Еще один способ разложения сигнала в спектр
Привет всем, здесь я хочу рассказать про алгоритм анализа звукового сигнала, позволяющий разобрать сигнал на отдельные волны, конечно 100% точности он не дает, но тем не менее результат на мой взгляд довольно неплох.
Лучше всего видна работа на какой-нибудь музыке:
И ссылки на другие примеры разных жанров. Metaldeth-Tornado of souls:
Итак для разложения нужно сделать следующие шаги:
— Из исходного сигнала нужно получить 8 промежуточных сигналов;
— Из этих промежуточных сигналов и исходного сигнала нужно получить 8 сигналов — слоев, которые можно будет разобрать на отдельные волны;
— Посчитать сколько в каждом слое волн и какая у них амплитуда.
Теперь подробнее о каждом этапе: для того чтобы получить промежуточный сигнал нужно взять производную от исходного сигнала. По сути это производная дискретной функции. Чтобы найти ее для каждого момента исходного сигнала нужно задать 1 параметр: период за который эта производная находится. Значение производной это коэффициент наклона в заданном интервале, можно найти например методом наименьших квадратов.
Требуется вычислить 8 промежуточных сигналов с 8 разными периодами. Самый простой набор периодов: 4, 8, 16, 32, 64, 128, 256, 512. Когда период задан, для каждого отсчета сигнала вычисляется производная по формуле наименьших квадратов. Это как скользящее среднее, только здесь не скользящее среднее а скользящая производная текущего интервала.
Таким образом получается 8 производных сигналов и 1 исходный. Теперь каждый из 8 производных сигналов нужно проинтегрировать. В данном случае это значит что каждый следующий семпл равен сумме всех предыдущих семплов. После этого получается 8 промежуточных слоев.
Следующий шаг — получение слоев, которые можно будет разобрать на отдельные волны. Итак теперь нужно получить 8 слоев. Слои вычисляются так:
слой0=промежуточный0-исх сигнал
слой1=промежуточный1-промежуточный0
слой2=промежуточный2-промежуточный1
слой3=промежуточный3-промежуточный2
слой4=промежуточный4-промежуточный3
слой5=промежуточный5-промежуточный4
слой6=промежуточный6-промежуточный5
слой7=промежуточный7-промежуточный6
слой8=промежуточный7
Последний слой является не разницей а просто равен последнему промежуточному сигналу.
Можно попробовать и по другому, а именно вычислять последующие промежуточные сигналы из предыдущих промежуточных. Но в текущей программе используется 1 вариант.
Теперь чтобы разобрать слои на отдельные волны нужно просто посчитать участки где значения увеличиваются и где они уменьшаются. Собственно длительность участков и есть их длины волн. Участки сигнала где значения сигнала постоянны нужно просто пропустить. Чтобы найти амплитуду сигнала в спектре в некотором интервале, нужно сложить все амплитуды волн умноженные на их длину.
Код который вычисляет промежуточный сигнал выглядит вот так:
здесь wavesize – число семплов
signal[] – массив с исходным сигналом
SY=0,SX=0,SXX=0,SXY=0,Ky=0 — переменные типа float
Step2=STEP/2 где STEP это период (4,8,16,32,64,128,256,512)
Чтобы вычесть один сигнал из другого достаточно просто вычесть каждый семпл из каждого.
Например для 0 слоя:
Если сложить все слои, и взять последний с обратным знаком то получится исходный сигнал, таким образом умножая какой-нибудь слой, возможно сделать фильтр частот. Далее вопрос заключается в том как считать амплитуды конкретных гармоник. Дело в том что в постоянном интервале, например = 4000 семплов, может быть очень много коротких волн и сравнительно мало длинных.
Можно конечно найти средние амплитуды для каждого слоя и сложить. Но этот способ не очень хорош так как длинных волн очень мало, а их амплитуда обычно очень большая, и получается сильная неравномерность амплитуды в сторону низких частот.
В программе, которая отображает цветомузыку по ссылкам, амплитуда каждой гармоники подсчитывается как: амплитуда волны*ее длину. Все равно возникает неравномерность, но не такая сильная как в случае с усреднением.
Вообще, не думаю что человек воспринимает звук как разложение в спектр, скорее звук состоит из звуковых образов, которые состоят из волн разной длинны. Соответственно громкость какого либо звука это скорее средняя громкость всех волн из которых звук состоит. Но пока что не понятно какие параметры составляют звуковой образ, возможно средняя частота, стандартное отклонение или что то еще.
Как разложить звук на спектр
Спектроанализатор – прибор для измерения и отображения спектра сигнала – распределения энергии сигнала по частотам. В этой статье рассматриваются основные виды анализаторов спектра и иллюстрируется их применение для редактирования и реставрации звука. Особое внимание уделяется современным анализаторам, основанным на FFT – быстром преобразовании Фурье.
Зачем анализировать спектр?
Традиционно в цифровой звукозаписи аудиодорожка представляется в виде осциллограммы, отображающей форму звуковой волны (waveform), то есть зависимость амплитуды звука от времени. Такое представление достаточно наглядно для опытного звукорежиссёра: осциллограмма позволяет увидеть основные события в звуке, такие как изменения громкости, паузы между частями произведения и зачастую даже отдельные ноты в сольной записи инструмента. Но одновременное звучание нескольких инструментов на осциллограмме "смешивается" и визуальный анализ сигнала становится затруднительным. Тем не менее, наше ухо без труда различает отдельные инструменты в небольшом ансамбле. Как же это происходит?
Когда сложное звуковое колебание попадает на барабанную перепонку уха, оно с помощью серии слуховых косточек передаётся на орган, называемый улиткой. Улитка представляет собой закрученную в спираль эластичную трубочку. Толщина и жёсткость улитки плавно меняются от края к центру спирали. Когда сложное колебание поступает на край улитки, это вызывает ответные колебания разных частей улитки. При этом резонансная частота у каждой части улитки своя. Таким образом улитка раскладывает сложное звуковое колебание на отдельные частотные составляющие. К каждой части улитки подходят отдельные группы слуховых нервов, передающие информацию о колебаниях улитки в головной мозг (более подробно о слуховом восприятии можно прочитать в статье "Основы психоакустики" И. Алдошиной в журнале "Звукорежиссер" №6, 1999). В результате в мозг поступает информация о звуке, уже разложенная по частотам, и человек легко отличает высокие звуки от низких. Кроме того, как мы вскоре увидим, разложение звука на частоты помогает различить отдельные инструменты в полифонической записи, что значительно расширяет возможности редактирования.
Полосовые спектроанализаторы
Первые звуковые анализаторы спектра разделяли сигнал на частотные полосы с помощью набора аналоговых фильтров. Дисплей такого анализатора (рис. 1) показывает уровень сигнала во множестве частотных полос, соответствующих фильтрам.
На рис. 2 приведён пример частотных характеристик полосовых фильтров в анализаторе, удовлетворяющем стандарту ГОСТ 17168-82. Такой анализатор называется третьоктавным, так как в каждой октаве частотного диапазона имеется три полосы. Видно, что частотные характеристики полосовых фильтров перекрываются; их крутизна зависит от порядка используемых фильтров.
Важным свойством спектроанализатора является баллистика – инерционность измерителей уровня в частотных полосах. Она может регулироваться заданием скорости нарастания (атаки) и спада уровня. Типичное время атаки и спада в таком анализаторе – порядка 200 и 1500 мс.
Полосовые спектроанализаторы часто применяются для настройки АЧХ (амплитудно-частотной характеристики) акустических систем на концертных площадках. Если на вход такому анализатору подать розовый шум (имеющий одинаковую мощность в каждой октаве), то дисплей покажет горизонтальную линию, с возможной поправкой на вариацию шума во времени. Если розовый шум, проходя через звукоусилительную систему зала, исказился, то изменения его спектра будут видны на анализаторе. При этом анализатор, как и наше ухо, будет малочувствителен к узким провалам АЧХ (менее 1/3 октавы).
Преобразование Фурье
Преобразование Фурье – это математический аппарат для разложения сигналов на синусоидальные колебания. Например, если сигнал x(t) непрерывный и бесконечный по времени, то его можно представить в виде интеграла Фурье:
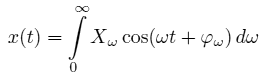
Интеграл Фурье собирает сигнал x(t) из бесконечного множества синусоидальных составляющих всевозможных частот ω, имеющих амплитуды Xω и фазы φω.
На практике нас больше интересует анализ конечных по времени звуков. Поскольку музыка не является статичным сигналом, её спектр меняется во времени. Поэтому при спектральном анализе нас обычно интересуют отдельные короткие фрагменты сигнала. Для анализа таких фрагментов цифрового аудиосигнала существует дискретное преобразование Фурье:
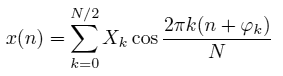
Здесь N отсчётов дискретного сигнала x(n) на интервале времени от 0 до N–1 синтезируются как сумма конечного числа синусоидальных колебаний с амплитудами Xk и фазами φk. Частоты этих синусоид равны kF/N, где F – частота дискретизации сигнала, а N – число отсчётов исходного сигнала x(n) на анализируемом интервале. Набор коэффициентов Xk называется амплитудным спектром сигнала. Как видно из формулы, частоты синусоид, на которые раскладывается сигнал, равномерно распределены от 0 (постоянная составляющая) до F/2 – максимально возможной частоты в цифровом сигнале. Такое линейное расположение частот отличается от распределения полос третьоктавного анализатора.
FFT-анализаторы
FFT (fast Fourier transform) – алгоритм быстрого вычисления дискретного преобразования Фурье. Благодаря ему стало возможным анализировать спектр звуковых сигналов в реальном времени.
Рассмотрим работу типичного FFT-анализатора. На вход ему поступает цифровой аудиосигнал. Анализатор выбирает из сигнала последовательные интервалы («окна»), на которых будет вычисляться спектр, и считает FFT в каждом окне для получения амплитудного спектра Xk. Вычисленный спектр отображается в виде графика зависимости амплитуды от частоты (рис. 3). Аналогично полосовым анализаторам, обычно используется логарифмический масштаб по осям частот и амплитуд. Но из-за линейного расположения полос FFT по частоте спектр может выглядеть недостаточно детальным на нижних частотах или излишне осциллирующим на верхних частотах.
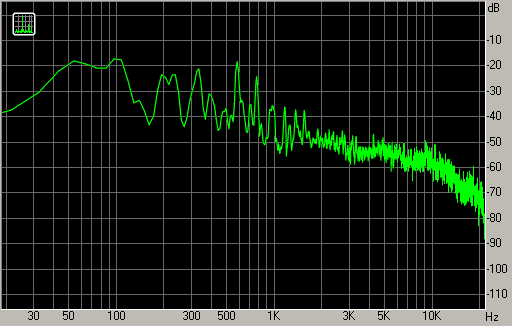
Если рассматривать FFT как набор фильтров, то, в отличие от полосовых фильтров третьоктавного анализатора, фильтры FFT будут иметь одинаковую ширину в герцах, а не в октавах. Поэтому розовый шум на FFT-анализаторе будет уже не горизонтальной линией, а наклонной, со спадом 3 дБ/окт. Горизонтальной линией на FFT-анализаторе будет белый шум – он содержит равную энергию в равных линейных частотных интервалах.
Параметр N – число анализируемых отсчётов сигнала – имеет решающее значение для вида спектра. Чем больше N, тем плотнее сетка частот, по которым FFT раскладывает сигнал, и тем больше деталей по частоте видно на спектре. Для достижения более высокого частотного разрешения приходится анализировать более длинные участки сигнала. Если сигнал в пределах окна FFT меняет свои свойства, то спектр будет отображать некоторую усреднённую информацию о сигнале со всего интервала окна.
Когда нужно проанализировать быстрые изменения в сигнале, длину окна N выбирают маленькой. В этом случае разрешение анализа по времени увеличивается, а по частоте – уменьшается. Таким образом, разрешение анализа по частоте обратно пропорционально разрешению по времени. Этот факт называется соотношением неопределённостей.
Весовые окна
Один из простейших звуковых сигналов – синусоидальный тон. Как будет выглядеть его спектр на FFT-анализаторе? Оказывается, это зависит от частоты тона. Мы знаем, что FFT раскладывает сигнал не по тем частотам, которые на самом деле присутствуют в сигнале, а по фиксированной равномерной сетке частот. Например, если частота дискретизации равна 48 кГц и размер окна FFT выбран 4096 отсчётов, то FFT раскладывает сигнал по 2049 частотам: 0 Гц, 11.72 Гц, 23.44 Гц, . 24000 Гц.
Если частота тона совпадает с одной из частот сетки FFT, то спектр будет выглядеть "идеально": единственный острый пик укажет на частоту и амплитуду тона (рис. 4, белый график).
Если же частота тона не совпадает ни с одной из частот сетки FFT, то FFT "соберёт" тон из имеющихся в сетке частот, скомбинированных с различными весами. График спектра при этом размывается по частоте (рис. 4, зелёный график). Такое размытие обычно нежелательно, так как оно может закрыть собой более слабые звуки на соседних частотах. Можно также заметить, что амплитуда максимума зелёного графика ниже реальной амплитуды анализируемого тона. Это связано с тем, что мощность анализируемого тона равна сумме мощностей коэффициентов спектра, из которых этот тон составлен.
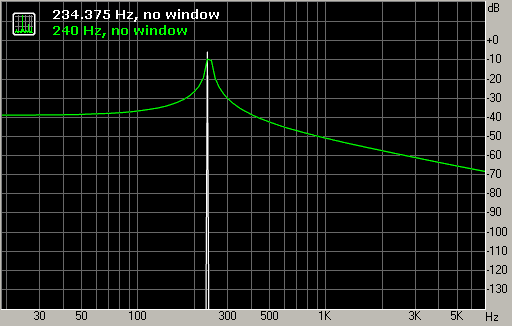
Чтобы уменьшить эффект размытия спектра, сигнал перед вычислением FFT умножается на весовые окна – гладкие функции, похожие на гауссиан, спадающие к краям интервала. Они уменьшают размытие спектра за счёт некоторого ухудшения частотного разрешения. Если рассматривать FFT как набор полосовых фильтров, то весовые окна регулируют взаимное проникновение частотных полос.
Простейшее окно – прямоугольное: это константа 1, не меняющая сигнала. Оно эквивалентно отсутствию весового окна. Одно из популярных окон – окно Хэмминга. Оно уменьшает уровень размытия спектра примерно на 40 дБ относительно главного пика.
Весовые окна различаются по двум основным параметрам: степени расширения главного пика и степени подавления размытия спектра ("боковых лепестков"). Чем сильнее мы хотим подавить боковые лепестки, тем шире будет основной пик. Прямоугольное окно меньше всего размывает верхушку пика, но имеет самые высокие боковые лепестки. Окно Кайзера обладает параметром, который позволяет выбирать нужную степень подавления боковых лепестков.
Другой популярный выбор – окно Хана. Оно подавляет максимальный боковой лепесток слабее, чем окно Хэмминга, но зато остальные боковые лепестки быстрее спадают при удалении от главного пика. Окно Блэкмана обладает более сильным подавлением боковых лепестков, чем окно Хана.
Для большинства задач не очень важно, какой именно вид весового окна использовать. Главное, чтобы оно было. Популярный выбор – Хан или Блэкман. Использование весового окна уменьшает зависимость формы спектра от конкретной частоты сигнала и от её совпадения с сеткой частот FFT.
Рисунок 4 сделан для синусоид, однако, исходя из него, нетрудно представить, как будет выглядеть спектр реальных звуковых сигналов. Каждый пик в спектре будет иметь некоторую размытую форму, в зависимости от своей частоты и выбранного весового окна.
Чтобы компенсировать расширение пиков при применении весовых окон, можно использовать более длинные окна FFT: например, не 4096, а 8192 отсчета. Это улучшит разрешение анализа по частоте, но ухудшит по времени.
Спектрограмма
Часто возникает необходимость проследить, как спектр сигнала меняется во времени. FFT-анализаторы помогают сделать это в реальном времени при воспроизведении сигнала. Однако в ряде случаев оказывается удобна визуализация изменения спектра во всём звуковом отрывке сразу. Такое представление сигнала называется спектрограммой. Для её построения применяется оконное преобразование Фурье: спектр вычисляется от последовательных окон сигнала (рис. 5), и каждый из этих спектров образует столбец в спектрограмме. 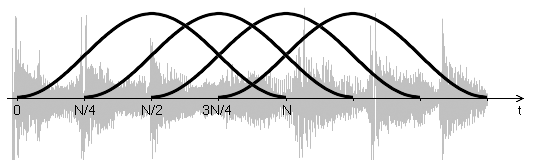
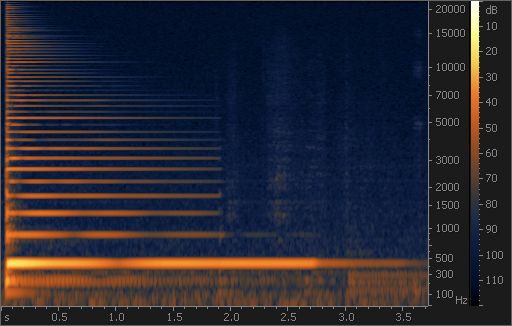
По горизонтальной оси спектрограммы откладывается время, по вертикальной – частота, а амплитуда отображается яркостью или цветом. На спектрограмме гитарной ноты на рис. 6 видно развитие звучания: оно начинается с резкой атаки и продолжается в виде гармоник, кратных по частоте основному тону 440 Гц. Видно, что верхние гармоники имеют меньшую амплитуду и затухают быстрее, чем нижние. Также на спектрограмме прослеживается шум записи – равномерный фон тёмно-синего цвета. Справа показана шкала соответствия цветов и уровней сигнала (в децибелах ниже нуля).
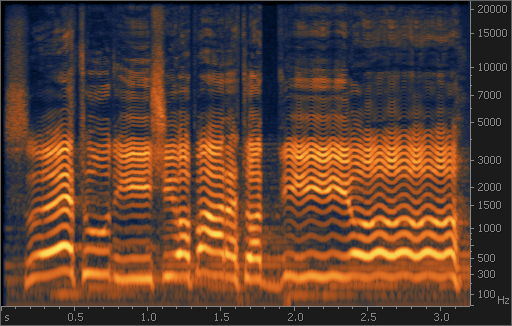
Если менять размер окна FFT, становится хорошо видно, как меняется частотное и временное разрешение спектрограммы. При увеличении окна гармоники становятся тоньше, и их частота может быть определена более точно. Однако размывается во времени момент атаки (в левой части спектрограммы). При уменьшении размера окна наблюдается обратный эффект.
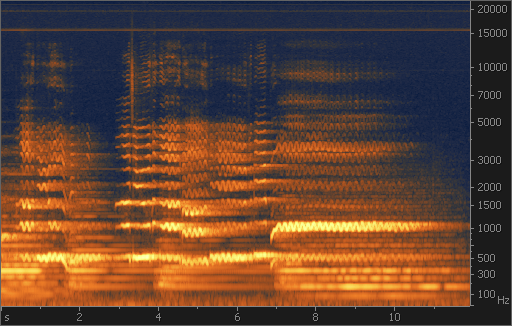
Особенно полезна спектрограмма при анализе быстро меняющихся сигналов. На рис. 7 показана спектрограмма вокального пассажа с вибрато. По ней легко определить такие характеристики голоса, как частота и глубина вибрато, его форма и ровность, наличие певческой форманты. По изменению высоты основного тона и гармоник прослеживается исполняемая мелодия.
Применения спектрограммы
Современные средства реставрации звука, такие как программа iZotope RX, активно используют спектрограмму для редактирования отдельных частотно-временных областей в сигнале. С помощью этой техники можно найти и подавить такие нежелательные призвуки, как звонок мобильного телефона во время важной записи, скрип стула пианиста, кашель в зрительном зале и т.п.
Проиллюстрируем использование спектрограммы для удаления свиста поклонников из концертной записи.
На рис. 8 свист легко находится: это светлая кривая линия в районе 3 кГц. Если бы частота свиста была постоянной, то его можно было бы подавить с помощью режекторного фильтра. Однако в нашем случае частота меняется. Для выделения свиста на спектрограмме удобно воспользоваться инструментом «волшебная палочка» из программы iZotope RX II. Одно нажатие приводит к выделению основного тона свиста, повторное нажатие выделяет гармоники. После этого свист можно удалить, просто нажав на клавишу Del. Однако более аккуратный способ – воспользоваться модулем Spectral Repair: это позволит избежать "дыр" в спектре после удаления свиста. После применения этого модуля в режиме ослабления с вертикальной интерполяцией (Attenuate vertically) свист практически полностью исчезает из записи: как визуально, так и на слух.
Еще одно полезное применение спектрограммы – анализ присутствия в записи следов компрессии MP3 или других кодеков с потерями. У большинства записей оригинального (несжатого) качества частотный диапазон простирается до 20 кГц и выше; при этом энергия сигнала плавно спадает с ростом частоты (как на рис. 6, 7). В результате психоакустической компрессии верхние частоты сигнала квантуются сильнее нижних, и верхняя граница спектра сигнала обнуляется (как на рис. 8). При этом частота среза зависит от содержания кодируемого сигнала и от битрейта кодера. Ясно, что кодер стремится обнулять только те частоты в сигнале, которые в данный момент не слышны (замаскированы). Поэтому частота среза, как правило, меняется во времени, что образует на спектрограмме характерную "бахрому" с островками энергии на тёмном фоне.
Спектрограмма часто позволяет найти в записи дефекты, которые неочевидны при прослушивании, но могут сказаться при последующей обработке. Например, паразитная наводка от ЭЛТ-видеомонитора на частоте 15–16 кГц может ускользнуть от уха пожилого звукорежиссёра. Однако спектрограмма ясно покажет её в виде горизонтальной линии (рис. 9) и позволит уточнить частоту для настройки режекторного фильтра.
Аналогичная ситуация иногда возникает и с низкочастотными помехами, такими как задувание ветра в микрофон или постоянная составляющая (смещение по постоянному току, DC offset). Они могут располагаться на инфранизких частотах и не обнаруживать себя без помощи спектроанализатора или осциллографа.
Заключение
Среди опытных звукорежиссёров старой школы распространено мнение, что анализировать и редактировать сигналы следует исключительно на слух, не полагаясь на индикаторы и анализаторы. Разумеется, анализаторы – не панацея в случае отсутствия слуха. Вряд ли кто-то серьёзно воспринимает идею сведения композиции "по приборам".
Не отрицая важности критического прослушивания звука на каждой стадии редактирования, мы всё же предлагаем использовать анализаторы спектра в тех задачах, где это может привести к более точным результатам. Конечно, можно определить на слух паразитный тон на частоте 15 кГц и подобрать режекторный фильтр подходящей добротности для его удаления. Но намного проще увидеть этот тон на спектроанализаторе и сразу более точно оценить его свойства: "плывёт" ли частота, есть ли боковые пики. В конечном счёте, это позволит более аккуратно удалить помеху. Аналогичная ситуация и со многими другими задачами редактирования, особенно – в реставрации звука.
Спектр и спектрограмма – способы представления звука, более близкие к слуховому восприятию, нежели осциллограмма. Надеюсь, что эта статья откроет новые возможности в анализе и редактировании звука для тех, кто ранее с этими представлениями не работал.
Понимание аудиоданных, преобразования Фурье, БПФ, спектрограммы и распознавания речи

Ежедневно почти в каждой организации генерируется огромное количество аудиоданных. Аудиоданные дают важные стратегические идеи, когда они легко доступны для специалистов по обработке данных для использования в двигателях искусственного интеллекта и аналитике. Организации, которые уже осознали мощь и важность информации, поступающей из аудиоданных, используют записанные разговоры с помощью ИИ (искусственного интеллекта) для улучшения обучения своего персонала, обслуживания клиентов и улучшения общего качества обслуживания клиентов.
С другой стороны, есть организации, которые не могут лучше использовать свои аудиоданные из-за следующих препятствий: 1. Они не записывают их. 2. Качество данных плохое. Эти препятствия могут ограничить потенциал решений машинного обучения (движков ИИ), которые они собираются реализовать. Очень важно собрать все возможные данные, причем в хорошем качестве.
Эта статья содержит пошаговое руководство, чтобы начать обработку аудиоданных. Хотя это поможет вам приступить к базовому анализу, никогда не бывает плохой идеей получить базовое представление о звуковых волнах и основных методах обработки сигналов, прежде чем переходить к этой области. Вы можете щелкнуть здесь и прочитать мою статью о звуковых волнах. Эта статья дает общее представление о звуковых волнах, а также немного объясняет различные аудиокодеки.
Прежде чем идти дальше, давайте перечислим содержание, которое мы собираемся осветить в этой статье. Давайте последовательно рассмотрим каждую из следующих тем:
- Чтение аудиофайлов
- Преобразование Фурье (FT)
- Быстрое преобразование Фурье (БПФ)
- Спектрограмма
- Распознавание речи с использованием функций спектрограммы
- Заключение
1. Чтение аудиофайлов
LIBROSA
LibROSA — это библиотека Python, в которой есть почти все утилиты, которые могут вам понадобиться при работе с аудиоданными. Эта богатая библиотека предлагает большое количество различных функций. Вот краткий обзор функций —
- Загрузка и отображение характеристик аудиофайла.
- Спектральные представления
- Извлечение функций и манипуляции
- Преобразования частоты и времени
- Временная сегментация
- Последовательное моделирование… и т. д.
Поскольку эта библиотека огромна, мы не будем говорить обо всех ее функциях. Мы просто собираемся использовать несколько общих функций для нашего понимания.
Загрузка аудио в Python
Librosa поддерживает множество аудиокодеков. Хотя .wav (без потерь) широко используется при анализе аудиоданных. После того, как вы успешно установили и импортировали libROSA в свой блокнот jupyter. Вы можете прочитать данный аудиофайл, просто передав путь к файлу функции librosa.load() .
librosa.load() — ›функция возвращает две вещи: 1. Массив амплитуд. 2. Частота дискретизации. Частота дискретизации относится к частоте дискретизации, используемой при записи аудиофайла. Если вы сохраните аргумент sr = None , он загрузит ваш аудиофайл с исходной частотой дискретизации. (Примечание. Вы можете указать собственную частоту дискретизации в соответствии с вашими требованиями, libROSA может повысить или понизить дискретизацию сигнала за вас). Посмотрите на следующее изображение —

sampling_rate = 16k говорит, что этот звук был записан (дискретизирован) с частотой дискретизации 16k. Другими словами, при записи этого файла мы фиксировали 16000 амплитуд каждую секунду. Таким образом, если мы хотим узнать длительность звука, мы можем просто разделить количество выборок (амплитуд) на частоту дискретизации, как показано ниже —

«Да, вы можете воспроизводить звук внутри своего jupyter-ноутбука».
IPython дает нам виджет для воспроизведения аудиофайлов через ноутбук.

Визуализация аудио
У нас есть амплитуды и частота дискретизации из librosa. Мы можем легко построить график этих амплитуд с течением времени. LibROSA предоставляет служебную функцию waveplot (), как показано ниже —


Эта визуализация называется представлением данного сигнала во временной области. Это показывает нам громкость (амплитуду) звуковой волны, изменяющуюся во времени. Здесь амплитуда = 0 означает тишину. (Из определения звуковых волн — эта амплитуда на самом деле является амплитудой частиц воздуха, которые колеблются из-за изменения давления в атмосфере из-за звука).
Эти амплитуды не очень информативны, так как говорят только о громкости аудиозаписи. Чтобы лучше понять звуковой сигнал, необходимо преобразовать его в частотную область. Представление сигнала в частотной области сообщает нам, какие разные частоты присутствуют в сигнале. Преобразование Фурье — это математическая концепция, которая может преобразовывать непрерывный сигнал из временной области в частотную. Давайте узнаем больше о преобразовании Фурье.
2. Преобразование Фурье (FT)
Аудиосигнал — это сложный сигнал, состоящий из нескольких одночастотных звуковых волн, которые распространяются вместе как возмущение (изменение давления) в среде. При записи звука мы фиксируем только результирующие амплитуды этих нескольких волн. Преобразование Фурье — это математическая концепция, которая может разложить сигнал на составляющие его частоты. Преобразование Фурье не только дает частоты, присутствующие в сигнале, но также дает величину каждой частоты, присутствующей в сигнале.
Обратное преобразование Фурье прямо противоположно преобразованию Фурье. Он принимает в качестве входных данных представление заданного сигнала в частотной области и математически синтезирует исходный сигнал.
Давайте посмотрим, как мы можем использовать преобразование Фурье для преобразования нашего аудиосигнала в его частотные составляющие —
3. Быстрое преобразование Фурье (БПФ)
Быстрое преобразование Фурье (БПФ) — это математический алгоритм, который вычисляет дискретное преобразование Фурье (ДПФ) заданной последовательности. Единственная разница между FT (преобразование Фурье) и FFT состоит в том, что FT рассматривает непрерывный сигнал, а FFT принимает дискретный сигнал в качестве входного. DFT преобразует последовательность (дискретный сигнал) в ее частотные составляющие так же, как FT для непрерывного сигнала. В нашем случае у нас есть последовательность амплитуд, выбранных из непрерывного звукового сигнала. Алгоритм DFT или FFT может преобразовать этот дискретный сигнал временной области в частотный.

Простая синусоида для понимания БПФ
Чтобы понять результат БПФ, давайте создадим простую синусоидальную волну. Следующий фрагмент кода создает синусоидальную волну с частотой дискретизации = 100, амплитудой = 1 и частотой = 3. Значения амплитуды рассчитываются каждые 1/100 секунды (частота дискретизации) и сохраняются в списке с именем y1. Мы передадим эти дискретные значения амплитуды для вычисления ДПФ этого сигнала с помощью алгоритма БПФ.

Если вы нанесете эти дискретные значения (y1), сохраняя номер выборки на оси x и значение амплитуды на оси y, он сгенерирует красивый график синусоидальной волны, как показано на следующем снимке экрана —

Теперь у нас есть последовательность амплитуд, хранящаяся в списке y1. Мы передадим эту последовательность алгоритму БПФ, реализованному scipy. Этот алгоритм возвращает список yf комплексных амплитуд частот, обнаруженных в сигнале. Первая половина этого списка возвращает термины с положительной частотой, а другая половина возвращает термины с отрицательной частотой, которые аналогичны положительным. Вы можете выбрать любую половину и вычислить абсолютные значения для представления частот, присутствующих в сигнале. Следующая функция берет образцы в качестве входных данных и строит частотный график —

На следующем графике мы построили частоты для нашей синусоидальной волны, используя указанную выше функцию fft_plot. Вы можете видеть, что этот график ясно показывает одно значение частоты, присутствующее в нашей синусоиде, которое равно 3. Кроме того, он показывает амплитуду, связанную с этой частотой, которую мы оставили равной 1 для нашей синусоидальной волны.

Чтобы проверить результат БПФ для сигнала, имеющего более одной частоты, давайте создадим еще одну синусоидальную волну. На этот раз мы оставим частота дискретизации = 100, амплитуда = 2 и значение частоты = 11. Следующий код генерирует этот сигнал и строит синусоидальную волну —

Сгенерированная синусоида выглядит как на графике ниже. Было бы более плавно, если бы мы увеличили частоту дискретизации. Мы сохранили частоту дискретизации = 100, потому что позже мы добавим этот сигнал к нашей старой синусоиде.
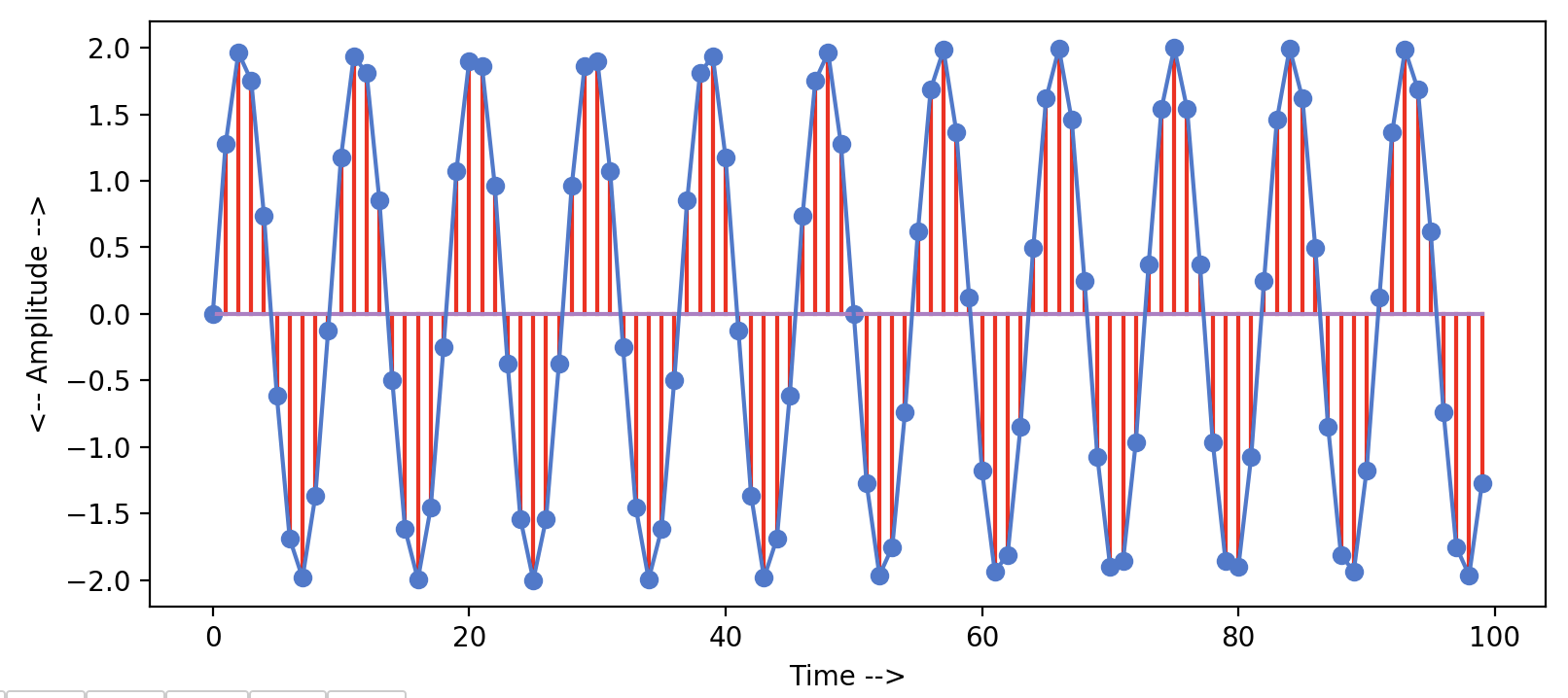
Очевидно, функция БПФ также покажет одиночный всплеск с частотой = 11 для этой волны. Но мы хотим увидеть, что произойдет, если мы сложим эти два сигнала с одинаковой частотой дискретизации, но с разными значениями частоты и амплитуды. Здесь последовательность y3 будет представлять результирующий сигнал.

Если мы построим сигнал y3, он будет выглядеть примерно так:
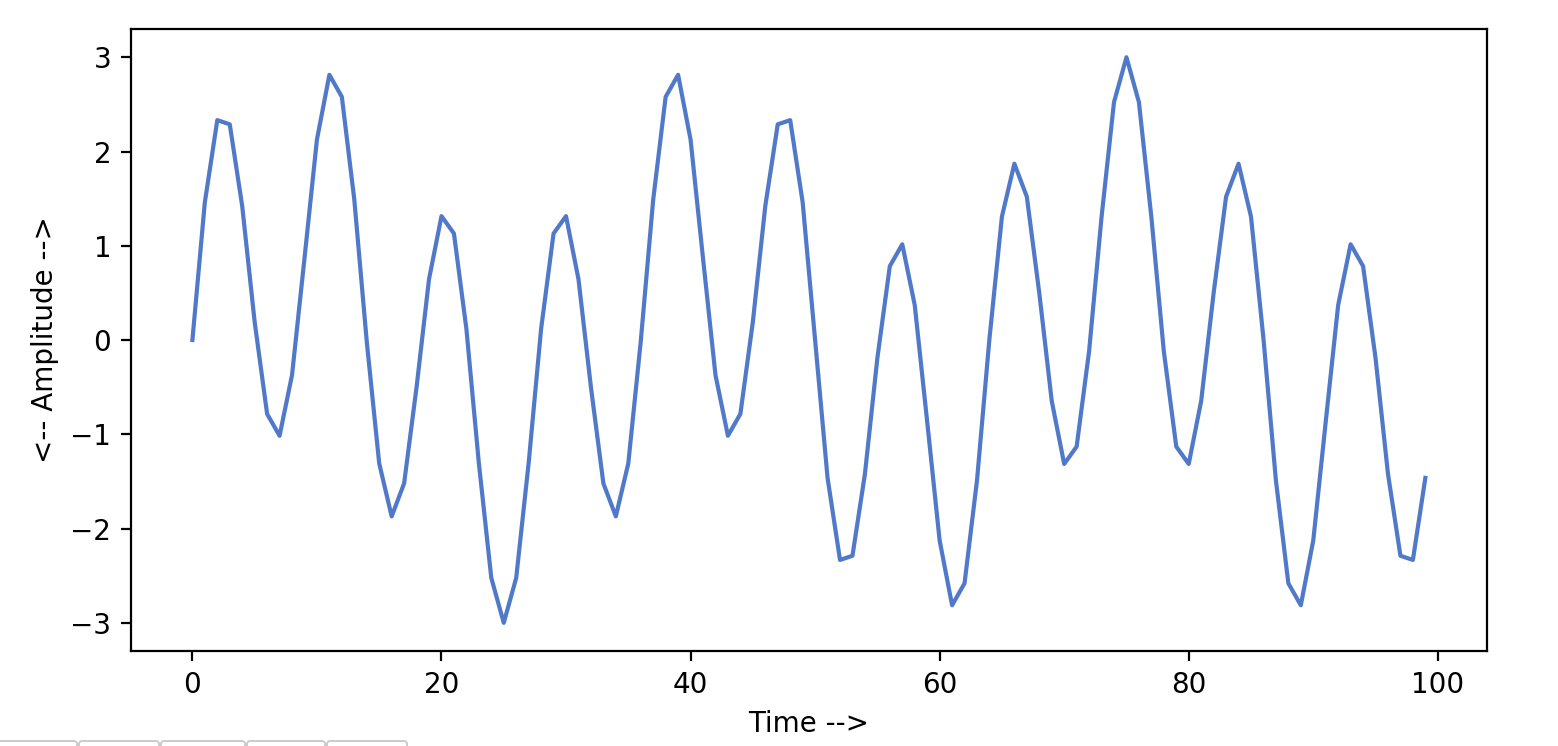
Если мы передадим эту последовательность (y3) нашей функции fft_plot. Он генерирует для нас следующий частотный график. Он показывает два пика для двух частот, присутствующих в нашем результирующем сигнале. Таким образом, наличие одной частоты не влияет на другую частоту в сигнале. Также следует отметить, что величины частот совпадают с нашими сгенерированными синусоидальными волнами.

БПФ на нашем аудиосигнале
Теперь, когда мы увидели, как этот алгоритм БПФ дает нам все частоты в данном сигнале. давайте попробуем передать в эту функцию наш исходный аудиосигнал. Мы используем тот же аудиоклип, который мы ранее загрузили в python, с частотой дискретизации = 16000.

Теперь посмотрите на следующий график частот. Этот 3-секундный сигнал состоит из тысяч различных частот. Амплитуды значений частот ›2000 очень малы, так как большинство этих частот, вероятно, связано с шумом. Мы наносим на график частоты в диапазоне от 0 до 8 кГц, потому что наш сигнал был дискретизирован с частотой дискретизации 16k, и согласно теореме дискретизации Найквиста он должен иметь только частоты ≤ 8000 Гц (16000/2).
Сильные частоты находятся в диапазоне от 0 до 1 кГц только потому, что этот аудиоклип был человеческой речью. Мы знаем, что в типичной человеческой речи этот диапазон частот доминирует.
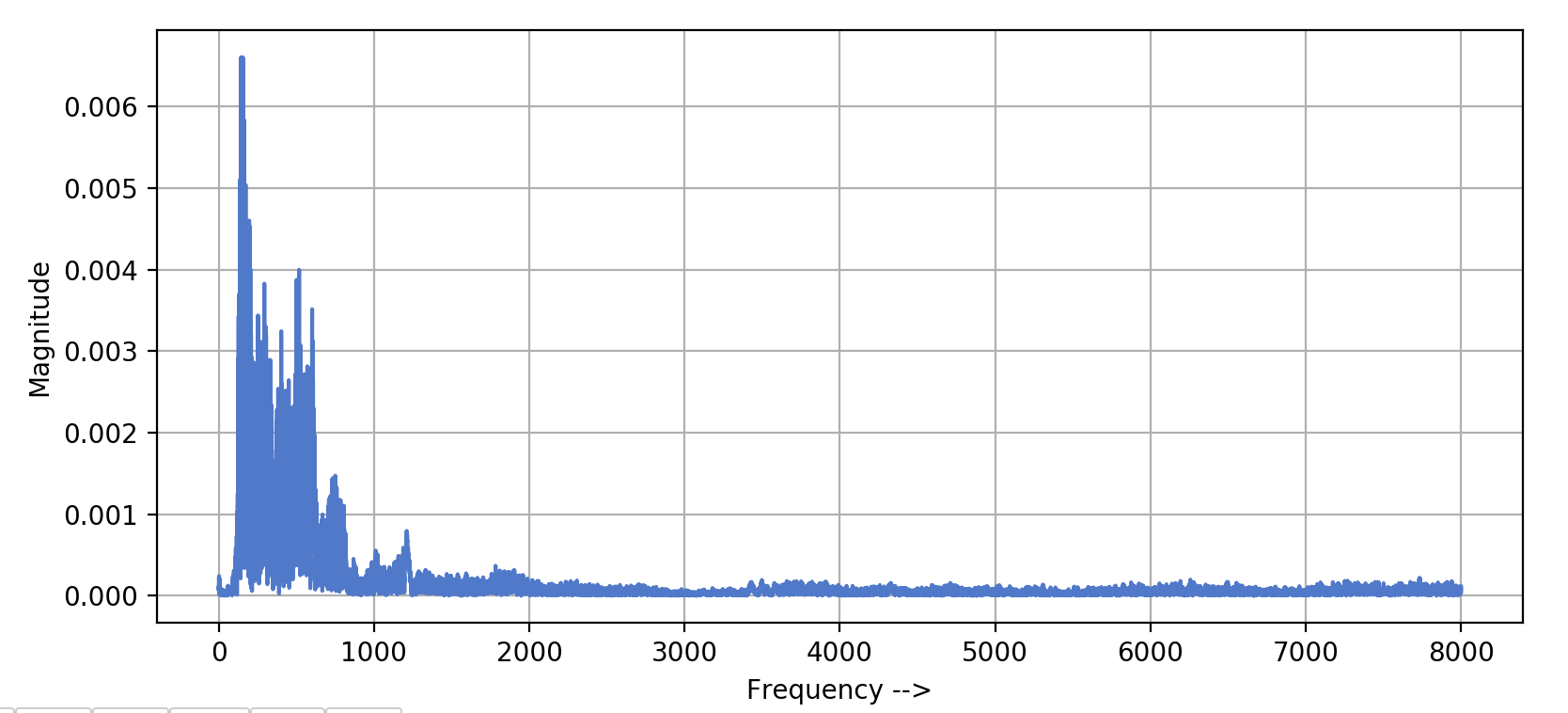
У нас есть частоты. Но где информация о времени?
4. Спектрограмма
почему спектрограмма
Предположим, вы работаете над задачей распознавания речи. У вас есть аудиофайл, в котором кто-то произносит фразу (например: Как дела). Ваша система распознавания должна уметь предсказывать эти три слова в одном и том же порядке (1. как, 2. есть, 3. вы). Если вы помните, в предыдущем упражнении мы разбили наш сигнал на его частотные значения, которые будут использоваться в нашей системе распознавания. Но когда мы применили БПФ к нашему сигналу, он дал нам только значения частоты, и мы потеряли информацию о времени. Теперь наша система не сможет определить, что было сказано первым, если мы будем использовать эти частоты в качестве функций. Нам нужно найти другой способ вычисления характеристик нашей системы, чтобы она имела значения частоты вместе со временем, в которое они наблюдались. Здесь на сцену выходят Спектрограммы.
Визуальное представление частот данного сигнала во времени называется Спектрограммой. На графике представления спектрограммы — одна ось представляет время, вторая ось представляет частоты, а цвета представляют величину (амплитуду) наблюдаемой частоты в конкретный момент времени. На следующем снимке экрана представлена спектрограмма того же звукового сигнала, который мы обсуждали ранее. Яркие цвета представляют сильные частоты. Подобно предыдущему графику БПФ, меньшие частоты в диапазоне (0–1 кГц) являются сильными (яркими).

Создание и построение спектрограммы
Идея состоит в том, чтобы разбить аудиосигнал на более мелкие кадры (окна) и вычислить ДПФ (или БПФ) для каждого окна. Таким образом, мы будем получать частоты для каждого окна, а номер окна будет представлять время. Поскольку окно 1 идет первым, затем окно 2… и так далее. Это хорошая практика, чтобы эти окна перекрывали друг друга, иначе мы можем потерять несколько частот. Размер окна зависит от решаемой проблемы.
Для типичной задачи распознавания речи рекомендуется окно длительностью 20–30 мс. Человек не может произнести более одной фонемы в этом временном окне. Таким образом, если окно будет намного меньше, мы не потеряем никакой фонемы при классификации. Перекрытие фреймов (окон) может варьироваться от 25% до 75% в зависимости от ваших потребностей, как правило, для распознавания речи сохраняется 50%.
В нашем расчете спектрограммы мы будем сохранять длительность окна 20 мс и перекрытие между окнами 50%. Поскольку наш сигнал дискретизируется с частотой 16k, каждое окно будет иметь амплитуду (16000 * 20 * 0,001) = 320. Для перекрытия 50% нам нужно перейти вперед на (320/2) = 160 значений амплитуды, чтобы перейти к следующему окну. Таким образом, наша величина шага равна 160.
Посмотрите на функцию спектрограммы на следующем изображении. В строке 18 мы создаем окно взвешивания (Ханнинга) и умножаем его на амплитуды, прежде чем передать его функции БПФ в строке 20. Окно взвешивания используется здесь для обработки разрыва этого слабого сигнала (слабый сигнал из одного кадра) перед его передачей в алгоритм ДПФ. Чтобы узнать больше о том, почему необходимо окно взвешивания — нажмите здесь.
Функция Python для вычисления функций спектрограммы —
Результатом работы алгоритма БПФ является список комплексных чисел (size = window_size / 2) , которые представляют амплитуды различных частот в пределах окна. Для нашего окна размером 320 мы получим список из 160 амплитуд элементов разрешения по частоте, которые представляют частоты от 0 Гц до 8 кГц (поскольку наша частота дискретизации составляет 16 кГц) в нашем кейс.
В дальнейшем абсолютные значения этих комплексных амплитуд вычисляются и нормализуются. Полученная 2D-матрица и есть ваша спектрограмма. В этой матрице строки и столбцы представляют номер кадра окна и элемент разрешения по частоте, а значения представляют силу частот.
5. Распознавание речи с использованием функций спектрограммы
Теперь мы знаем, как сгенерировать спектрограмму, которая представляет собой двумерную матрицу, представляющую частотные величины вместе со временем для данного сигнала. Теперь представьте себе эту спектрограмму как изображение. Вы преобразовали свой аудиофайл в следующее изображение.

Это сводит его к проблеме классификации изображений. Это изображение представляет вашу произносимую фразу слева направо своевременно. Или рассмотрите это как изображение, на котором ваша фраза написана слева направо, и все, что вам нужно сделать, это идентифицировать эти скрытые английские символы.
Имея параллельный корпус английского текста, мы можем обучить модель глубокого обучения и построить собственную систему распознавания речи. Вот два хорошо известных набора данных с открытым исходным кодом, которые стоит попробовать:
Популярные варианты архитектур глубокого обучения можно понять из следующих хороших исследовательских работ:
-
(исследования Facebook) , Глубокая речь 2 и Глубокая речь 3 (Baidu Research) (Google Brain) (NVIDIA)
6. Заключение
В этой статье показано, как работать со звуковыми данными и несколько методов анализа звука с нуля. Кроме того, он дает отправную точку для создания систем распознавания речи. Хотя вышеприведенное исследование показывает очень многообещающие результаты для систем распознавания, все же многие не считают распознавание речи решенной проблемой из-за следующих ошибок:
- Представленные исследователями модели распознавания речи действительно большие (сложные), что затрудняет их обучение и развертывание.
- Эти системы не работают, когда говорят несколько человек.
- Эти системы плохо работают при плохом качестве звука.
- Они действительно чувствительны к акценту говорящего, поэтому им требуется тренировка для каждого акцента.
В этой области исследований есть огромные возможности. Улучшения могут быть сделаны с точки зрения подготовки данных (путем создания более совершенных функций), а также с точки зрения архитектуры модели (путем представления более надежной и масштабируемой архитектуры глубокого обучения).
Звук — теория, часть 1
Цифровые технологии изо дня в день все больше наполняют окружающий нас мир, и этот процесс со временем только ускоряется. В повседневном обиходе любого из нас уже сегодня присутствует большое число самых различных цифровых устройств, каждое из которых имеет характеристики и свойства, значение которых оказывается не всегда известным и понятным для потребителя. Некоторые из ставших уже абсолютно привычными электронные устройства, равно как и компьютерные программы, остаются для потребителя некими черными ящиками, устройство и принцип действия которых скрыто от глаз.
Потребительская аудио аппаратура, также как и остальная аппаратура — постепенно и уверенно переходящая на цифровые рельсы, становится все сложнее, ее параметры – все запутаннее, а принцип действия – все менее ясным. Эта статья не является универсальным путеводителем в области цифрового звука и цифровой аудио техники, однако в ней мы попытаемся разобраться с основными идеями, а также теоретическими и практическими принципами, лежащими в основе современных цифровых аудио технологий и устройств. Автор статьи надеется, что приведенные в ней сведения окажутся полезными для читателя и явят собой некую основополагающую теоретическую базу, понимание которой просто необходимо всем активным аудио любителям.
2. Физика и психофизика звука
Разговор о звуке мы начнем с рассмотрения простейших физических понятий.
2.1 Физика звуковой волны
Понятие «звук» самым тесным образом связано с понятием «волна». Интересно, что это понятие, являясь привычным для абсолютно всех, у многих вызывает затруднения при попытке дать ему внятное определение. С одной стороны, волна – это что-то, что связано с движением, нечто, распространяющееся в пространстве, как, например, волны, расходящиеся кругами от брошенного в воду камня. С другой стороны, мы знаем, что лежащая на поверхности воды ветка почти не станет двигаться в направлении распространения волн от брошенного рядом камня, а будет в основном лишь колыхаться на воде. Что же переносится в пространстве при распространении волны? Оказывается, в пространстве переносится некоторое возмущение. Брошенный в воду камень вызывает всплеск – изменение состояния поверхности воды, и это возмущение передается от одной точки водоема к другой в виде колебаний поверхности. Таким образом, волна – это процесс перемещения в пространстве изменения состояния.
Звуковая волна (звуковые колебания) – это передающиеся в пространстве механические колебания молекул вещества (например, воздуха). Давайте представим себе, каким образом происходит распространение звуковых волн в пространстве. В результате каких-то возмущений (например, в результате колебаний диффузора громкоговорителя или гитарной струны), вызывающих движение и колебания воздуха в определенной точке пространства, возникает перепад давления в этом месте, так как воздух в процессе движения сжимается, в результате чего возникает избыточное давление, толкающее окружающие слои воздуха. Эти слои сжимаются, что в свою очередь снова создает избыточное давление, влияющее на соседние слои воздуха. Так, как бы по цепочке, происходит передача первоначального возмущения в пространстве из одной точки в другую. Этот процесс описывает механизм распространения в пространстве звуковой волны. Тело, создающее возмущение (колебания) воздуха, называют источником звука.
Привычное для всех нас понятие «звук» означает всего лишь воспринимаемый слуховым аппаратом человека набор звуковых колебаний. О том, какие колебания человек воспринимает, а какие нет, мы поговорим позднее.
Звуковые колебания, а также вообще все колебания, как известно из физики, характеризуются амплитудой (интенсивностью), частотой и фазой. В отношении звуковых колебаний очень важно упомянуть такую характеристику, как скорость распространения. Скорость распространения колебаний, вообще говоря, зависит от среды, в которой колебания распространяются. На эту скорость влияют такие факторы, как упругость среды, ее плотность и температура. Так, например, чем выше температура среды, тем выше в ней скорость звука. В нормальных (при нормальной температуре и давлении) условиях скорость звука в воздухе составляет приблизительно 330 м/с. Таким образом, время, через которое слушатель начинает воспринимать звуковые колебания, зависит от удаленности слушателя от источника звука, а также от характеристик среды, в которой происходит распространение звуковой волны. Немаловажно заметить, что скорость распространения звука почти не зависит от частоты звуковых колебаний. Это означает, среди прочего, что звук воспринимается именно в той последовательности, в какой он создается источником. Если бы это было не так, и звук одной частоты распространялся бы быстрее звука другой частоты, то вместо, например, музыки, мы бы слышали резкий и отрывистый шум.
Звуковым волнам присущи различные явления, связанные с распространением волн в пространстве. Перечислим наиболее важные из них.
Интерференция — усиление колебаний звука в одних точках пространства и ослабление колебаний в других точках в результате наложения двух или нескольких звуковых волн. Когда мы слышим звуки разных, но достаточно близких частот сразу от двух источников, к нам приходят то гребни обеих звуковых волн, то гребень одной волны и впадина другой. В результате наложения двух волн, звук то усиливается, то ослабевает, что воспринимается на слух как биения. Этот эффект называется интерференцией во времени. Конечно, в реальности механизм интерференции оказывается намного более сложным, однако его суть не меняется. Эффект возникновения биений используется при настройке двух музыкальных тонов в унисон (например, при настройке гитары): настройку производят до тех пор, пока биения перестают ощущаться.
Звуковая волна, при ее падении на границу раздела с другой средой, может отразиться от границы раздела, пройти в другую среду, изменить направление движения — преломиться от границы раздела (это явление называют рефракцией), поглотиться или одновременно совершить несколько из перечисленных действий. Степень поглощения и отражения зависит от свойств сред на границе раздела.
Энергия звуковой волны в процессе ее распространения поглощается средой. Этот эффект называют поглощением звуковых волн. Существование эффекта поглощения обусловлено процессами теплообмена и межмолекулярного взаимодействия в среде. Важно отметить, что степень поглощения звуковой энергии зависит как от свойств среды (температура, давление, плотность), так и от частоты звуковых колебаний: чем выше частота звуковых колебаний, тем большее рассеяние претерпевает на своем пути звуковая волна.
Очень важно упомянуть также явление волнового движения в замкнутом объеме, суть которого состоит в отражении звуковых волн от стенок некоторого закрытого пространства. Отражения звуковых колебаний могут сильно влиять на конечное восприятие звука — изменять его окраску, насыщенность, глубину. Так, звук идущий от источника, расположенного в закрытом помещении, многократно ударяясь и отражаясь от стен помещения, воспринимается слушателем как звук, сопровождающийся специфическим гулом. Такой гул называется реверберацией (от лат. « reverbero » — «отбрасываю»). Эффект реверберации очень широко используется в звукообработке с целью придания звучанию специфических свойств и тембральной окраски.
Способность огибать препятствия – еще одно ключевое свойство звуковых волн, называемое в науке дифракцией. Степень огибания зависит от соотношения между длиной звуковой волны (ее частотой) и размером стоящего на ее пути препятствия или отверстия. Если размер препятствия оказывается намного больше длины волны, то звуковая волна отражается от него. Если же размеры препятствия оказываются сопоставимыми с длиной волны или оказываются меньше ее, то звуковая волна дифрагирует.
Еще один эффект, связанный с волновым движением, о котором нельзя не вспомнить — эффект резонанса. Он заключается в следующем. Звуковая волна, создаваемая некоторым колеблющимся телом, распространяясь в пространстве, может переносить энергию колебаний другому телу (резонатору), которое, поглощая эту энергию, начинает колебаться, и, фактически, само становится источником звука. Так исходная звуковая волна усиливается, и звук становится громче. Надо заметить, что в случае появления резонанса, энергия звуковой волны расходуется на «раскачивание» резонатора, что соответственно сказывается на длительности звучания.
Эффект Допплера – еще один интересный, последний в нашем списке эффект, связанный с распространением звуковых волн в пространстве. Эффект заключается в том, что длина волны изменяется соответственно изменению скорости движения слушателя относительно источника волны. Чем быстрее слушатель (регистрирующий датчик) приближается к источнику волны, тем регистрируемая им длина волны становится меньше и наоборот.
Эти и другие явления учитываются и широко используются во многих областях, таких как акустика, звукообработка и радиолокация.
2.2 Звук и формы его представления
Как мы уже выяснили, звук – это слышимые человеком колебания, распространяющиеся в пространстве. Что же представляет собой звук в аудио аппаратуре?
В звуковой аппаратуре звук представляется либо непрерывным электрическим сигналом, либо набором цифр (нулей и единиц). Аппаратура, в которой рабочий сигнал является непрерывным электрическим сигналом, называется аналоговой аппаратурой (например, бытовой радио приемник или стерео усилитель), а сам рабочий сигнал – аналоговым сигналом.
Преобразование звуковых колебаний в аналоговый сигнал можно осуществить, например, следующим способом. Мембрана из тонкого металла с намотанной на нее катушкой индуктивности, подключенная в электрическую цепь и находящаяся в поле действия постоянного магнита, подчиняясь колебаниям воздуха и колеблясь вместе с ним, вызывает соответствующие колебания напряжения в цепи. Эти колебания как бы моделируют оригинальную звуковую волну. Приблизительно так работает привычный для нас микрофон. Полученный в результате такого преобразования аналоговый аудио сигнал может быть записан на магнитную ленту и впоследствии воспроизведен.
Аналоговый сигнал с помощью специального процесса (о нем мы будем говорить позднее) может быть представлен в виде цифрового сигнала – некоторой последовательности чисел. Таким образом, аналоговый звуковой сигнал может быть «введен» в компьютер, обработан цифровыми методами и сохранен на цифровом носителе в виде некоторого набора описывающих его дискретных значений.
Важно понять, что аналоговый или цифровой аудио сигнал – это лишь формы представления звуковых колебаний материи, придуманная человеком для того, чтобы иметь возможность анализировать и обрабатывать звук. Непосредственно аналоговый или цифровой сигнал в его исходном виде не может быть «услышан». Чтобы воссоздать закодированное в цифровых данных звучание, необходимо вызвать соответствующие колебания воздуха, потому что именно эти колебания и есть звук. Это можно сделать лишь путем организации вынужденных колебаний некоторого предмета, расположенного в воздушном пространстве (например, диффузора громкоговорителя). Колебания предмета вызывают колебаниями напряжения в электрической цепи. Эти самые колебания напряжения и есть аналоговый сигнал. Таким образом, чтобы «прослушать» цифровой сигнал, необходимо вернуться от него к аналоговому сигналу. А чтобы «услышать» аналоговый сигнал нужно с его помощью организовать колебания диффузора громкоговорителя.
2.3 Спектр звука
Спектр звукового сигнала (звуковой волны) является одним из важнейших инструментов анализа и обработки звука. Спектральное разложение сигналов – тема обширная и сложная. Мы постараемся раскрыть эту тему, не слишком вдаваясь в ее теоретические подробности.
Французский математик Фурье (1768-1830) и его последователи доказали, что любую, обязательно периодическую функцию, в случае ее соответствия некоторым математическим условиям можно разложить в ряд (сумму) косинусов и синусов с некоторыми коэффициентами, называемый тригонометрическим рядом Фурье. Проводить рассмотрение сухой математики этого метода разложения мы не будем. Скажем лишь, что, по сути, периодическая на интервале [-L,L] функция f( x), задаваемая некоторым аналитическим выражением (пусть даже очень сложным) может быть по-другому записана в форме конечной или бесконечной суммы вида:
где a k, b k – это так называемые коэффициенты Фурье, рассчитывающиеся по некоторой формуле. Иначе говоря, при некоторых условиях, использование ряда Фурье (*) функции f( x) эквивалентно использованию самой функции f( x). То есть, ряд Фурье – это как бы альтернативный способ записи функцию f( x). При этом, не смотря на то, что ряд Фурье может быть бесконечным, предлагаемая им форма записи оказывается очень удобной при проведении анализа и обработки (о том, что это нам дает применительно к звуковым сигналам, мы еще поговорим).
Обратим внимание, что если коэффициенты a k, b k в формуле (*) — это некоторые числа, рассчитывающиеся по специальной формуле, то единственным изменяющимся коэффициентом при x внутри косинусов и синусов является целое число k ( k имеет значения 1, 2, 3 и т.д.). Это означает, что ряд Фурье функции f( x) можно представить графически, отложив по оси абсцисс значение k, а по оси ординат – величины коэффициентов a k и b k (в некоторой форме).
Рассмотрим в качестве примера функцию:
График функции представлен на рис. 1.
Это периодическая функция с периодом 2П. Разложение этой функции в ряд Фурье дает следующий результат:
То есть, коэффициенты a k равны нулю для всех k, а коэффициенты b k не равны нулю только для нечетных k. Этот ряд Фурье можно представить графически в виде графика, как показано на рис. 2.
Так можно поступить с периодическими функциями. Однако, как на практике, так и в теории, далеко не все функции являются периодическими. Чтобы получить возможность раскладывать непериодическую функцию f( x) в ряд Фурье, можно воспользоваться «хитростью». Как правило, при рассмотрении некоторой сложной непериодической функции нас не интересуют ее значения на всей области определения; нам достаточно рассматривать функцию лишь на определенном конечном интервале [ x 1, x 2] для некоторых x 1 и x 2. В этом случае функцию можно рассматривать как периодическую, с периодом T = x 2 – x 1. Для ее разложения в ряд Фурье на интервале [ x 1, x 2] мы можем искусственно представить
, которая может быть разложена в ряд Фурье.
До сих пор мы говорили о математике. Как же все сказанное соотносится с практикой? Действительно, рассмотренный нами способ разложения в ряд Фурье работает для функций, записанных в виде аналитических выражений. К сожалению, на практике записать функцию в виде аналитического выражения возможно лишь в единичных случаях. В реальности чаще всего приходится работать с изменяющимися во времени величинами, никак неподдающимися аналитической записи. Кроме того, значения анализируемой величины чаще всего известны не в любой момент времени, а лишь тогда, когда производится их регистрация (иными словами, значения анализируемой величины дискретны). В частности, интересующие нас сейчас реальные звуковые колебания, являются как раз такой величиной. Оказывается, к таким величинам тоже может быть применена вариация анализа Фурье. Для разложения в ряд Фурье сигналов, описанных их дискретными значениями, применяют Дискретное Преобразование Фурье (ДПФ ) – специально созданная разновидность анализа Фурье. Алгоритм ДПФ был адаптирован для применения в цифровой вычислительной технике и ускорен, в результате чего появился еще один алгоритм, названный Быстрое Преобразование Фурье — БПФ ( Fast Fourier Transform — FFT). БПФ очень широко используется буквально во всех областях науки и техники.
Используя ДПФ/БПФ, звуковой сигнал, описанный его численными значениями, подобно математической функции, может представить в виде спектра входящих в него частот (частотный спектр). Частотные составляющие спектра — это синусоидальные колебания (так называемые чистые тона), каждое из которых имеет свою собственную амплитуду, частоту и фазу. В формуле (*) коэффициенты a k и b k при sin( . ) и cos( . ) показывают амплитуду соответствующей частотной составляющей, а
– ее частоту. Любое, даже самое сложное по форме колебание (например, звук голоса человека), можно представить в виде суммы простейших синусоидальных колебаний определенных частот и амплитуд. На рис. 3 представлен график реальной звуковой волны.
На графике по оси абсцисс откладывается время, а по оси ординат — амплитуда волны (измеренная в децибелах). Спектр этого звукового сигнала представлен в виде графика на рис. 4.
На графике спектра по оси абсцисс откладывается частота спектральных составляющих (измеренная в Гц), а по оси ординат – амплитуда этих спектральных составляющих.
Обратим внимание на один очень важный момент: даже самую сложную зависимость (функцию) спектральное разложение превращает в некоторый математический ряд строго определенного вида (ряд может быть конечным и бесконечным). Таким образом, спектральное разложение как бы преобразует график в график: график функции превращается в график спектра функции. А что, если наша функция – это звуковой сигнал некоторой длительности? Выходит, что в результате спектрального преобразования он тоже превратится в статичную картинку спектра; таким образом, информация о временных изменениях будет утеряна – перед нами будет единый статичный спектр всего сигнала. Как же проследить динамику изменения спектра сигнала во времени?
Чтобы получить представление об изменении спектра во времени, аудио сигнал необходимо анализировать не целиком, а по частям (говорят «блоками» или «окнами»). Например, трехсекундный аудио сигнал можно разбить на 30 блоков. Вычислив спектр для каждого из них, мы сможем проследить динамику развития спектрального состава звучания с разрешением 1/10 секунды. Нужно учитывать, однако, что чем меньше анализируемый блок сигнала, тем менее точен (менее информативен) спектр этого блока. Таким образом, при проведении спектрального анализа мы сталкиваемся с дилеммой, решение которой строго индивидуально для каждого конкретного случая. Стремясь получить высокое временное разрешение, с тем, чтобы суметь распознать изменения спектра сигнала в динамике, мы «дробим» анализируемый сигнал на большое количество блоков, но при этом для каждого получаем огрубленный спектр. И наоборот, стремясь получить как можно более точный и ясный спектр, нам приходится жертвовать временным разрешением и делить сигнал на меньшее количество блоков. Эта дилемма называется принципом неопределенности спектрального анализа.
2.4 Как мы слышим? Психоакустика
Слуховая система человека – сложный и вместе с тем очень интересно устроенный механизм. Чтобы более ясно представить себе, что для нас есть звук, нужно разобраться с тем, что и как мы слышим.
В анатомии ухо человека принято делить на три составные части: наружное ухо, среднее ухо и внутреннее ухо. К наружному уху относится ушная раковина, помогающая сконцентрировать звуковые колебания, и наружный слуховой канал. Звуковая волна, попадая в ушную раковину, проходит дальше, по слуховому каналу (его длина составляет около 3 см, а диаметр — около 0.5) и попадает в среднее ухо, где ударяется о барабанную перепонку, представляющую собой тонкою полупрозрачную мембрану. Барабанная перепонка преобразует звуковую волну в вибрации (усиливая эффект от слабой звуковой волны и ослабляя от сильной). Эти вибрации передаются по присоединенным к барабанной перепонке косточкам — молоточку, наковальне и стремечку – во внутреннее ухо, представляющее собой завитую трубку с жидкостью диаметром около 0.2 мм и длинной около 4 см. Эта трубка называется улиткой. Внутри улитки находится еще одна мембрана, называемая базилярной, которая напоминает струну длиной 32 мм, вдоль которой располагаются чувствительные клетки (более 20 тысяч волокон). Толщина струны в начале улитки и у ее вершины различна. В результате такого строения мембрана резонирует разными своими частями в ответ на звуковые колебания разной высоты. Так, высокочастотный звук затрагивает нервные окончания, располагающиеся в начале улитки, а звуковые колебания низкой частоты – окончания в ее вершине. Механизм распознавания частоты звуковых колебаний достаточно сложен. В целом он заключается в анализе месторасположения затронутых колебаниями нервных окончаний, а также в анализе частоты импульсов, поступающих в мозг от нервных окончаний.
Существует целая наука, изучающая психологические и физиологические особенности восприятия звука человеком. Эта наука называется психоакустикой. В последние несколько десятков лет психоакустика стала одной из наиболее важных отраслей в области звуковых технологий, поскольку в основном именно благодаря знаниям в области психоакустики современные звуковые технологии получили свое развитие. Давайте рассмотрим самые основные факты, установленные психоакустикой.
Основную информацию о звуковых колебаниях мозг получает в области до 4 кГц. Этот факт оказывается вполне логичным, если учесть, что все основные жизненно необходимые человеку звуки находятся именно в этой спектральной полосе, до 4 кГц (голоса других людей и животных, шум воды, ветра и проч.). Частоты выше 4 кГц являются для человека лишь вспомогательными, что подтверждается многими опытами. В целом, принято считать, что низкие частоты «ответственны» за разборчивость, ясность аудио информации, а высокие частоты – за субъективное качество звука. Слуховой аппарат человека способен различать частотные составляющие звука в пределах от 20-30 Гц до приблизительно 20 КГц. Указанная верхняя граница может колебаться в зависимости от возраста слушателя и других факторов.
В спектре звука большинства музыкальных инструментов наблюдается наиболее выделяющаяся по амплитуде частотная составляющая. Ее называют основной частотой или основным тоном. Основная частота является очень важным параметром звучания, и вот почему. Для периодических сигналов, слуховая система человека способна различать высоту звука. В соответствии с определением международной организации стандартов, высота звука — это субъективная характеристика, распределяющая звуки по некоторой шкале от низких к высоким. На воспринимаемую высоту звука влияет, главным образом, частота основного тона (период колебаний), при этом общая форма звуковой волны и ее сложность (форма периода) также могут оказывать влияние на нее. Высота звука может определяться слуховой системой для сложных сигналов, но только в том случае, если основной тон сигнала является периодическим (например, в звуке хлопка или выстрела тон не является периодическим и по сему слух не способен оценить его высоту).
Вообще, в зависимости от амплитуд составляющих спектра, звук может приобретать различную окраску и восприниматься как тон или как шум. В случае если спектр дискретен (то есть, на графике спектра присутствуют явно выраженные пики), то звук воспринимается как тон, если имеет место один пик, или как созвучие, в случае присутствия нескольких явно выраженных пиков. Если же звук имеет сплошной спектр, то есть амплитуды частотных составляющих спектра примерно равны, то на слух такой звук воспринимается как шум. Для демонстрации наглядного примера можно попытаться экспериментально «изготовить» различные музыкальные тона и созвучия. Для этого необходимо к громкоговорителю через сумматор подключить несколько генераторов чистых тонов (осцилляторов). Причем, сделать это таким образом, чтобы была возможность регулировки амплитуды и частоты каждого генерируемого чистого тона. В результате проделанной работы будет получена возможность смешивать сигналы от всех осцилляторов в желаемой пропорции, и тем самым создавать совершенно различные звуки. Поученный прибор явит собой простейший синтезатор звука.
Очень важной характеристикой слуховой системы человека является способность различать два тона с разными частотами. Опытные проверки показали, что в полосе от 0 до 16 кГц человеческий слух способен различать до 620 градаций частот (в зависимости от интенсивности звука), при этом примерно 140 градаций находятся в промежутке от 0 до 500 Гц.
На восприятии высоты звука для чистых тонов сказываются также интенсивность и длительность звучания. В частности, низкий чистый тон покажется еще более низким, если увеличить интенсивность его звучания. Обратная ситуация наблюдается с высокочастотным чистым тоном – увеличение интенсивности звучания сделает субъективно воспринимаемую высоту тона еще более высокой.
Длительность звучания сказывается на воспринимаемой высоте тона критическим образом. Так, очень кратковременное звучание (менее 15 мс) любой частоты покажется на слух просто резким щелчком – слух будет неспособен различить высоту тона для такого сигнала. Высота тона начинает восприниматься лишь спустя 15 мс для частот в полосе 1000 – 2000 Гц и лишь спустя 60 мс – для частот ниже 500 Гц. Это явление называется инерционностью слуха. Инерционность слуха связана с устройством базилярной мембраны. Кратковременные звуковые всплески не способны заставить мембрану резонировать на нужной частоте, а значит мозг не получает информацию о высоте тона очень коротких звуков. Минимальное время, требуемое для распознавания высоты тона, зависит от частоты звукового сигнала, а, точнее, от длины волны. Чем выше частота звука, тем меньше длина звуковой волны, а значит тем быстрее «устанавливаются» колебания базилярной мембраны.
В природе мы почти не сталкиваемся с чистыми тонами. Звучание любого музыкального инструмента является сложным и состоит из множества частотных составляющих. Как мы сказали выше, даже для таких звуков слух способен установить высоту их звучания, в соответствии с частотой основного тона и/или его гармоник. Тем не менее, даже при одинаковой высоте звучания, звук, например, скрипки отличается на слух от звука рояля. Это связано с тем, что помимо высоты звучания слух способен оценить также общий характер, окрас звучания, его тембр. Тембром звука называется такое качество восприятия звука, которое, в не зависимости от частоты и амплитуды, позволяет отличить одно звучание от другого. Тембр звука зависит от общего спектрального состава звучания и интенсивности спектральных составляющих, то есть от общего вида звуковой волны, и фактически не зависит от высоты основного тона. Немалое влияние на тембр звучания оказывает явление инерционности слуховой системы. Это выражается, например, в том, что на распознавание тембра слуху требуется около 200 мс.
Громкость звука – это одно из тех понятий, которые мы употребляем ежедневно, не задумываясь при этом над тем, какой физический смысл оно несет. Громкость звука – это психологическая характеристика восприятия звука, определяющая ощущение силы звука. Громкость звука, хотя и жестко связана с интенсивностью, но нарастает непропорционально увеличению интенсивности звукового сигнала. На громкость влияет частота и длительность звукового сигнала. Чтобы правильно судить о связи ощущения звука (его громкости) с раздражением (уровнем силы звука), нужно учитывать, что изменение чувствительности слухового аппарата человека не точно подчиняется логарифмическому закону.
Существуют несколько единиц измерения громкости звука. Первая единица – «фон» (в англ. обозначении — « phon»). Говорят, «уровень громкости звука составляет n фон», если средний слушатель оценивает сигнал как равный по громкости тону с частотой 1000 Гц и уровнем давления в n дБ. Фон, как и децибел, по сути не является единицей измерения, а представляет собой относительную субъективную характеристику интенсивности звука. На рис. 5 представлен график с кривыми равных громкостей.
Каждая кривая на графике показывает уровень равной громкости с начальной точкой отсчета на частоте 1000 Гц. Иначе говоря, каждая линия соответствует некоторому значению громкости, измеренной в фонах. Например, линия «10 фон» показывает уровни сигнала в дБ на разных частотах, воспринимаемых слушателем как равные по громкости сигналу с частотой 1000 Гц и уровнем 10 дБ. Важно заметить, что приведенные кривые не являются эталонными, а приведены в качестве примера. Современные исследования ясно свидетельствуют, что вид кривых в достаточной степени зависит от условий проведения измерений, акустических характеристик помещения, а также от типа источников звука (громкоговорители, наушники). Таким образом, эталонного графика кривых равных громкостей не существует.
Важной деталью восприятия звука слуховым аппаратом человека является так называемый порог слышимости — минимальная интенсивность звука, с которой начинается восприятие сигнала. Как мы видели, уровни равной громкости звука для человека не остаются постоянным с изменением частоты. Иными словами, чувствительность слуховой системы сильно зависит как от громкости звука, так и от его частоты. В частности, и порог слышимости также не одинаков на разных частотах. Например, порог слышимости сигнала на частоте около 3 кГц составляет чуть менее 0 дБ, а на частоте 200 Гц – около 15 дБ. Напротив, болевой порог слышимости мало зависит от частоты и колеблется в пределах 100 – 130 дБ. График порога слышимости представлен на рис. 6. Обратим внимание, что поскольку, острота слуха с возрастом меняется, график порога слышимости в верхней полосе частот различен для разных возрастов.
Частотные составляющие с амплитудой ниже порога слышимости (то есть находящиеся под графиком порога слышимости) оказываются незаметными на слух.
Интересным и исключительно важным является тот факт, что порог слышимости слуховой системы, также как и кривые равных громкостей, является непостоянным в разных условиях. Представленные выше графики порога слышимости справедливы для тишины. В случае проведения опытов по измерению порога слышимости не в полной тишине, а, например, в зашумленной комнате или при наличии какого-то постоянного фонового звука, графики окажутся другими. Это, в общем, совсем не удивительно. Ведь идя по улице и разговаривая с собеседником, мы вынуждены прерывать свою беседу, когда мимо нас проезжает какой-нибудь грузовик, поскольку шум грузовика не дает нам слышать собеседника. Этот эффект называется частотной маскировкой. Причиной появления эффекта частотной маскировки является схема восприятия звука слуховой системой. Мощный по амплитуде сигнал некоторой частоты f m вызывает сильные возмущения базилярной мембраны на некотором ее отрезке. Близкий по частоте, но более слабый по амплитуде сигнал с частотой f уже не способен повлиять на колебания мембраны, и поэтому остается «незамеченным» нервными окончаниями и мозгом.
Эффект частотной маскировки справедлив для частотных составляющих, присутствующих в спектре сигнала в одно и то же время. Однако в виду инерционности слуха, эффект маскировки может распространяться и во времени. Так некоторая частотная составляющая может маскировать другую частотную составляющую даже тогда, когда они появляются в спектре не одновременно, а с некоторой задержкой во времени. Этот эффект называется временной маскировкой. В случае, когда маскирующий тон появляется по времени раньше маскируемого, эффект называют пост-маскировкой. В случае же, когда маскирующий тон появляется позже маскируемого (возможен и такой случай), эффект называет пре-маскировкой.
2.5. Пространственное звучание.
Человек слышит двумя ушами и за счет этого способен различать направление прихода звуковых сигналов. Эту способность слуховой системы человека называют бинауральным эффектом. Механизм распознавания направления прихода звуков сложен и, надо сказать, что в его изучении и способах применения еще не поставлена точка.
Уши человека расставлены на некотором расстоянии по ширине головы. Скорость распространения звуковой волны относительно невелика. Сигнал, приходящий от источника звука, находящегося напротив слушателя, приходит в оба уха одновременно, и мозг интерпретирует это как расположение источника сигнала либо позади, либо спереди, но не сбоку. Если же сигнал приходит от источника, смещенного относительно центра головы, то звук приходит в одно ухо быстрее, чем во второе, что позволяет мозгу соответствующим образом интерпретировать это как приход сигнала слева или справа и даже приблизительно определить угол прихода. Численно, разница во времени прихода сигнала в левое и правое ухо, составляющая от 0 до 1 мс, смещает мнимый источник звука в сторону того уха, которое воспринимает сигнал раньше. Такой способ определения направления прихода звука используется мозгом в полосе частот от 300 Гц до 1 кГц. Направление прихода звука для частот расположенных выше 1 кГц определяется мозгом человека путем анализа громкости звука. Дело в том, что звуковые волны с частотой выше 1 кГц быстро затухают в воздушном пространстве. Поэтому интенсивность звуковых волн, доходящих до левого и правого ушей слушателя, отличаются на столько, что позволяет мозгу определять направление прихода сигнала по разнице амплитуд. Если звук в одном ухе слышен лучше, чем в другом, следовательно источник звука находится со стороны того уха, в котором он слышен лучше. Немаловажным подспорьем в определении направления прихода звука является способность человека повернуть голову в сторону кажущегося источника звука, чтобы проверить верность определения. Способность мозга определять направление прихода звука по разнице во времени прихода сигнала в левое и правое ухо, а также путем анализа громкости сигнала используется в стереофонии.
Имея всего два источника звука можно создать у слушателя ощущение наличия мнимого источника звука между двумя физическими. Причем этот мнимый источник звука можно «расположить» в любой точке на линии, соединяющей два физических источника. Для этого нужно воспроизвести одну аудио запись (например, со звуком рояля) через оба физических источника, но сделать это с некоторой временной задержкой в одном из них и соответствующей разницей в громкости. Грамотно используя описанный эффект можно при помощи двухканальной аудио записи донести до слушателя почти такую картину звучания, какую он ощутил бы сам, если бы лично присутствовал, например, на каком-нибудь концерте. Такую двухканальную запись называют стереофонической. Одноканальная же запись называется монофонической.
На самом деле, для качественного донесения до слушателя реалистичного пространственного звучания обычной стереофонической записи оказывается не всегда достаточно. Основная причина этого кроется в том, что стерео сигнал, приходящий к слушателю от двух физических источников звука, определяет расположение мнимых источников лишь в той плоскости, в которой расположены реальные физические источники звука. Естественно, «окружить слушателя звуком» при этом не удается. По большому счету по той же причине заблуждением является и мысль о том, что объемное звучание обеспечивается квадрофонической (четырехканальной) системой (два источника перед слушателем и два позади него). В целом, путем выполнения многоканальной записи нам удается лишь донести до слушателя тот звук, каким он был «услышан» расставленной нами звукопринимающей аппаратурой (микрофонами), и не более того. Для воссоздания же более или менее реалистичного, действительно объемного звучания прибегают к применению принципиально других подходов, в основе которых лежат более сложные приемы, моделирующие особенности слуховой системы человека, а также физические особенности и эффекты передачи звуковых сигналов в пространстве.
Одним из таких инструментов является использование функций HRTF (Head Related Transfer Function). Посредством этого метода (по сути – библиотеки функций) звуковой сигнал можно преобразовать специальным образом и обеспечить достаточно реалистичное объемное звучание, рассчитанное на прослушивание даже в наушниках.
Суть HRTF – накопление библиотеки функций, описывающих психофизическую модель восприятия объемности звучания слуховой системой человека. Для создания библиотек HRTF используется искусственный манекен KEMAR (Knowles Electronics Manikin for Auditory Research) или специальное «цифровое ухо». В случае использования манекена суть проводимых измерений состоит в следующем. В уши манекена встраиваются микрофоны, с помощью которых осуществляется запись. Звук воспроизводится источниками, расположенными вокруг манекена. В результате, запись от каждого микрофона представляет собой звук, «прослушанный» соответствующим ухом манекена с учетом всех изменений, которые звук претерпел на пути к уху ( затухания и искажения как следствия огибания головы и отражения от разных ее частей). Расчет функций HRTF производится с учетом исходного звука и звука, «услышанного» манекеном. Собственно, сами опыты заключаются в воспроизведении разных тестовых и реальных звуковых сигналов, их записи с помощью манекена и дальнейшего анализа. Накопленная таким образом база функций позволяет затем обрабатывать любой звук так, что при его воспроизведении через наушники у слушателя создается впечатление, будто звук исходит не из наушников, а откуда-то из окружающего его пространства.
Таким образом, HRTF представляет собой набор трансформаций, которые претерпевает звуковой сигнал на пути от источника звука к слуховой системе человека. Рассчитанные однажды опытным путем, HRTF могут быть применены для обработки звуковых сигналов с целью имитации реальных изменений звука на его пути от источника к слушателю. Не смотря на удачность идеи, HRTF имеет, конечно, и свои отрицательные стороны, однако в целом идея использования HRTF является вполне удачной. Использование HRTF в том или ином виде лежит в основе множества современных технологий пространственного звучания, таких как технологии QSound 3 D ( Q3 D), EAX, Aureal3 D ( A3 D) и другие.