями сидеть с дебаггером или документировать чужой код. Для работы с legacy, кроме технических навыков, требуются еще определенные личностные качества — хорошее чувство юмора, самоирония и, конечно же, терпение. На эти качества нужно обращать внимание при подборе людей в команду, а если кто-то не сошелся с legacy характерами, то не воевать с ним, а заменять. Замена человека в проекте в подобном случае не волчий билет, а облегчение и для него, и для команды.
Глупые вопросы
Тимлид не должен стесняться задавать команде «глупые» вопросы и напоминать обо всех вышеперечисленных приемах работы. «Я накатил свежий код, и теперь ничего не работает!» — «А какую ветку ты взял? А базу обновил? А что в логах? А дебажил?» Несмотря на всю свою простоту, такие диалоги — неотъемлемый элемент нашей работы, и в особенности с legacy-проектами. Нужно удерживать все в голове и не уставать снова и снова напоминать о каких-то очевидных и не очень очевидных вещах. Без этого, поверьте, не обойтись!
Процесс, или «здесь так принято»
В силу американской текучки кадров новые менеджеры со стороны заказчика приходят в проект чаще, чем нам хотелось бы. И многие из них, еще не разобравшись в специфике legacy, пытаются внедрять практики и решения из своего предыдущего опыта. Им нужно терпеливо объяснять, почему здесь принято именно так, а не по книжке. Сначала такие вещи донести бывает трудно, но в конечном итоге либо заказчик согласится с вами, либо вы вместе придете к компромиссному решению.
В работе с legacy-системами действительно важен правильно выстроенный, понятный и прозрачный процесс: Jira (или аналог) обязательно должна отражать реальное положение дел в данный момент. Все требования должны быть ясно сформулированы, а процессы четко прописаны. Вся эта Jira-бюрократия точно окупится, сильно снизив степень энтропии в проекте. Так, когда к вам придет заказчик и потребует срочно сделать новую фичу, вы сможете просто показать заполненное расписание. Тогда он легче сможет понять, что чем-то придется пожертвовать.
Что касается эстимэйта (вы же используете Planning Poker, правда?), то оценивать всегда нужно с запасом, чтобы быть готовым к сюрпризам — как мы уже говорили, влияния в незнакомом нам коде зачастую неясны, и порой может вылезать что-то совершенно неожиданное и в неожиданных местах. Так, у нас в проекте был случай, когда изменения в простом CSS сломали часть бизнес-логики: кто-то поставил в JS проверку на цвет элемента интерфейса.
Бизнес, tech debt и SWAT
При работе с legacy-системами нужно стараться противостоять потоку бизнес-требований, которые заказчик будет вам непрерывно поставлять. Заказчик не всегда осознает риски, связанные со стабильностью системы, поэтому вам придется постоянно о них напоминать. Бороться с этими рисками можно двумя способами: балансированием бизнес и стабилизационных задач в каждом спринте или отдельными стабилизационными проектами. Оптимальным кажется баланс 70 на 30, когда 30% времени каждого спринта вы занимаетесь стабилизацией. Впрочем, заказчик скорее всего не даст вам сделать все, что вы хотите — поэтому записывайте технический долг по мере обнаружения. Из этого tech debt вы будете брать задачи на вышеупомянутые 30%. А может, заказчик согласится на стабилизационный проект, особенно если вы покажете ему tech debt в ответ на вопрос, почему все в очередной раз упало.
Для экстренных случаев я советую иметь SWAT — «группы специального назначения», которые смогут быстро решать непредвиденные проблемы в любое время суток. Ведь если система вдруг завалится, заказчик тут же начнет вам звонить и в 2 часа ночи, и в 4 утра — это мы проверили на своем опыте. Поэтому хорошо бывает договориться, кто в какое время дежурит на случай таких происшествий. Это должны быть быстро соображающие люди, которые могут сидеть допоздна, соответственно, чаще всего, не семейные. Но основная их задача — это все-таки, брейнсторминг днем. В этом есть особый инженерный кайф — в стрессовой ситуации оперативно находить ошибки в чужом коде, понимая, что спасаешь мир в рамках отдельно взятой системы.

Примеры оптимизации
А теперь вкратце расскажу о способах оптимизации, которыми мы пользовались в разное время.
Во-первых, нужно уйти от традиции ежедневных перезапусков, если так было принято в проекте. Однако делать это нужно, конечно, с осторожностью — продолжать проверять логи и следить за всем, что может привести к падению системы, и бороться с этим. У нас была система, которые перезапускалась каждую ночь, так как не могла прожить и двух суток из-за memory и других leaks — теперь же она совершенно стабильно работает от релиза до релиза две-три недели (за редкими исключениями, о которых мы обычно узнаем в 4 утра).
А вот хороший пример того, как делать не нужно. У нас была система, несколько компонентов которой периодически отваливались. Тогда со стороны заказчика пришел девопс и написал скрипты, которые по логам анализируют активность этих компонентов, и если в логе три минуты нет записей, то эти службы перезапускаются. Это, конечно, сработало, но такие вещи должны однажды плохо кончиться.
Очень важный момент — проход по всем логам и составление отдельного эпика. Бывают, конечно, заказчики, которые долго не дают доступа к продакшн-логу. У нас, например, так продолжалось полгода, после чего случился переломный момент, когда нас самих попросили посмотреть логи продакшна. Просмотр затянулся на всю ночь. В системе, работавшей, как считалось, штатно и стабильно, нормальные логи попадались лишь иногда — в основном же записи были со сдвигом вправо и начинались с «at». Это были сплошные стектрейсы, и их набиралось на десятки мегабайт в сутки. Конечно, мы завели эпик в Jira и создали тикеты на отдельные exceptions. Затем нам пришлось несколько месяцев выбивать время на стабилизационный проект. В итоге мы исправили множество ошибок, о которых никто не догадывался, и сделали логи информативными. Теперь любой стектрейс в них — действительно признак нештатной ситуации.
Еще советую обращать внимание на третьесторонние зависимости как на front-end (Google Tag Manager, Adobe Tag Manager и т. п.), так и на back-end. Например, если у нас на странице есть JavaScript со сторонних ресурсов, нужно посмотреть, завернуты ли эти скрипты в try..catch блоки. У нас были случаи, когда сайт падал из-за того, что ломался какой-то скрипт на стороне. Также важно предусматривать возможность недоступности любых внешних ресурсов.
Ну и последнее: следите за всем, за чем только можно, и грамотно агрегируйте логи. Ведь у вас может быть 12 продакшн-серверов, и вас могут попросить их логи посмотреть, что точно нужно делать не через tail. Мы использовали ELK — связку Elastic search — Logstash — Kibana. Очень полезен мониторинг: мы навесили Java Melody на все серверы и получили огромное количество новой информации, на основании которой многое исправили, осчастливив заказчика.
Кофе-брейк #20. Что такое legacy-код и как с ним работать. Инструменты, которые облегчают написание технической документации


Источник: Dou Рано и поздно программисту наверняка придется встретиться с legacy-кодом. Чтобы облегчить последствия этого знакомства, я подобрал несколько практических советов и примеров из собственного опыта — в частности, работы с унаследованной Java-системой.
Особенности legacy
- с устаревшей технологией;
- неоднородной архитектурой;
- недостатком или даже полным отсутствием документации.
Мы не можем неуважительно относиться к системе, которая зарабатывает миллионы, или к которой обращаются тысячи людей в день. Как бы плохо она ни была написана, этот отвратительный код дожил до продакшена и работает в режиме 24/7.
Раз эта система приносит реальные деньги, работа с ней сопряжена с большой ответственностью. Это не стартап в стол, а то, с чем пользователи будут работать уже завтра. Это подразумевает и очень высокую цену ошибки, причем дело здесь не в претензиях клиента, а в реальном положении вещей.
Обратный инжиниринг
Не переписывайте код
Соблюдайте бизнес-интересы
Тестируйте
- Верификация, когда реализованный функционал фичи проверяется в отдельной ветке.
- Стабилизация, когда проверяется ветка релиза, в которой все фичи слиты вместе.
- Сертификация, когда все то же самое прогоняется еще раз на немного других тест-кейсах в сертификационном окружении, максимально приближенном к продакшену по характеристикам железа и конфигурации.
Формализуйте DevOps и релиз
Контролируйте качество кода
Инструменты, которые облегчают написание технической документации

Источник: Dzone Большинство программистов не любят писать техническую документацию. Эксперт по психологии Джеральд Вайнберг даже назвал документацию «касторовым маслом программирования»: разработчики любят ее читать, но сами писать просто ненавидят. Отсутствие руководства или пустая дорожная карта приводят к нехватке информации о том, как работают различные части программного обеспечения. В конечном итоге это ухудшает восприятие ситуации конечными пользователями кода, поскольку при отсутствии документации они не могут полагаться на точность и полезность продукта. Чтобы программисту было легче сформировать у себя привычку писать документацию, я рекомендую обратить внимание на четыре отличных инструмента, доступных сейчас практически каждому.